 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRehearsal with Auxiliary-Informed Sampling for Audio Deepfake Detection
May 30, 2025The performance of existing audio deepfake detection frameworks degrades when confronted with new deepfake attacks. Rehearsal-based continual learning (CL), which updates models using a limited set of old data samples, helps preserve prior knowledge while incorporating new information. However, existing rehearsal techniques don't effectively capture the diversity of audio characteristics, introducing bias and increasing the risk of forgetting. To address this challenge, we propose Rehearsal with Auxiliary-Informed Sampling (RAIS), a rehearsal-based CL approach for audio deepfake detection. RAIS employs a label generation network to produce auxiliary labels, guiding diverse sample selection for the memory buffer. Extensive experiments show RAIS outperforms state-of-the-art methods, achieving an average Equal Error Rate (EER) of 1.953 % across five experiences. The code is available at: https://github.com/falihgoz/RAIS.
Vision Graph Non-Contrastive Learning for Audio Deepfake Detection with Limited Labels
Jan 09, 2025



Recent advancements in audio deepfake detection have leveraged graph neural networks (GNNs) to model frequency and temporal interdependencies in audio data, effectively identifying deepfake artifacts. However, the reliance of GNN-based methods on substantial labeled data for graph construction and robust performance limits their applicability in scenarios with limited labeled data. Although vast amounts of audio data exist, the process of labeling samples as genuine or fake remains labor-intensive and costly. To address this challenge, we propose SIGNL (Spatio-temporal vIsion Graph Non-contrastive Learning), a novel framework that maintains high GNN performance in low-label settings. SIGNL constructs spatio-temporal graphs by representing patches from the audio's visual spectrogram as nodes. These graph structures are modeled using vision graph convolutional (GC) encoders pre-trained through graph non-contrastive learning, a label-free that maximizes the similarity between positive pairs. The pre-trained encoders are then fine-tuned for audio deepfake detection, reducing reliance on labeled data. Experiments demonstrate that SIGNL outperforms state-of-the-art baselines across multiple audio deepfake detection datasets, achieving the lowest Equal Error Rate (EER) with as little as 5% labeled data. Additionally, SIGNL exhibits strong cross-domain generalization, achieving the lowest EER in evaluations involving diverse attack types and languages in the In-The-Wild dataset.
Entropy Causal Graphs for Multivariate Time Series Anomaly Detection
Dec 15, 2023
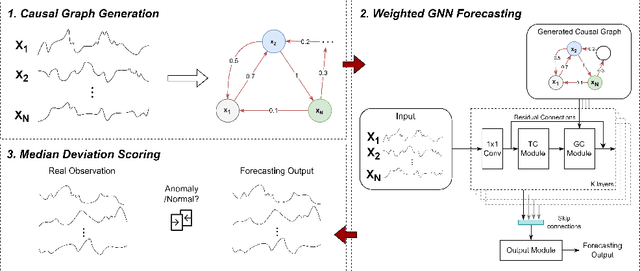


Many multivariate time series anomaly detection frameworks have been proposed and widely applied. However, most of these frameworks do not consider intrinsic relationships between variables in multivariate time series data, thus ignoring the causal relationship among variables and degrading anomaly detection performance. This work proposes a novel framework called CGAD, an entropy Causal Graph for multivariate time series Anomaly Detection. CGAD utilizes transfer entropy to construct graph structures that unveil the underlying causal relationships among time series data. Weighted graph convolutional networks combined with causal convolutions are employed to model both the causal graph structures and the temporal patterns within multivariate time series data. Furthermore, CGAD applies anomaly scoring, leveraging median absolute deviation-based normalization to improve the robustness of the anomaly identification process. Extensive experiments demonstrate that CGAD outperforms state-of-the-art methods on real-world datasets with a 15% average improvement based on three different multivariate time series anomaly detection metrics.
A Comprehensive Survey on Outlying Aspect Mining Methods
May 27, 2020
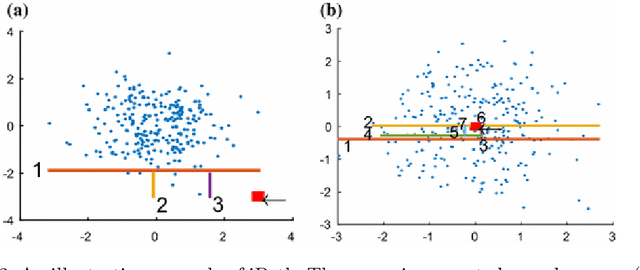

