 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-supervised Action Localization via Hierarchical Mining
Paper and Code
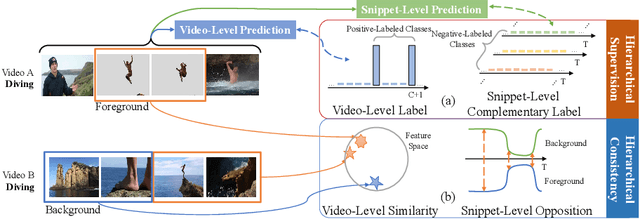
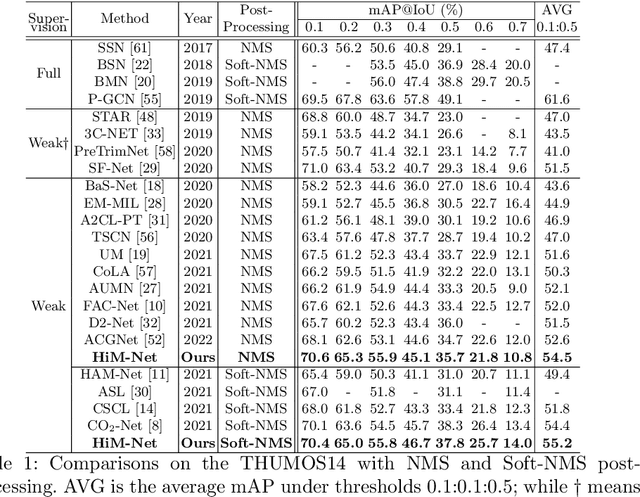
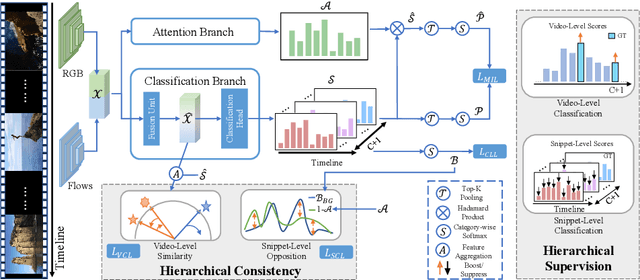
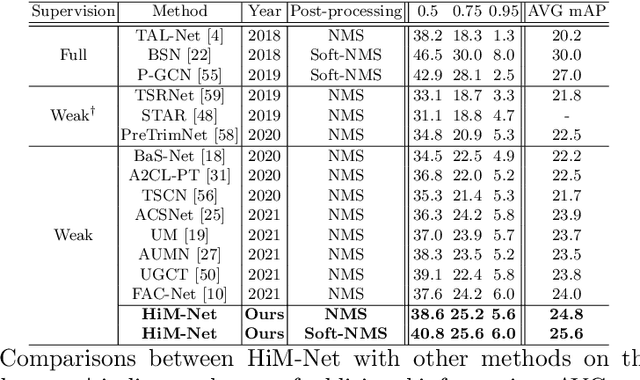
Weakly-supervised action localization aims to localize and classify action instances in the given videos temporally with only video-level categorical labels. Thus, the crucial issue of existing weakly-supervised action localization methods is the limited supervision from the weak annotations for precise predictions. In this work, we propose a hierarchical mining strategy under video-level and snippet-level manners, i.e., hierarchical supervision and hierarchical consistency mining, to maximize the usage of the given annotations and prediction-wise consistency. To this end, a Hierarchical Mining Network (HiM-Net) is proposed. Concretely, it mines hierarchical supervision for classification in two grains: one is the video-level existence for ground truth categories captured by multiple instance learning; the other is the snippet-level inexistence for each negative-labeled category from the perspective of complementary labels, which is optimized by our proposed complementary label learning. As for hierarchical consistency, HiM-Net explores video-level co-action feature similarity and snippet-level foreground-background opposition, for discriminative representation learning and consistent foreground-background separation. Specifically, prediction variance is viewed as uncertainty to select the pairs with high consensus for proposed foreground-background collaborative learning. Comprehensive experimental results show that HiM-Net outperforms existing methods on THUMOS14 and ActivityNet1.3 datasets with large margins by hierarchically mining the supervision and consistency. Code will be available on GitHub.