 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Layer Reinforcement Learning-Assisted Joint Beamforming and Trajectory Optimization for Multi-UAV Downlink Communications
Jan 19, 2026Unmanned aerial vehicles (UAVs) are pivotal for future 6G non-terrestrial networks, yet their high mobility creates a complex coupled optimization problem for beamforming and trajectory design. Existing numerical methods suffer from prohibitive latency, while standard deep learning often ignores dynamic interference topology, limiting scalability. To address these issues, this paper proposes a hierarchically decoupled framework synergizing graph neural networks (GNNs) with multi-agent reinforcement learning. Specifically, on the short timescale, we develop a topology-aware GNN beamformer by incorporating GraphNorm. By modeling the dynamic UAV-user association as a time-varying heterogeneous graph, this method explicitly extracts interference patterns to achieve sub-millisecond inference. On the long timescale, trajectory planning is modeled as a decentralized partially observable Markov decision process and solved via the multi-agent proximal policy optimization algorithm under the centralized training with decentralized execution paradigm, facilitating cooperative behaviors. Extensive simulation results demonstrate that the proposed framework significantly outperforms state-of-the-art optimization heuristics and deep learning baselines in terms of system sum rate, convergence speed, and generalization capability.
Analogical Learning for Cross-Scenario Generalization: Framework and Application to Intelligent Localization
Apr 09, 2025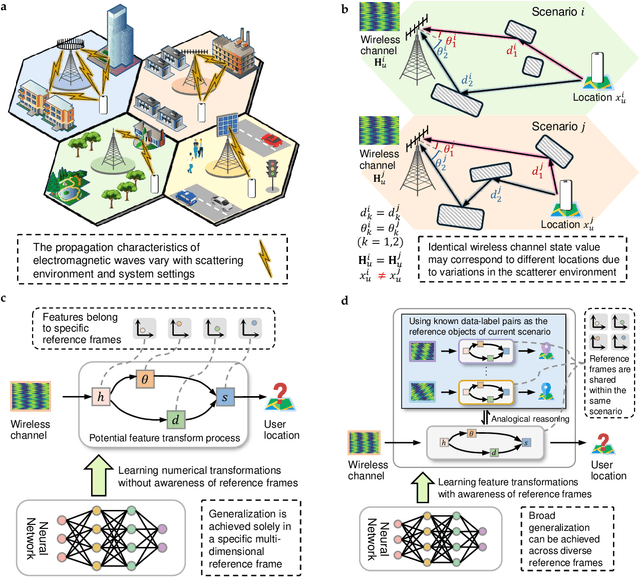
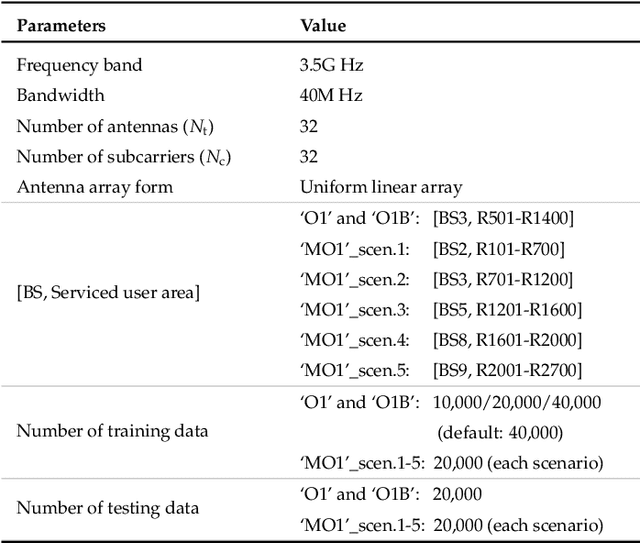
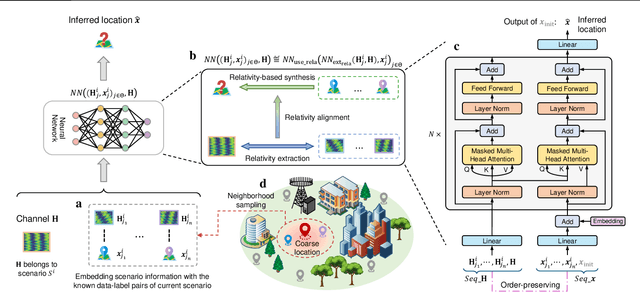

