 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEIL: A General Classification-Enhanced Iterative Learning Framework for Text Clustering
Apr 20, 2023
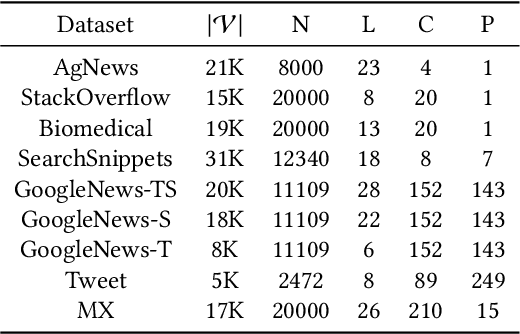

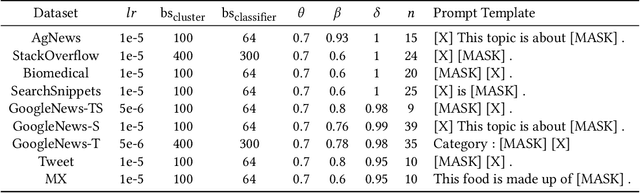
Text clustering, as one of the most fundamental challenges in unsupervised learning, aims at grouping semantically similar text segments without relying on human annotations. With the rapid development of deep learning, deep clustering has achieved significant advantages over traditional clustering methods. Despite the effectiveness, most existing deep text clustering methods rely heavily on representations pre-trained in general domains, which may not be the most suitable solution for clustering in specific target domains. To address this issue, we propose CEIL, a novel Classification-Enhanced Iterative Learning framework for short text clustering, which aims at generally promoting the clustering performance by introducing a classification objective to iteratively improve feature representations. In each iteration, we first adopt a language model to retrieve the initial text representations, from which the clustering results are collected using our proposed Category Disentangled Contrastive Clustering (CDCC) algorithm. After strict data filtering and aggregation processes, samples with clean category labels are retrieved, which serve as supervision information to update the language model with the classification objective via a prompt learning approach. Finally, the updated language model with improved representation ability is used to enhance clustering in the next iteration. Extensive experiments demonstrate that the CEIL framework significantly improves the clustering performance over iterations, and is generally effective on various clustering algorithms. Moreover, by incorporating CEIL on CDCC, we achieve the state-of-the-art clustering performance on a wide range of short text clustering benchmarks outperforming other strong baseline methods.