 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Vision-Language Pretraining with Free Language Modeling
Paper and Code
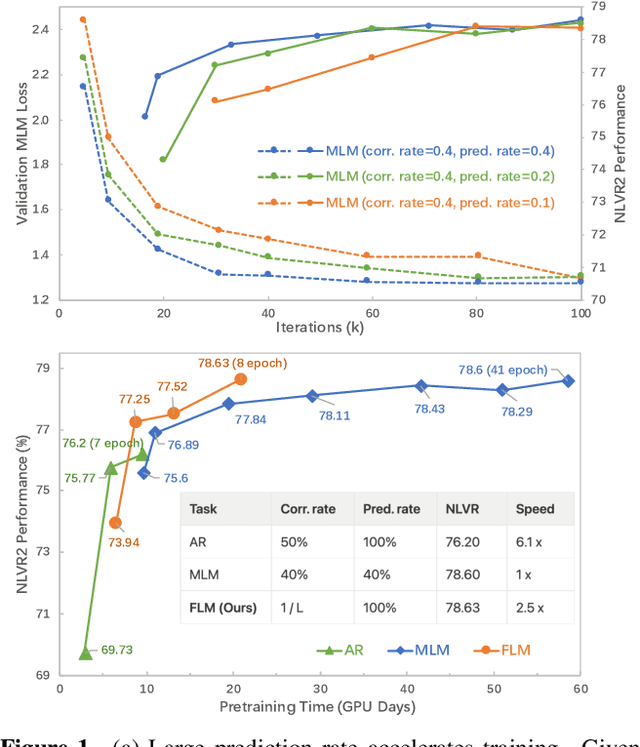
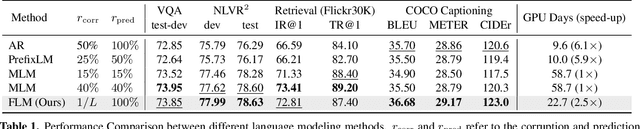
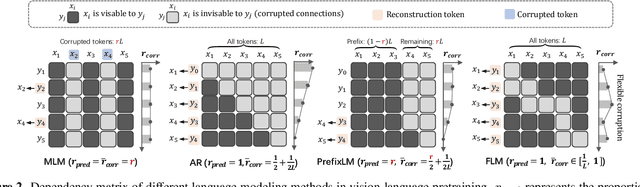
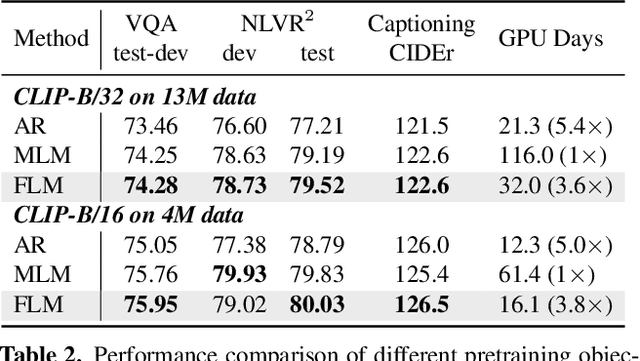
The state of the arts in vision-language pretraining (VLP) achieves exemplary performance but suffers from high training costs resulting from slow convergence and long training time, especially on large-scale web datasets. An essential obstacle to training efficiency lies in the entangled prediction rate (percentage of tokens for reconstruction) and corruption rate (percentage of corrupted tokens) in masked language modeling (MLM), that is, a proper corruption rate is achieved at the cost of a large portion of output tokens being excluded from prediction loss. To accelerate the convergence of VLP, we propose a new pretraining task, namely, free language modeling (FLM), that enables a 100% prediction rate with arbitrary corruption rates. FLM successfully frees the prediction rate from the tie-up with the corruption rate while allowing the corruption spans to be customized for each token to be predicted. FLM-trained models are encouraged to learn better and faster given the same GPU time by exploiting bidirectional contexts more flexibly. Extensive experiments show FLM could achieve an impressive 2.5x pretraining time reduction in comparison to the MLM-based methods, while keeping competitive performance on both vision-language understanding and generation tasks. Code will be public at https://github.com/TencentARC/FLM.