 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixing Vector Model for Copolymer Inference via Mixed Integer Linear Programming
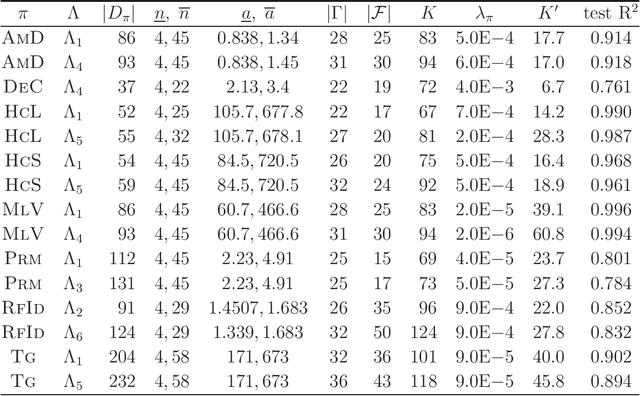
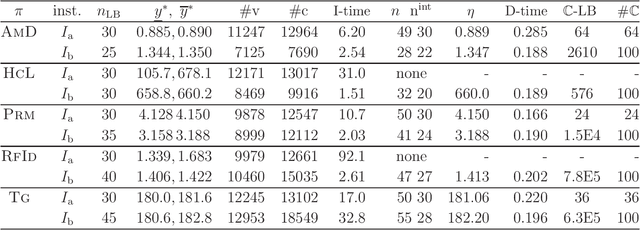
May 28, 2026A novel two-phase molecule inference framework, mol-infer, has recently been developed to infer chemical graphs with prescribed abstract structures and desired property values through mixed integer linear programming (MILP) under the two-layered model, with guaranteed optimality and exactness relative to the given learned prediction function and structural constraints. In this study, we extend this framework to copolymers by introducing a simple feature representation, called the mixing vector (MV) model. In the proposed model, a copolymer feature vector is represented as a convex combination of MILP-tractable monomer descriptors weighted by the mixing ratio of the constituent monomers. This representation does not require explicit sequence-class information and is therefore naturally compatible with MILP-based inverse design. Under this model, we construct prediction functions for several copolymer property datasets using artificial neural networks, reduced quadratic multiple linear regression, and random forests. The proposed representation achieves practically useful predictive performance across multiple physicochemical property datasets; in particular, the best test R^2 score exceeds 0.7 for nine of the ten datasets and exceeds 0.9 for six datasets. We also formulate a multi-monomer inverse-design problem under the MV representation with a prescribed mixing ratio and show that the resulting MILP instances remain tractable, even for three-monomer settings. Finally, we perform an external consistency check by re-evaluating the inferred candidates and comparing the re-computed property values with those predicted by the learned model. Overall, the proposed framework gives a tractable first step toward model-level exact inverse design of copolymers under the two-layered model.
ReLU Networks for Exact Generation of Similar Graphs
Apr 07, 2026Generation of graphs constrained by a specified graph edit distance from a source graph is important in applications such as cheminformatics, network anomaly synthesis, and structured data augmentation. Despite the growing demand for such constrained generative models in areas including molecule design and network perturbation analysis, the neural architectures required to provably generate graphs within a bounded graph edit distance remain largely unexplored. In addition, existing graph generative models are predominantly data-driven and depend heavily on the availability and quality of training data, which may result in generated graphs that do not satisfy the desired edit distance constraints. In this paper, we address these challenges by theoretically characterizing ReLU neural networks capable of generating graphs within a prescribed graph edit distance from a given graph. In particular, we show the existence of constant depth and O(n^2 d) size ReLU networks that deterministically generate graphs within edit distance d from a given input graph with n vertices, eliminating reliance on training data while guaranteeing validity of the generated graphs. Experimental evaluations demonstrate that the proposed network successfully generates valid graphs for instances with up to 1400 vertices and edit distance bounds up to 140, whereas baseline generative models fail to generate graphs with the desired edit distance. These results provide a theoretical foundation for constructing compact generative models with guaranteed validity.
