 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Heterogeneity in Federated Multimodal Learning with Biomedical Vision-Language Pre-training
Paper and Code
Apr 05, 2024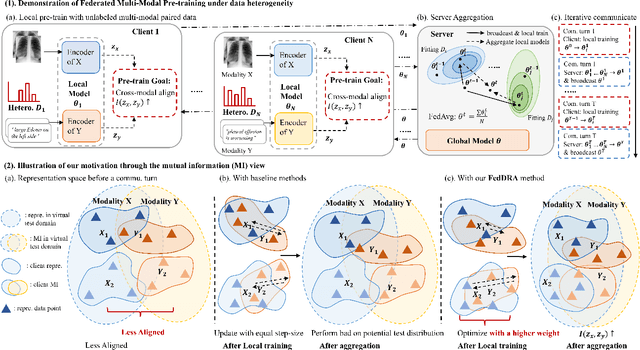

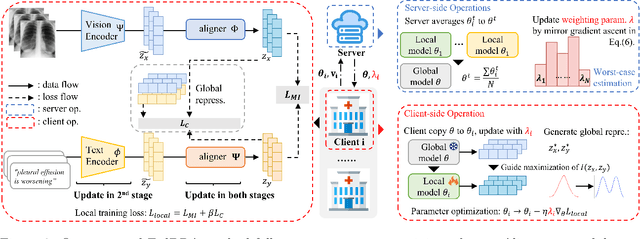
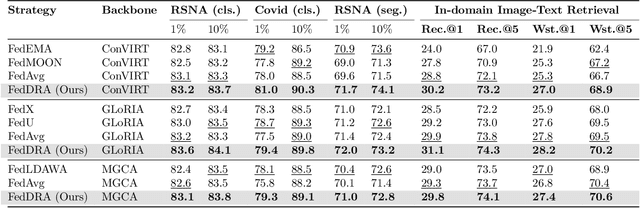
Vision-language pre-training (VLP) has arised as an efficient scheme for multimodal representation learning, but it requires large-scale multimodal data for pre-training, making it an obstacle especially for biomedical applications. To overcome the data limitation, federated learning (FL) can be a promising strategy to scale up the dataset for biomedical VLP while protecting data privacy. However, client data are often heterogeneous in real-world scenarios, and we observe that local training on heterogeneous client data would distort the multimodal representation learning and lead to biased cross-modal alignment. To address this challenge, we propose Federated distributional Robust Guidance-Based (FedRGB) learning framework for federated VLP with robustness to data heterogeneity. Specifically, we utilize a guidance-based local training scheme to reduce feature distortions, and employ a distribution-based min-max optimization to learn unbiased cross-modal alignment. The experiments on real-world datasets show our method successfully promotes efficient federated multimodal learning for biomedical VLP with data heterogeneity.