 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDegradation of Feature Space in Continual Learning
Feb 06, 2026Centralized training is the standard paradigm in deep learning, enabling models to learn from a unified dataset in a single location. In such setup, isotropic feature distributions naturally arise as a mean to support well-structured and generalizable representations. In contrast, continual learning operates on streaming and non-stationary data, and trains models incrementally, inherently facing the well-known plasticity-stability dilemma. In such settings, learning dynamics tends to yield increasingly anisotropic feature space. This arises a fundamental question: should isotropy be enforced to achieve a better balance between stability and plasticity, and thereby mitigate catastrophic forgetting? In this paper, we investigate whether promoting feature-space isotropy can enhance representation quality in continual learning. Through experiments using contrastive continual learning techniques on CIFAR-10 and CIFAR-100 data, we find that isotropic regularization fails to improve, and can in fact degrade, model accuracy in continual settings. Our results highlight essential differences in feature geometry between centralized and continual learning, suggesting that isotropy, while beneficial in centralized setups, may not constitute an appropriate inductive bias for non-stationary learning scenarios.
Self-Supervised Learning at the Edge: The Cost of Labeling
Jul 09, 2025Contrastive learning (CL) has recently emerged as an alternative to traditional supervised machine learning solutions by enabling rich representations from unstructured and unlabeled data. However, CL and, more broadly, self-supervised learning (SSL) methods often demand a large amount of data and computational resources, posing challenges for deployment on resource-constrained edge devices. In this work, we explore the feasibility and efficiency of SSL techniques for edge-based learning, focusing on trade-offs between model performance and energy efficiency. In particular, we analyze how different SSL techniques adapt to limited computational, data, and energy budgets, evaluating their effectiveness in learning robust representations under resource-constrained settings. Moreover, we also consider the energy costs involved in labeling data and assess how semi-supervised learning may assist in reducing the overall energy consumed to train CL models. Through extensive experiments, we demonstrate that tailored SSL strategies can achieve competitive performance while reducing resource consumption by up to 4X, underscoring their potential for energy-efficient learning at the edge.
Energy Minimization for Participatory Federated Learning in IoT Analyzed via Game Theory
Mar 27, 2025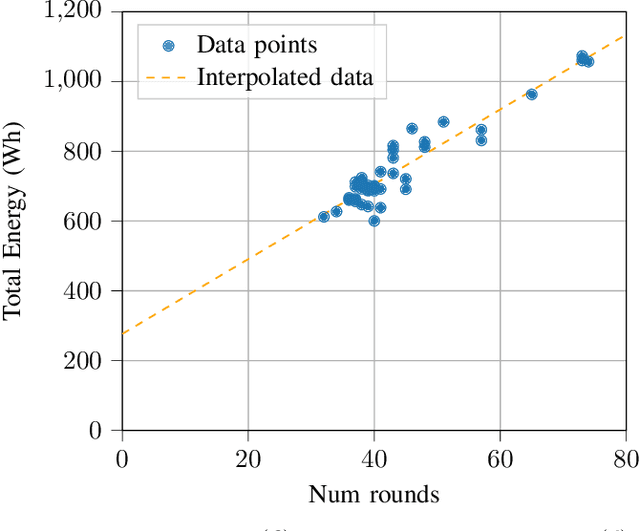
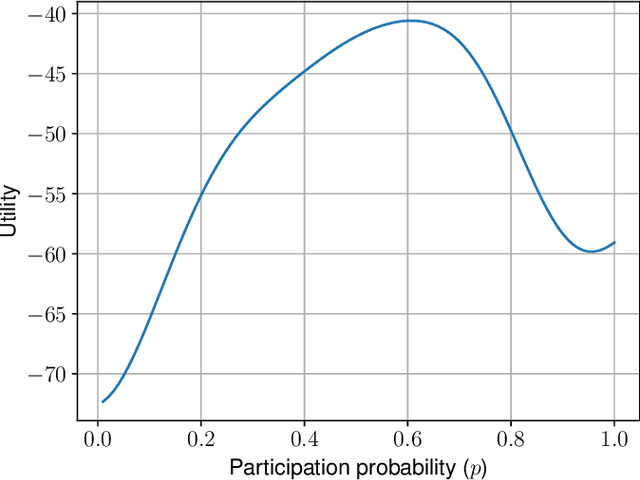
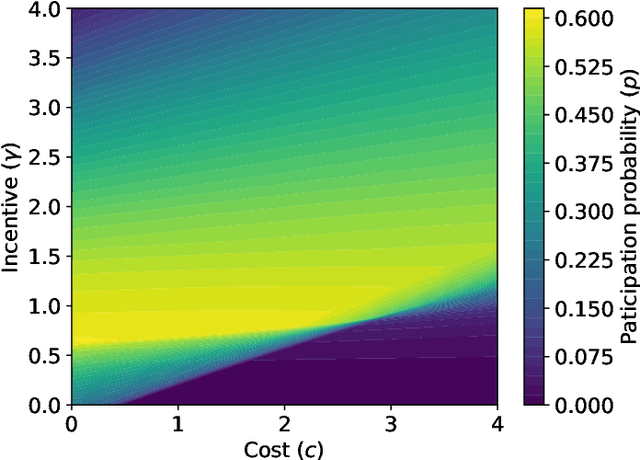
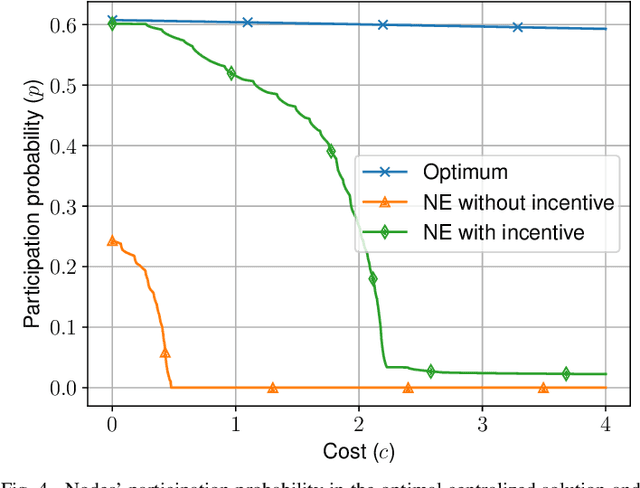
The Internet of Things requires intelligent decision making in many scenarios. To this end, resources available at the individual nodes for sensing or computing, or both, can be leveraged. This results in approaches known as participatory sensing and federated learning, respectively. We investigate the simultaneous implementation of both, through a distributed approach based on empowering local nodes with game theoretic decision making. A global objective of energy minimization is combined with the individual node's optimization of local expenditure for sensing