Existing learning models often exhibit poor generalization when deployed across diverse scenarios. It is mainly due to that the underlying reference frame of the data varies with the deployment environment and settings. However, despite the data of each scenario has its distinct reference frame, its generation generally follows the same underlying physical rule. Based on these findings, this article proposes a brand-new universal deep learning framework named analogical learning (AL), which provides a highly efficient way to implicitly retrieve the reference frame information associated with a scenario and then to make accurate prediction by relative analogy across scenarios. Specifically, an elegant bipartite neural network architecture called Mateformer is designed, the first part of which calculates the relativity within multiple feature spaces between the input data and a small amount of embedded data from the current scenario, while the second part uses these relativity to guide the nonlinear analogy. We apply AL to the typical multi-scenario learning problem of intelligent wireless localization in cellular networks. Extensive experiments show that AL achieves state-of-the-art accuracy, stable transferability and robust adaptation to new scenarios without any tuning, and outperforming conventional methods with a precision improvement of nearly two orders of magnitude. All data and code are available at https://github.com/ziruichen-research/ALLoc.
Over-the-Air Split Learning with MIMO-Based Neural Network and Constellation-Based Activation
Oct 08, 2022


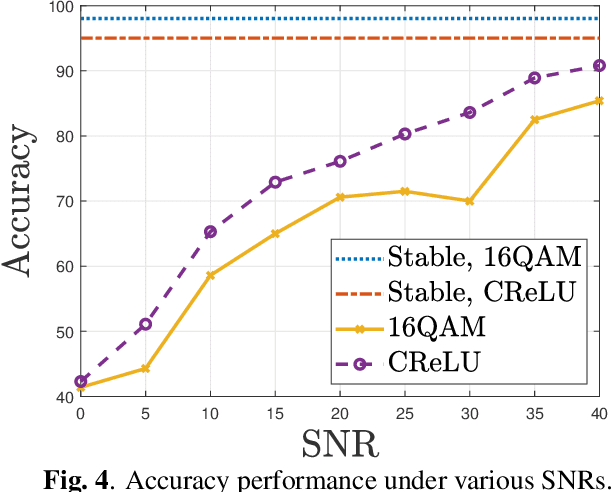
This paper investigates a communication-efficient split learning (SL) over multiple-input multiple-output (MIMO) communication system. In particular, we mathematically decompose the inter-layer connection of a neural network (NN) to a series of linear precoding and combining transformations using over-the-air computation (OAC), which synergistically form a linear layer in NNs. The precoding and combining matrices are trainable parameters in such a system, whereas the MIMO channel is implicit. The proposed system eliminates the implicit channel estimation through exploiting the channel reciprocity and properly casting the backpropagation process, significantly saving the system costs and further improving the overall efficiency. The practical constellation diagrams are used as the activation function to avoid sending arbitrary analog signals as in the traditional OAC system. Numerical results are illustrated to demonstrate the effectiveness of the proposed scheme.
Over-the-Air Split Machine Learning in Wireless MIMO Networks
Oct 07, 2022
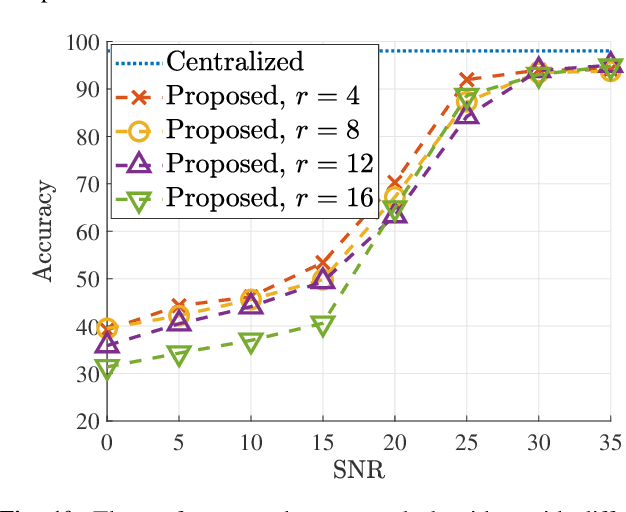