A Unified Approach to Inferring Chemical Compounds with the Desired Aqueous Solubility
Sep 06, 2024



Aqueous solubility (AS) is a key physiochemical property that plays a crucial role in drug discovery and material design. We report a novel unified approach to predict and infer chemical compounds with the desired AS based on simple deterministic graph-theoretic descriptors, multiple linear regression (MLR) and mixed integer linear programming (MILP). Selected descriptors based on a forward stepwise procedure enabled the simplest regression model, MLR, to achieve significantly good prediction accuracy compared to the existing approaches, achieving the accuracy in the range [0.7191, 0.9377] for 29 diverse datasets. By simulating these descriptors and learning models as MILPs, we inferred mathematically exact and optimal compounds with the desired AS, prescribed structures, and up to 50 non-hydrogen atoms in a reasonable time range [6, 1204] seconds. These findings indicate a strong correlation between the simple graph-theoretic descriptors and the AS of compounds, potentially leading to a deeper understanding of their AS without relying on widely used complicated chemical descriptors and complex machine learning models that are computationally expensive, and therefore difficult to use for inference. An implementation of the proposed approach is available at https://github.com/ku-dml/mol-infer/tree/master/AqSol.
Cycle-Configuration: A Novel Graph-theoretic Descriptor Set for Molecular Inference
Aug 09, 2024In this paper, we propose a novel family of descriptors of chemical graphs, named cycle-configuration (CC), that can be used in the standard "two-layered (2L) model" of mol-infer, a molecular inference framework based on mixed integer linear programming (MILP) and machine learning (ML). Proposed descriptors capture the notion of ortho/meta/para patterns that appear in aromatic rings, which has been impossible in the framework so far. Computational experiments show that, when the new descriptors are supplied, we can construct prediction functions of similar or better performance for all of the 27 tested chemical properties. We also provide an MILP formulation that asks for a chemical graph with desired properties under the 2L model with CC descriptors (2L+CC model). We show that a chemical graph with up to 50 non-hydrogen vertices can be inferred in a practical time.
