 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Objectives of Vector-Quantized Tokenizers for Image Synthesis
Paper and Code
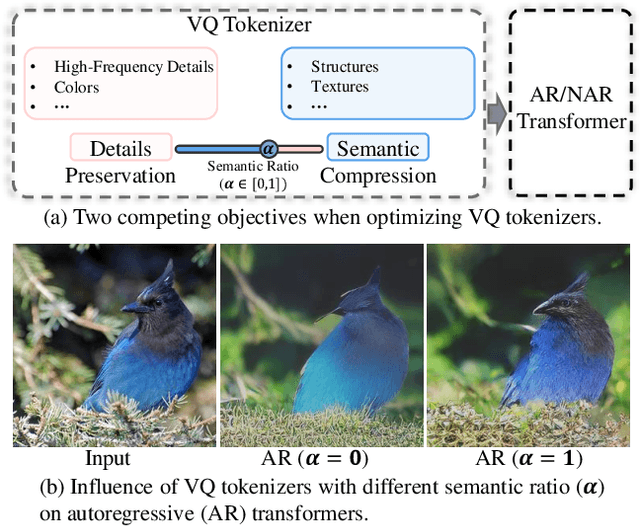
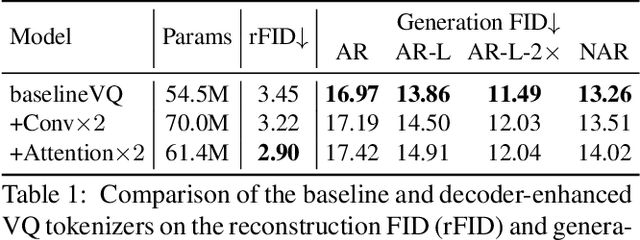

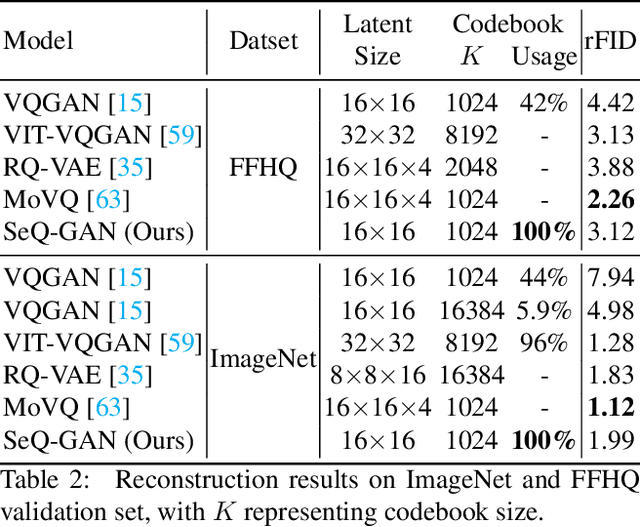
Vector-Quantized (VQ-based) generative models usually consist of two basic components, i.e., VQ tokenizers and generative transformers. Prior research focuses on improving the reconstruction fidelity of VQ tokenizers but rarely examines how the improvement in reconstruction affects the generation ability of generative transformers. In this paper, we surprisingly find that improving the reconstruction fidelity of VQ tokenizers does not necessarily improve the generation. Instead, learning to compress semantic features within VQ tokenizers significantly improves generative transformers' ability to capture textures and structures. We thus highlight two competing objectives of VQ tokenizers for image synthesis: semantic compression and details preservation. Different from previous work that only pursues better details preservation, we propose Semantic-Quantized GAN (SeQ-GAN) with two learning phases to balance the two objectives. In the first phase, we propose a semantic-enhanced perceptual loss for better semantic compression. In the second phase, we fix the encoder and codebook, but enhance and finetune the decoder to achieve better details preservation. The proposed SeQ-GAN greatly improves VQ-based generative models and surpasses the GAN and Diffusion Models on both unconditional and conditional image generation. Our SeQ-GAN (364M) achieves Frechet Inception Distance (FID) of 6.25 and Inception Score (IS) of 140.9 on 256x256 ImageNet generation, a remarkable improvement over VIT-VQGAN (714M), which obtains 11.2 FID and 97.2 IS.