 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossmodal Knowledge Distillation with WordNet-Relaxed Text Embeddings for Robust Image Classification
Paper and Code
Mar 31, 2025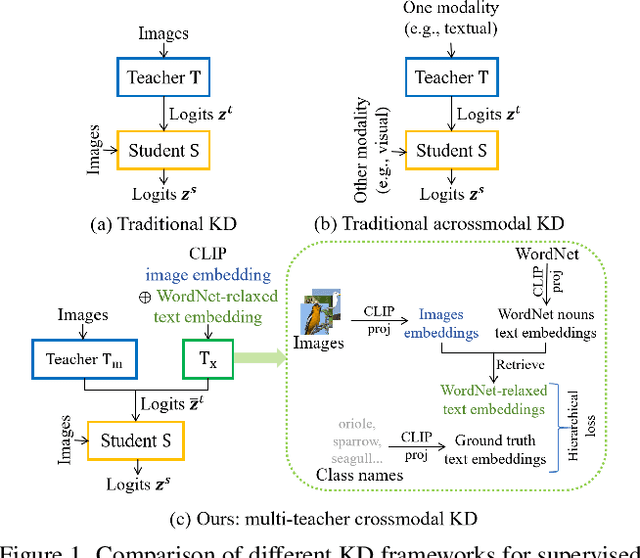
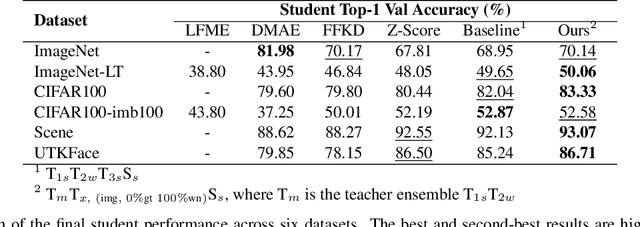
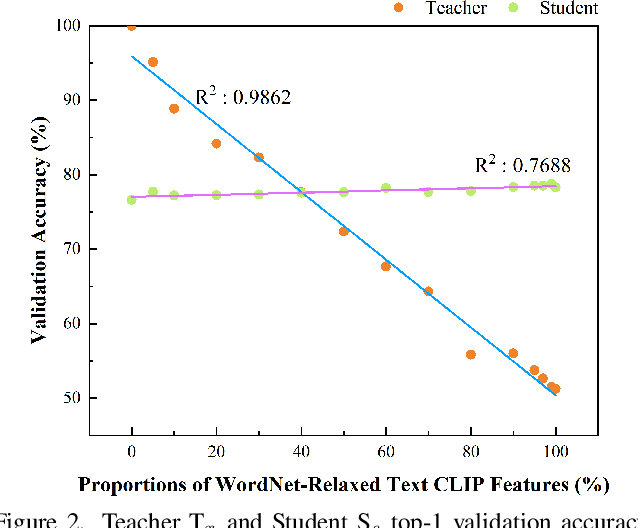
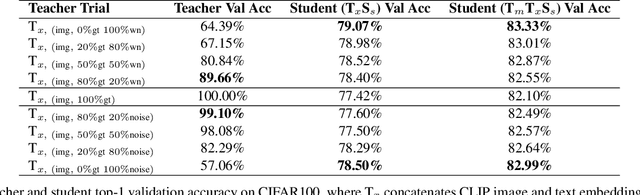
Crossmodal knowledge distillation (KD) aims to enhance a unimodal student using a multimodal teacher model. In particular, when the teacher's modalities include the student's, additional complementary information can be exploited to improve knowledge transfer. In supervised image classification, image datasets typically include class labels that represent high-level concepts, suggesting a natural avenue to incorporate textual cues for crossmodal KD. However, these labels rarely capture the deeper semantic structures in real-world visuals and can lead to label leakage if used directly as inputs, ultimately limiting KD performance. To address these issues, we propose a multi-teacher crossmodal KD framework that integrates CLIP image embeddings with learnable WordNet-relaxed text embeddings under a hierarchical loss. By avoiding direct use of exact class names and instead using semantically richer WordNet expansions, we mitigate label leakage and introduce more diverse textual cues. Experiments show that this strategy significantly boosts student performance, whereas noisy or overly precise text embeddings hinder distillation efficiency. Interpretability analyses confirm that WordNet-relaxed prompts encourage heavier reliance on visual features over textual shortcuts, while still effectively incorporating the newly introduced textual cues. Our method achieves state-of-the-art or second-best results on six public datasets, demonstrating its effectiveness in advancing crossmodal KD.