 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Deep Learning for Intracranial Aneurysm Blood Flow Simulation and Risk Assessment
Dec 09, 2025Intracranial aneurysms remain a major cause of neurological morbidity and mortality worldwide, where rupture risk is tightly coupled to local hemodynamics particularly wall shear stress and oscillatory shear index. Conventional computational fluid dynamics simulations provide accurate insights but are prohibitively slow and require specialized expertise. Clinical imaging alternatives such as 4D Flow MRI offer direct in-vivo measurements, yet their spatial resolution remains insufficient to capture the fine-scale shear patterns that drive endothelial remodeling and rupture risk while being extremely impractical and expensive. We present a graph neural network surrogate model that bridges this gap by reproducing full-field hemodynamics directly from vascular geometries in less than one minute per cardiac cycle. Trained on a comprehensive dataset of high-fidelity simulations of patient-specific aneurysms, our architecture combines graph transformers with autoregressive predictions to accurately simulate blood flow, wall shear stress, and oscillatory shear index. The model generalizes across unseen patient geometries and inflow conditions without mesh-specific calibration. Beyond accelerating simulation, our framework establishes the foundation for clinically interpretable hemodynamic prediction. By enabling near real-time inference integrated with existing imaging pipelines, it allows direct comparison with hospital phase-diagram assessments and extends them with physically grounded, high-resolution flow fields. This work transforms high-fidelity simulations from an expert-only research tool into a deployable, data-driven decision support system. Our full pipeline delivers high-resolution hemodynamic predictions within minutes of patient imaging, without requiring computational specialists, marking a step-change toward real-time, bedside aneurysm analysis.
Addressing materials' microstructure diversity using transfer learning
Jul 29, 2021

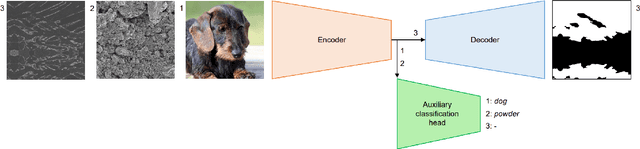
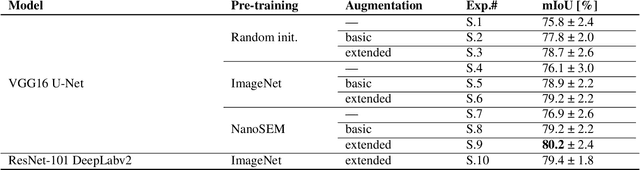
Materials' microstructures are signatures of their alloying composition and processing history. Therefore, microstructures exist in a wide variety. As materials become increasingly complex to comply with engineering demands, advanced computer vision (CV) approaches such as deep learning (DL) inevitably gain relevance for quantifying microstrucutures' constituents from micrographs. While DL can outperform classical CV techniques for many tasks, shortcomings are poor data efficiency and generalizability across datasets. This is inherently in conflict with the expense associated with annotating materials data through experts and extensive materials diversity. To tackle poor domain generalizability and the lack of labeled data simultaneously, we propose to apply a sub-class of transfer learning methods called unsupervised domain adaptation (UDA). These algorithms address the task of finding domain-invariant features when supplied with annotated source data and unannotated target data, such that performance on the latter distribution is optimized despite the absence of annotations. Exemplarily, this study is conducted on a lath-shaped bainite segmentation task in complex phase steel micrographs. Here, the domains to bridge are selected to be different metallographic specimen preparations (surface etchings) and distinct imaging modalities. We show that a state-of-the-art UDA approach surpasses the na\"ive application of source domain trained models on the target domain (generalization baseline) to a large extent. This holds true independent of the domain shift, despite using little data, and even when the baseline models were pre-trained or employed data augmentation. Through UDA, mIoU was improved over generalization baselines from 82.2%, 61.0%, 49.7% to 84.7%, 67.3%, 73.3% on three target datasets, respectively. This underlines this techniques' potential to cope with materials variance.