On the Trade-off between the Number of Nodes and the Number of Trees in a Random Forest
Dec 16, 2023In this paper, we focus on the prediction phase of a random forest and study the problem of representing a bag of decision trees using a smaller bag of decision trees, where we only consider binary decision problems on the binary domain and simple decision trees in which an internal node is limited to querying the Boolean value of a single variable. As a main result, we show that the majority function of $n$ variables can be represented by a bag of $T$ ($< n$) decision trees each with polynomial size if $n-T$ is a constant, where $n$ and $T$ must be odd (in order to avoid the tie break). We also show that a bag of $n$ decision trees can be represented by a bag of $T$ decision trees each with polynomial size if $n-T$ is a constant and a small classification error is allowed. A related result on the $k$-out-of-$n$ functions is presented too.
Molecular Design Based on Integer Programming and Splitting Data Sets by Hyperplanes
Apr 27, 2023
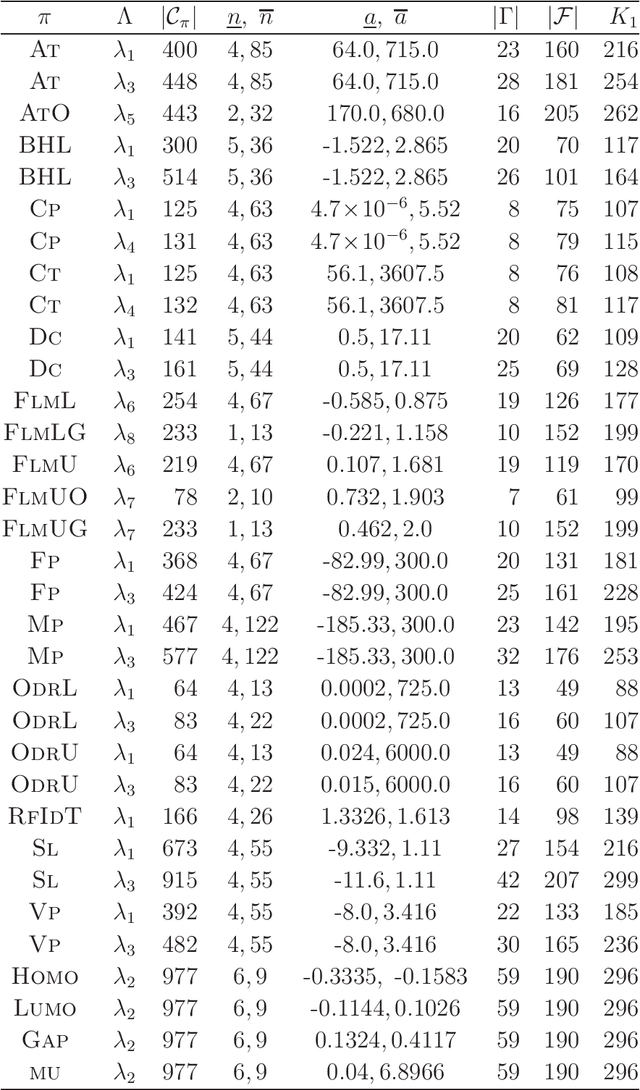

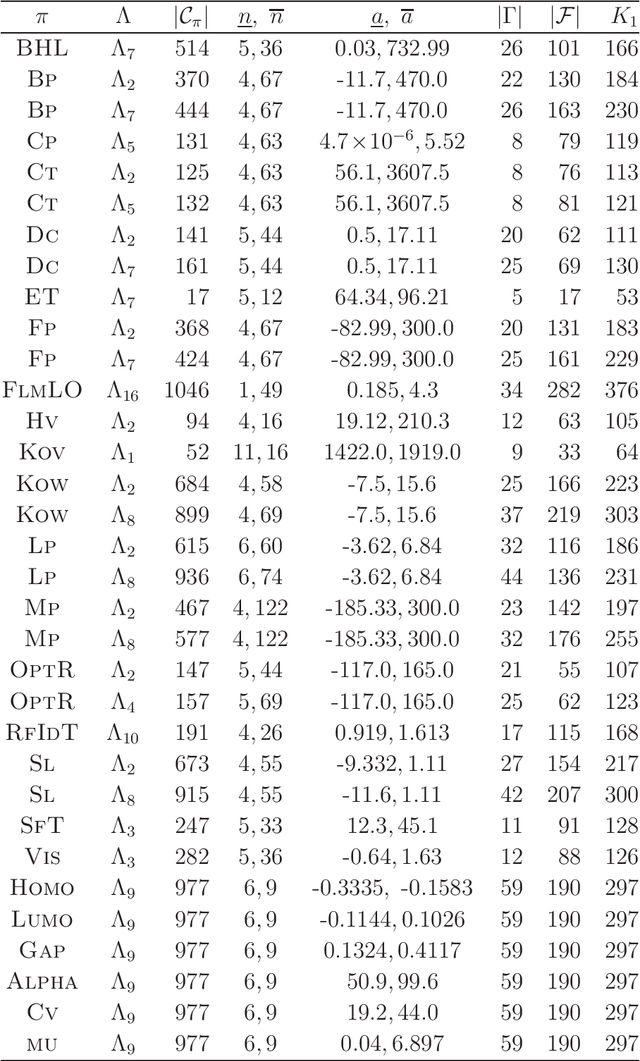
A novel framework for designing the molecular structure of chemical compounds with a desired chemical property has recently been proposed. The framework infers a desired chemical graph by solving a mixed integer linear program (MILP) that simulates the computation process of a feature function defined by a two-layered model on chemical graphs and a prediction function constructed by a machine learning method. To improve the learning performance of prediction functions in the framework, we design a method that splits a given data set $\mathcal{C}$ into two subsets $\mathcal{C}^{(i)},i=1,2$ by a hyperplane in a chemical space so that most compounds in the first (resp., second) subset have observed values lower (resp., higher) than a threshold $\theta$. We construct a prediction function $\psi$ to the data set $\mathcal{C}$ by combining prediction functions $\psi_i,i=1,2$ each of which is constructed on $\mathcal{C}^{(i)}$ independently. The results of our computational experiments suggest that the proposed method improved the learning performance for several chemical properties to which a good prediction function has been difficult to construct.