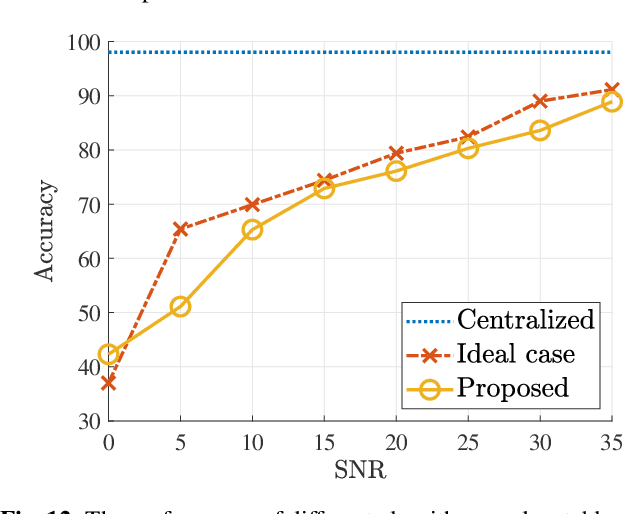
In split machine learning (ML), different partitions of a neural network (NN) are executed by different computing nodes, requiring a large amount of communication cost. To ease communication burden, over-the-air computation (OAC) can efficiently implement all or part of the computation at the same time of communication. Based on the proposed system, the system implementation over wireless network is introduced and we provide the problem formulation. In particular, we show that the inter-layer connection in a NN of any size can be mathematically decomposed into a set of linear precoding and combining transformations over MIMO channels. Therefore, the precoding matrix at the transmitter and the combining matrix at the receiver of each MIMO link, as well as the channel matrix itself, can jointly serve as a fully connected layer of the NN. The generalization of the proposed scheme to the conventional NNs is also introduced. Finally, we extend the proposed scheme to the widely used convolutional neural networks and demonstrate its effectiveness under both the static and quasi-static memory channel conditions with comprehensive simulations. In such a split ML system, the precoding and combining matrices are regarded as trainable parameters, while MIMO channel matrix is regarded as unknown (implicit) parameters.
Communication-Efficient Federated Learning with Binary Neural Networks
Oct 05, 2021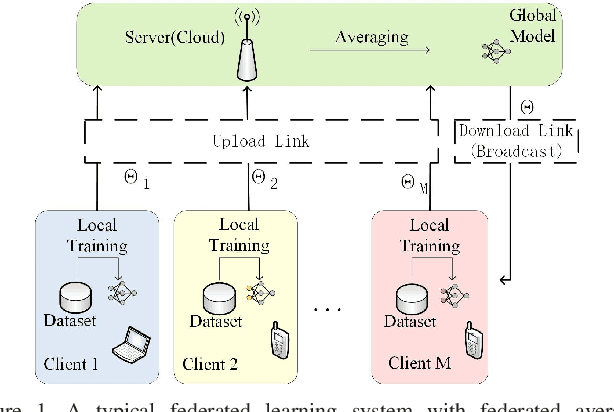

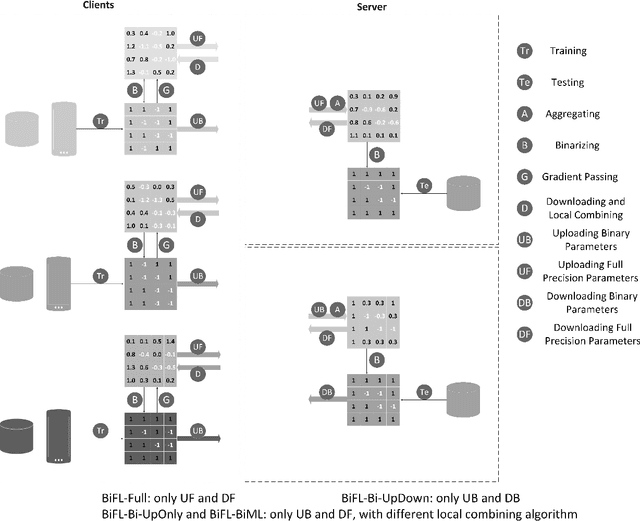

Federated learning (FL) is a privacy-preserving machine learning setting that enables many devices to jointly train a shared global model without the need to reveal their data to a central server. However, FL involves a frequent exchange of the parameters between all the clients and the server that coordinates the training. This introduces extensive communication overhead, which can be a major bottleneck in FL with limited communication links. In this paper, we consider training the binary neural networks (BNN) in the FL setting instead of the typical real-valued neural networks to fulfill the stringent delay and efficiency requirement in wireless edge networks. We introduce a novel FL framework of training BNN, where the clients only upload the binary parameters to the server. We also propose a novel parameter updating scheme based on the Maximum Likelihood (ML) estimation that preserves the performance of the BNN even without the availability of aggregated real-valued auxiliary parameters that are usually needed during the training of the BNN. Moreover, for the first time in the literature, we theoretically derive the conditions under which the training of BNN is converging. { Numerical results show that the proposed FL framework significantly reduces the communication cost compared to the conventional neural networks with typical real-valued parameters, and the performance loss incurred by the binarization can be further compensated by a hybrid method.