In recent years, researchers have become increasingly interested in outlying aspect mining. Outlying aspect mining is the task of finding a set of feature(s), where a given data object is different from the rest of the data objects. Remarkably few studies have been designed to address the problem of outlying aspect mining; therefore, little is known about outlying aspect mining approaches and their strengths and weaknesses among researchers. In this work, we have grouped existing outlying aspect mining approaches in three different categories. For each category, we have provided existing work that falls in that category and then provided their strengths and weaknesses in those categories. We also offer time complexity comparison of the current techniques since it is a crucial issue in the real-world scenario. The motive behind this paper is to give a better understanding of the existing outlying aspect mining techniques and how these techniques have been developed.
An Efficient Approach to Learning Chinese Judgment Document Similarity Based on Knowledge Summarization
Aug 06, 2018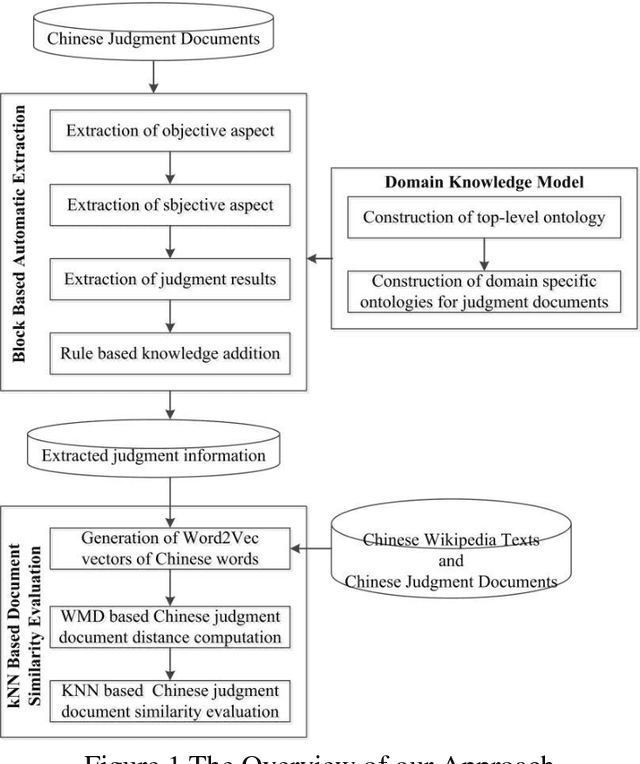