Molecular Design Based on Integer Programming and Quadratic Descriptors in a Two-layered Model
Sep 13, 2022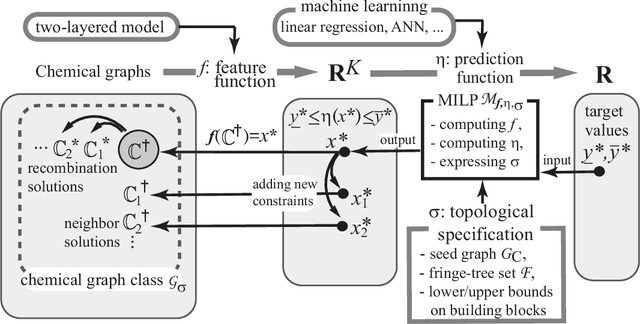
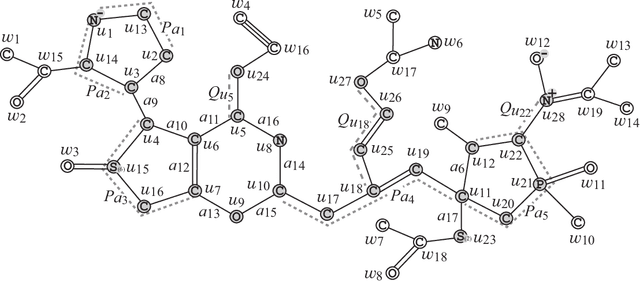
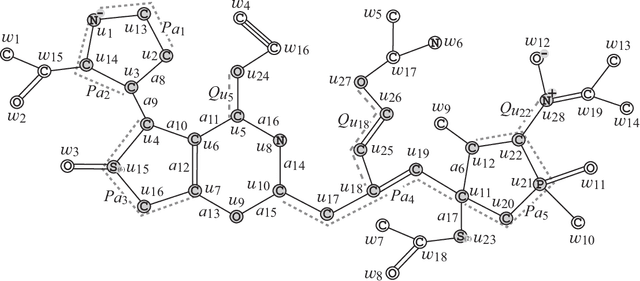
A novel framework has recently been proposed for designing the molecular structure of chemical compounds with a desired chemical property, where design of novel drugs is an important topic in bioinformatics and chemo-informatics. The framework infers a desired chemical graph by solving a mixed integer linear program (MILP) that simulates the computation process of a feature function defined by a two-layered model on chemical graphs and a prediction function constructed by a machine learning method. A set of graph theoretical descriptors in the feature function plays a key role to derive a compact formulation of such an MILP. To improve the learning performance of prediction functions in the framework maintaining the compactness of the MILP, this paper utilizes the product of two of those descriptors as a new descriptor and then designs a method of reducing the number of descriptors. The results of our computational experiments suggest that the proposed method improved the learning performance for many chemical properties and can infer a chemical structure with up to 50 non-hydrogen atoms.
