 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWideSeek-R1: Exploring Width Scaling for Broad Information Seeking via Multi-Agent Reinforcement Learning
Feb 04, 2026Recent advancements in Large Language Models (LLMs) have largely focused on depth scaling, where a single agent solves long-horizon problems with multi-turn reasoning and tool use. However, as tasks grow broader, the key bottleneck shifts from individual competence to organizational capability. In this work, we explore a complementary dimension of width scaling with multi-agent systems to address broad information seeking. Existing multi-agent systems often rely on hand-crafted workflows and turn-taking interactions that fail to parallelize work effectively. To bridge this gap, we propose WideSeek-R1, a lead-agent-subagent framework trained via multi-agent reinforcement learning (MARL) to synergize scalable orchestration and parallel execution. By utilizing a shared LLM with isolated contexts and specialized tools, WideSeek-R1 jointly optimizes the lead agent and parallel subagents on a curated dataset of 20k broad information-seeking tasks. Extensive experiments show that WideSeek-R1-4B achieves an item F1 score of 40.0% on the WideSearch benchmark, which is comparable to the performance of single-agent DeepSeek-R1-671B. Furthermore, WideSeek-R1-4B exhibits consistent performance gains as the number of parallel subagents increases, highlighting the effectiveness of width scaling.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025



Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
Locating the boundaries of Pareto fronts: A Many-Objective Evolutionary Algorithm Based on Corner Solution Search
Jun 08, 2018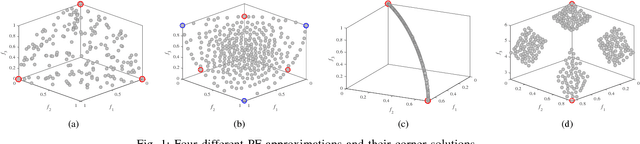
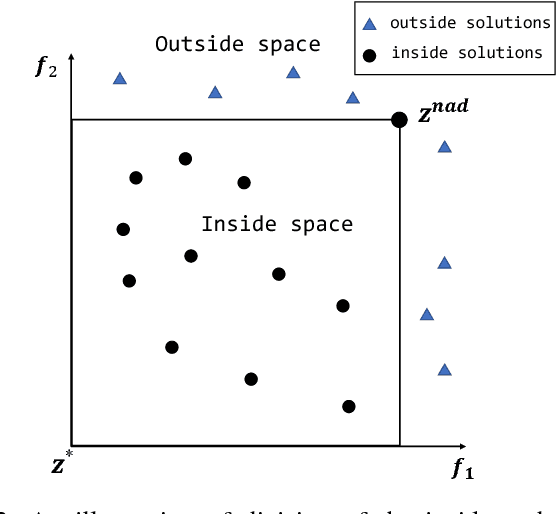
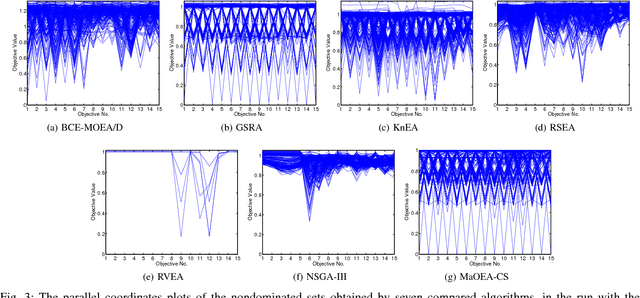
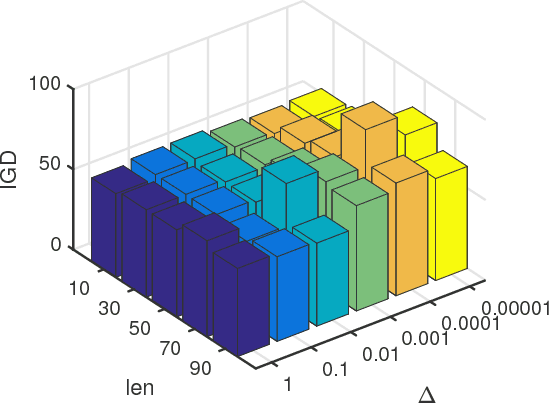
In this paper, an evolutionary many-objective optimization algorithm based on corner solution search (MaOEA-CS) was proposed. MaOEA-CS implicitly contains two phases: the exploitative search for the most important boundary optimal solutions - corner solutions, at the first phase, and the use of angle-based selection [1] with the explorative search for the extension of PF approximation at the second phase. Due to its high efficiency and robustness to the shapes of PFs, it has won the CEC'2017 Competition on Evolutionary Many-Objective Optimization. In addition, MaOEA-CS has also been applied on two real-world engineering optimization problems with very irregular PFs. The experimental results show that MaOEA-CS outperforms other six state-of-the-art compared algorithms, which indicates it has the ability to handle real-world complex optimization problems with irregular PFs.