 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaterioMiner -- An ontology-based text mining dataset for extraction of process-structure-property entities
Aug 05, 2024



While large language models learn sound statistical representations of the language and information therein, ontologies are symbolic knowledge representations that can complement the former ideally. Research at this critical intersection relies on datasets that intertwine ontologies and text corpora to enable training and comprehensive benchmarking of neurosymbolic models. We present the MaterioMiner dataset and the linked materials mechanics ontology where ontological concepts from the mechanics of materials domain are associated with textual entities within the literature corpus. Another distinctive feature of the dataset is its eminently fine-granular annotation. Specifically, 179 distinct classes are manually annotated by three raters within four publications, amounting to a total of 2191 entities that were annotated and curated. Conceptual work is presented for the symbolic representation of causal composition-process-microstructure-property relationships. We explore the annotation consistency between the three raters and perform fine-tuning of pre-trained models to showcase the feasibility of named-entity recognition model training. Reusing the dataset can foster training and benchmarking of materials language models, automated ontology construction, and knowledge graph generation from textual data.
Addressing materials' microstructure diversity using transfer learning
Jul 29, 2021

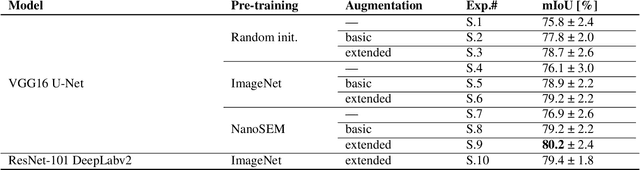
Materials' microstructures are signatures of their alloying composition and processing history. Therefore, microstructures exist in a wide variety. As materials become increasingly complex to comply with engineering demands, advanced computer vision (CV) approaches such as deep learning (DL) inevitably gain relevance for quantifying microstrucutures' constituents from micrographs. While DL can outperform classical CV techniques for many tasks, shortcomings are poor data efficiency and generalizability across datasets. This is inherently in conflict with the expense associated with annotating materials data through experts and extensive materials diversity. To tackle poor domain generalizability and the lack of labeled data simultaneously, we propose to apply a sub-class of transfer learning methods called unsupervised domain adaptation (UDA). These algorithms address the task of finding domain-invariant features when supplied with annotated source data and unannotated target data, such that performance on the latter distribution is optimized despite the absence of annotations. Exemplarily, this study is conducted on a lath-shaped bainite segmentation task in complex phase steel micrographs. Here, the domains to bridge are selected to be different metallographic specimen preparations (surface etchings) and distinct imaging modalities. We show that a state-of-the-art UDA approach surpasses the na\"ive application of source domain trained models on the target domain (generalization baseline) to a large extent. This holds true independent of the domain shift, despite using little data, and even when the baseline models were pre-trained or employed data augmentation. Through UDA, mIoU was improved over generalization baselines from 82.2%, 61.0%, 49.7% to 84.7%, 67.3%, 73.3% on three target datasets, respectively. This underlines this techniques' potential to cope with materials variance.