 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Cultural and Cultural-Specific Production and Perception of Facial Expressions of Emotion in the Wild
Aug 13, 2018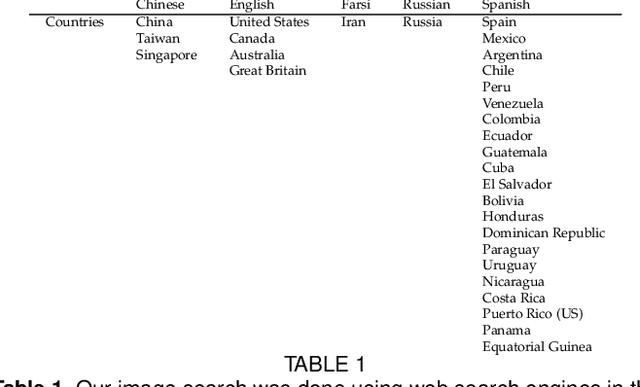
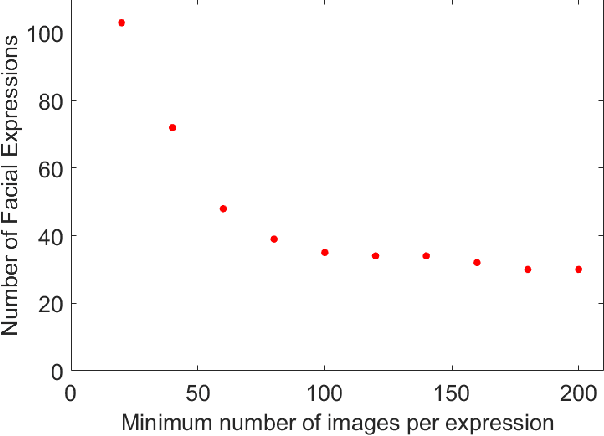

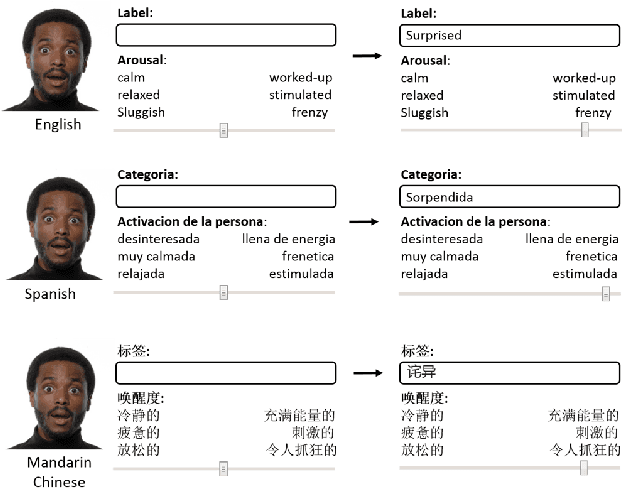
Automatic recognition of emotion from facial expressions is an intense area of research, with a potentially long list of important application. Yet, the study of emotion requires knowing which facial expressions are used within and across cultures in the wild, not in controlled lab conditions; but such studies do not exist. Which and how many cross-cultural and cultural-specific facial expressions do people commonly use? And, what affect variables does each expression communicate to observers? If we are to design technology that understands the emotion of users, we need answers to these two fundamental questions. In this paper, we present the first large-scale study of the production and visual perception of facial expressions of emotion in the wild. We find that of the 16,384 possible facial configurations that people can theoretically produce, only 35 are successfully used to transmit emotive information across cultures, and only 8 within a smaller number of cultures. Crucially, we find that visual analysis of cross-cultural expressions yields consistent perception of emotion categories and valence, but not arousal. In contrast, visual analysis of cultural-specific expressions yields consistent perception of valence and arousal, but not of emotion categories. Additionally, we find that the number of expressions used to communicate each emotion is also different, e.g., 17 expressions transmit happiness, but only 1 is used to convey disgust.
EmotioNet Challenge: Recognition of facial expressions of emotion in the wild
Mar 03, 2017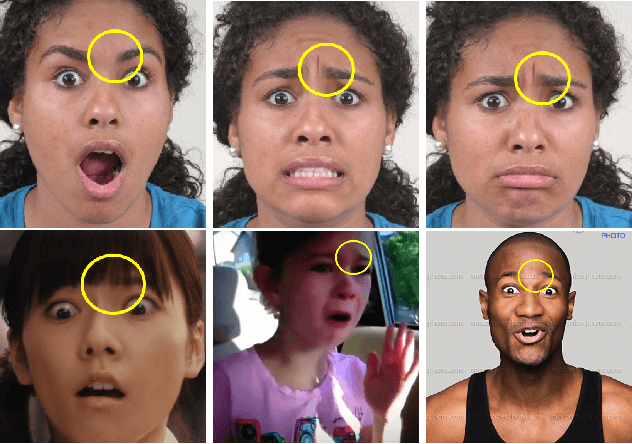
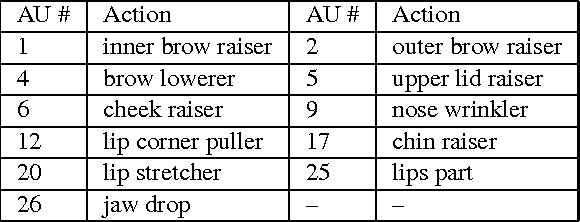
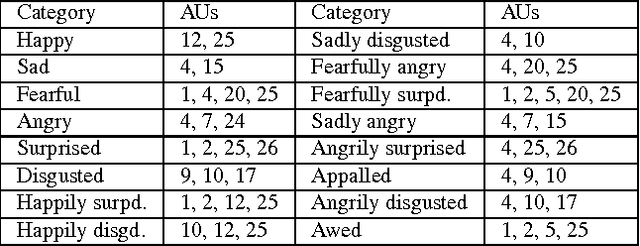

This paper details the methodology and results of the EmotioNet challenge. This challenge is the first to test the ability of computer vision algorithms in the automatic analysis of a large number of images of facial expressions of emotion in the wild. The challenge was divided into two tracks. The first track tested the ability of current computer vision algorithms in the automatic detection of action units (AUs). Specifically, we tested the detection of 11 AUs. The second track tested the algorithms' ability to recognize emotion categories in images of facial expressions. Specifically, we tested the recognition of 16 basic and compound emotion categories. The results of the challenge suggest that current computer vision and machine learning algorithms are unable to reliably solve these two tasks. The limitations of current algorithms are more apparent when trying to recognize emotion. We also show that current algorithms are not affected by mild resolution changes, small occluders, gender or age, but that 3D pose is a major limiting factor on performance. We provide an in-depth discussion of the points that need special attention moving forward.