and transmitting data over multiple learning rounds. We present extensive evaluations of this technique, based on both a theoretical framework and experiments in a simulated network scenario with real data. Such a distributed approach can reach a desired level of accuracy for federated learning without a centralized supervision of the data collector. However, depending on the weight attributed to the local costs of the single node, it may also result in a significantly high Price of Anarchy (from 1.28 onwards). Thus, we argue for the need of incentive mechanisms, possibly based on Age of Information of the single nodes.
* 6 pages, 6 figures, 2 tables, conference
Federated Learning in Mobile Networks: A Comprehensive Case Study on Traffic Forecasting
Dec 05, 2024



The increasing demand for efficient resource allocation in mobile networks has catalyzed the exploration of innovative solutions that could enhance the task of real-time cellular traffic prediction. Under these circumstances, federated learning (FL) stands out as a distributed and privacy-preserving solution to foster collaboration among different sites, thus enabling responsive near-the-edge solutions. In this paper, we comprehensively study the potential benefits of FL in telecommunications through a case study on federated traffic forecasting using real-world data from base stations (BSs) in Barcelona (Spain). Our study encompasses relevant aspects within the federated experience, including model aggregation techniques, outlier management, the impact of individual clients, personalized learning, and the integration of exogenous sources of data. The performed evaluation is based on both prediction accuracy and sustainability, thus showcasing the environmental impact of employed FL algorithms in various settings. The findings from our study highlight FL as a promising and robust solution for mobile traffic prediction, emphasizing its twin merits as a privacy-conscious and environmentally sustainable approach, while also demonstrating its capability to overcome data heterogeneity and ensure high-quality predictions, marking a significant stride towards its integration in mobile traffic management systems.
Energy-Aware Decentralized Learning with Intermittent Model Training
Jul 01, 2024



Decentralized learning (DL) offers a powerful framework where nodes collaboratively train models without sharing raw data and without the coordination of a central server. In the iterative rounds of DL, models are trained locally, shared with neighbors in the topology, and aggregated with other models received from neighbors. Sharing and merging models contribute to convergence towards a consensus model that generalizes better across the collective data captured at training time. In addition, the energy consumption while sharing and merging model parameters is negligible compared to the energy spent during the training phase. Leveraging this fact, we present SkipTrain, a novel DL algorithm, which minimizes energy consumption in decentralized learning by strategically skipping some training rounds and substituting them with synchronization rounds. These training-silent periods, besides saving energy, also allow models to better mix and finally produce models with superior accuracy than typical DL algorithms that train at every round. Our empirical evaluations with 256 nodes demonstrate that SkipTrain reduces energy consumption by 50% and increases model accuracy by up to 12% compared to D-PSGD, the conventional DL algorithm.