A previous similar case in common law systems can be used as a reference with respect to the current case such that identical situations can be treated similarly in every case. However, current approaches for judgment document similarity computation failed to capture the core semantics of judgment documents and therefore suffer from lower accuracy and higher computation complexity. In this paper, a knowledge block summarization based machine learning approach is proposed to compute the semantic similarity of Chinese judgment documents. By utilizing domain ontologies for judgment documents, the core semantics of Chinese judgment documents is summarized based on knowledge blocks. Then the WMD algorithm is used to calculate the similarity between knowledge blocks. At last, the related experiments were made to illustrate that our approach is very effective and efficient in achieving higher accuracy and faster computation speed in comparison with the traditional approaches.
Supervised Anomaly Detection in Uncertain Pseudoperiodic Data Streams
Jul 20, 2016
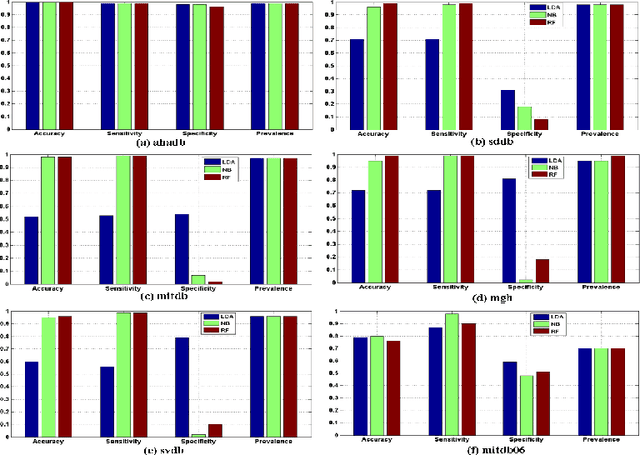
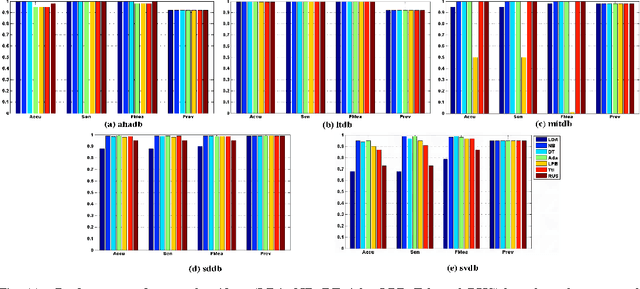
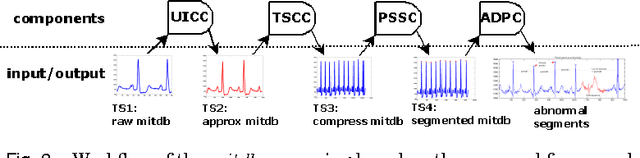
Uncertain data streams have been widely generated in many Web applications. The uncertainty in data streams makes anomaly detection from sensor data streams far more challenging. In this paper, we present a novel framework that supports anomaly detection in uncertain data streams. The proposed framework adopts an efficient uncertainty pre-processing procedure to identify and eliminate uncertainties in data streams. Based on the corrected data streams, we develop effective period pattern recognition and feature extraction techniques to improve the computational efficiency. We use classification methods for anomaly detection in the corrected data stream. We also empirically show that the proposed approach shows a high accuracy of anomaly detection on a number of real datasets.
Refining Adverse Drug Reactions using Association Rule Mining for Electronic Healthcare Data
Feb 20, 2015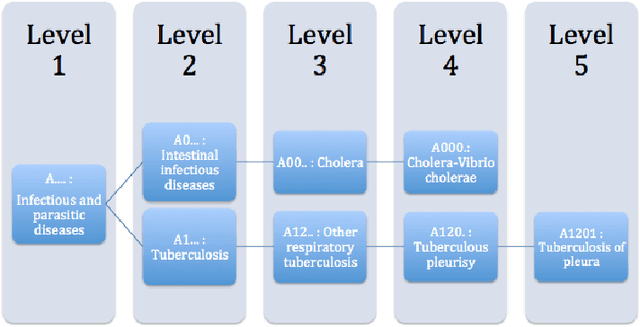
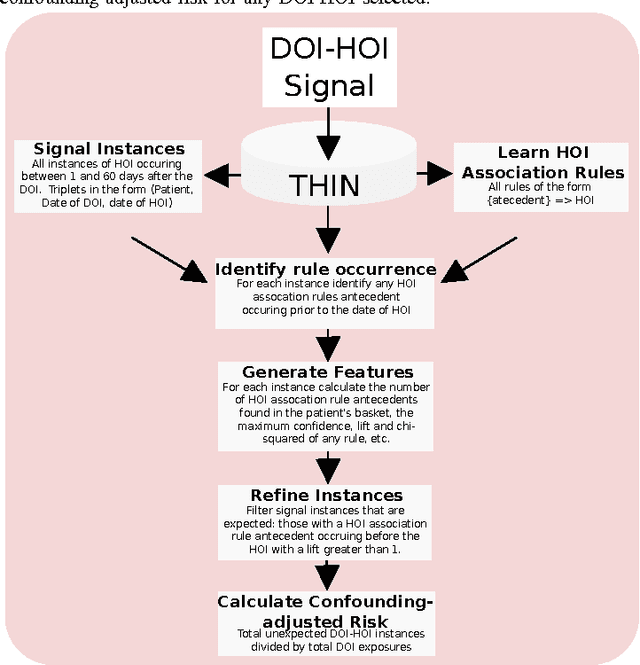
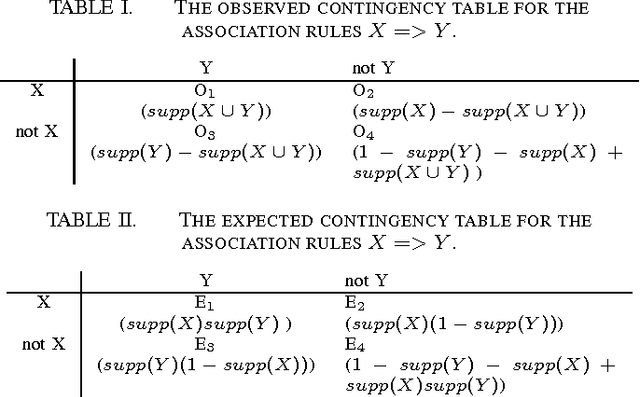

Side effects of prescribed medications are a common occurrence. Electronic healthcare databases present the opportunity to identify new side effects efficiently but currently the methods are limited due to confounding (i.e. when an association between two variables is identified due to them both being associated to a third variable). In this paper we propose a proof of concept method that learns common associations and uses this knowledge to automatically refine side effect signals (i.e. exposure-outcome associations) by removing instances of the exposure-outcome associations that are caused by confounding. This leaves the signal instances that are most likely to correspond to true side effect occurrences. We then calculate a novel measure termed the confounding-adjusted risk value, a more accurate absolute risk value of a patient experiencing the outcome within 60 days of the exposure. Tentative results suggest that the method works. For the four signals (i.e. exposure-outcome associations) investigated we are able to correctly filter the majority of exposure-outcome instances that were unlikely to correspond to true side effects. The method is likely to improve when tuning the association rule mining parameters for specific health outcomes. This paper shows that it may be possible to filter signals at a patient level based on association rules learned from considering patients' medical histories. However, additional work is required to develop a way to automate the tuning of the method's parameters.