On the Size and Width of the Decoder of a Boolean Threshold Autoencoder
Dec 21, 2021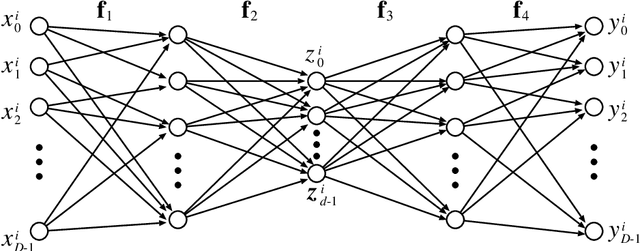
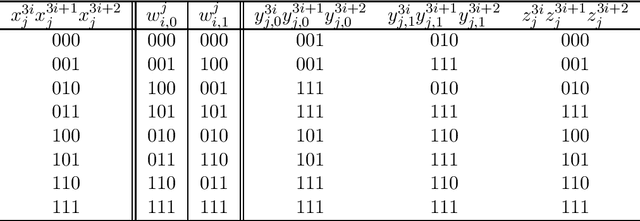

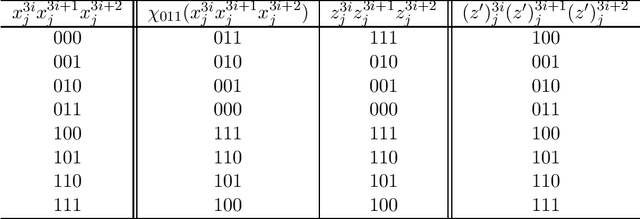
In this paper, we study the size and width of autoencoders consisting of Boolean threshold functions, where an autoencoder is a layered neural network whose structure can be viewed as consisting of an encoder, which compresses an input vector to a lower dimensional vector, and a decoder which transforms the low-dimensional vector back to the original input vector exactly (or approximately). We focus on the decoder part, and show that $\Omega(\sqrt{Dn/d})$ and $O(\sqrt{Dn})$ nodes are required to transform $n$ vectors in $d$-dimensional binary space to $D$-dimensional binary space. We also show that the width can be reduced if we allow small errors, where the error is defined as the average of the Hamming distance between each vector input to the encoder part and the resulting vector output by the decoder.
A Method for Inferring Polymers Based on Linear Regression and Integer Programming
Aug 24, 2021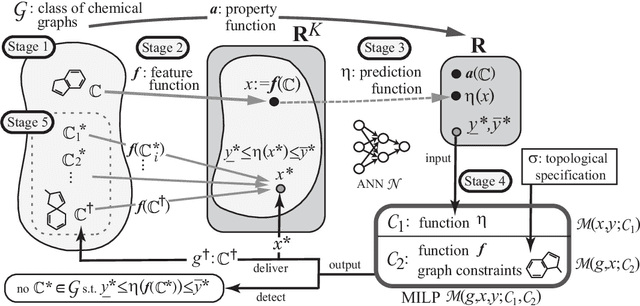

A novel framework has recently been proposed for designing the molecular structure of chemical compounds with a desired chemical property using both artificial neural networks and mixed integer linear programming. In this paper, we design a new method for inferring a polymer based on the framework. For this, we introduce a new way of representing a polymer as a form of monomer and define new descriptors