 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOver-the-Air Split Machine Learning in Wireless MIMO Networks
Oct 07, 2022
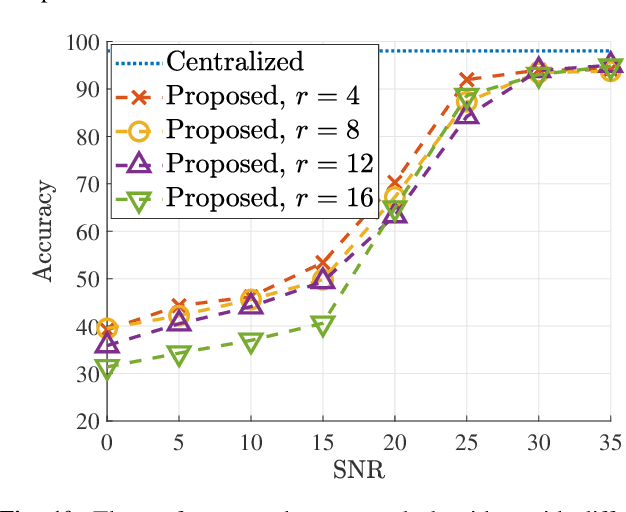

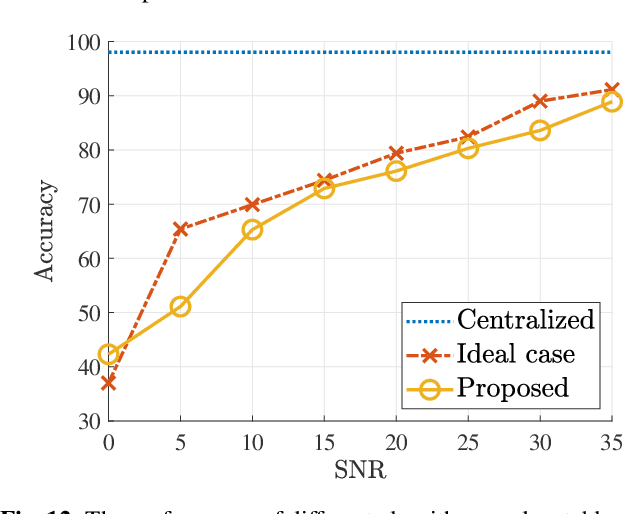
In split machine learning (ML), different partitions of a neural network (NN) are executed by different computing nodes, requiring a large amount of communication cost. To ease communication burden, over-the-air computation (OAC) can efficiently implement all or part of the computation at the same time of communication. Based on the proposed system, the system implementation over wireless network is introduced and we provide the problem formulation. In particular, we show that the inter-layer connection in a NN of any size can be mathematically decomposed into a set of linear precoding and combining transformations over MIMO channels. Therefore, the precoding matrix at the transmitter and the combining matrix at the receiver of each MIMO link, as well as the channel matrix itself, can jointly serve as a fully connected layer of the NN. The generalization of the proposed scheme to the conventional NNs is also introduced. Finally, we extend the proposed scheme to the widely used convolutional neural networks and demonstrate its effectiveness under both the static and quasi-static memory channel conditions with comprehensive simulations. In such a split ML system, the precoding and combining matrices are regarded as trainable parameters, while MIMO channel matrix is regarded as unknown (implicit) parameters.
JMSNAS: Joint Model Split and Neural Architecture Search for Learning over Mobile Edge Networks
Nov 16, 2021
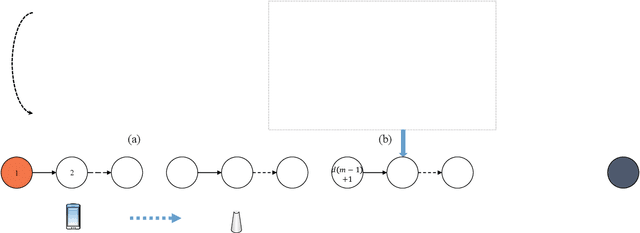
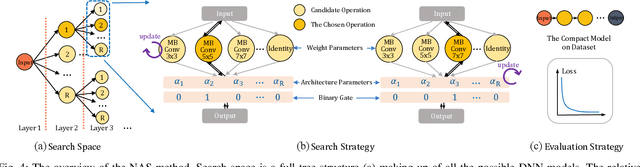

The main challenge to deploy deep neural network (DNN) over a mobile edge network is how to split the DNN model so as to match the network architecture as well as all the nodes' computation and communication capacity. This essentially involves two highly coupled procedures: model generating and model splitting. In this paper, a joint model split and neural architecture search (JMSNAS) framework is proposed to automatically generate and deploy a DNN model over a mobile edge network. Considering both the computing and communication resource constraints, a computational graph search problem is formulated to find the multi-split points of the DNN model, and then the model is trained to meet some accuracy requirements. Moreover, the trade-off between model accuracy and completion latency is achieved through the proper design of the objective function. The experiment results confirm the superiority of the proposed framework over the state-of-the-art split machine learning design methods.