that feature the structure of polymers. We also use linear regression as a building block of constructing a prediction function in the framework. The results of our computational experiments reveal a set of chemical properties on polymers to which a prediction function constructed with linear regression performs well. We also observe that the proposed method can infer polymers with up to 50 non-hydrogen atoms in a monomer form.
Molecular Design Based on Artificial Neural Networks, Integer Programming and Grid Neighbor Search
Aug 23, 2021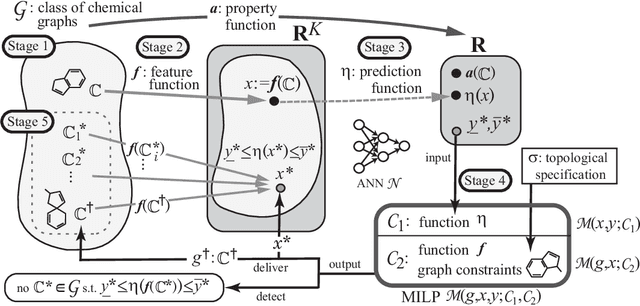
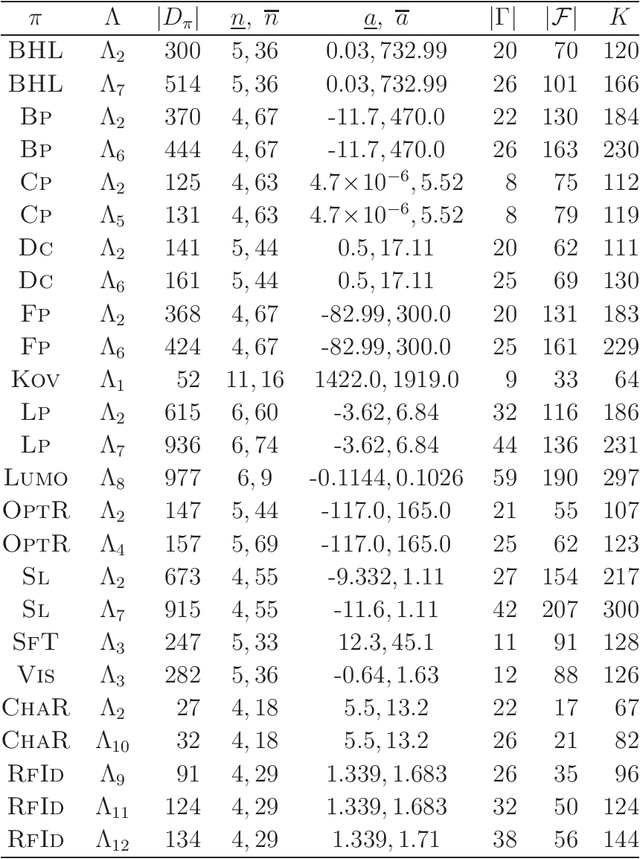
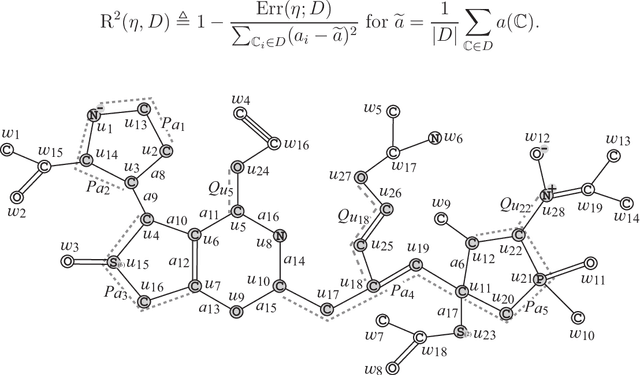
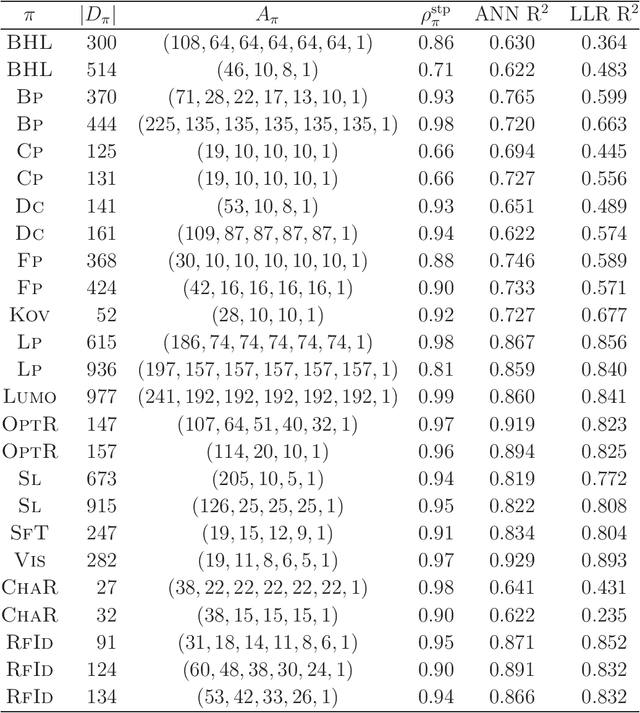
A novel framework has recently been proposed for designing the molecular structure of chemical compounds with a desired chemical property using both artificial neural networks and mixed integer linear programming. In the framework, a chemical graph with a target chemical value is inferred as a feasible solution of a mixed integer linear program that represents a prediction function and other requirements on the structure of graphs. In this paper, we propose a procedure for generating other feasible solutions of the mixed integer linear program by searching the neighbor of output chemical graph in a search space. The procedure is combined in the framework as a new building block. The results of our computational experiments suggest that the proposed method can generate an additional number of new chemical graphs with up to 50 non-hydrogen atoms.