Mobile Traffic Prediction at the Edge through Distributed and Transfer Learning
Oct 22, 2023Traffic prediction represents one of the crucial tasks for smartly optimizing the mobile network. The research in this topic concentrated in making predictions in a centralized fashion, i.e., by collecting data from the different network elements. This translates to a considerable amount of energy for data transmission and processing. In this work, we propose a novel prediction framework based on edge computing which uses datasets obtained on the edge through a large measurement campaign. Two main Deep Learning architectures are designed, based on Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), and tested under different training conditions. In addition, Knowledge Transfer Learning (KTL) techniques are employed to improve the performance of the models while reducing the required computational resources. Simulation results show that the CNN architectures outperform the RNNs. An estimation for the needed training energy is provided, highlighting KTL ability to reduce the energy footprint of the models of 60% and 90% for CNNs and RNNs, respectively. Finally, two cutting-edge explainable Artificial Intelligence techniques are employed to interpret the derived learning models.
Towards Energy-Aware Federated Traffic Prediction for Cellular Networks
Sep 19, 2023Cellular traffic prediction is a crucial activity for optimizing networks in fifth-generation (5G) networks and beyond, as accurate forecasting is essential for intelligent network design, resource allocation and anomaly mitigation. Although machine learning (ML) is a promising approach to effectively predict network traffic, the centralization of massive data in a single data center raises issues regarding confidentiality, privacy and data transfer demands. To address these challenges, federated learning (FL) emerges as an appealing ML training framework which offers high accurate predictions through parallel distributed computations. However, the environmental impact of these methods is often overlooked, which calls into question their sustainability. In this paper, we address the trade-off between accuracy and energy consumption in FL by proposing a novel sustainability indicator that allows assessing the feasibility of ML models. Then, we comprehensively evaluate state-of-the-art deep learning (DL) architectures in a federated scenario using real-world measurements from base station (BS) sites in the area of Barcelona, Spain. Our findings indicate that larger ML models achieve marginally improved performance but have a significant environmental impact in terms of carbon footprint, which make them impractical for real-world applications.
How Much Does It Cost to Train a Machine Learning Model over Distributed Data Sources?
Sep 15, 2022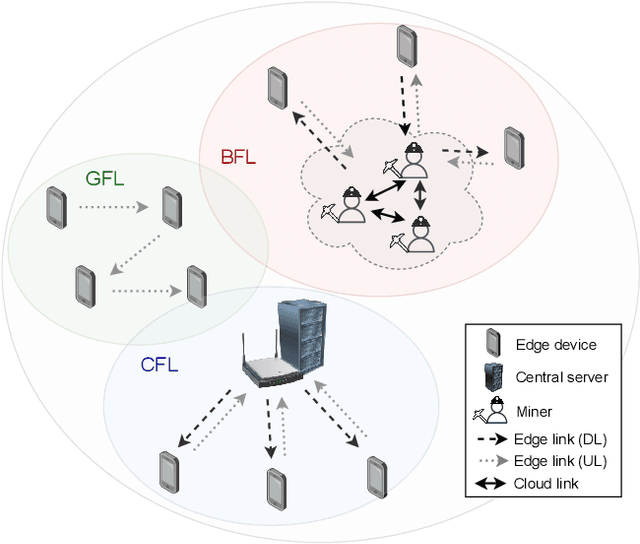
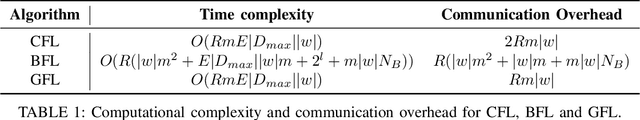
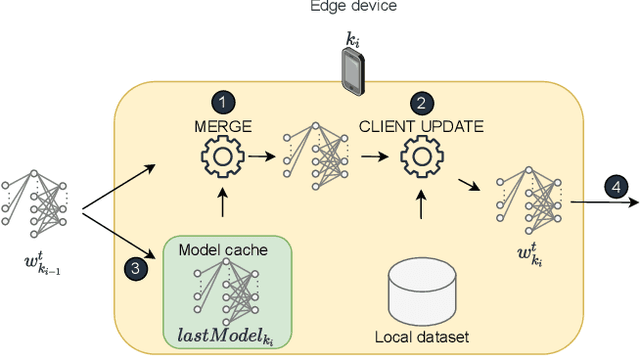
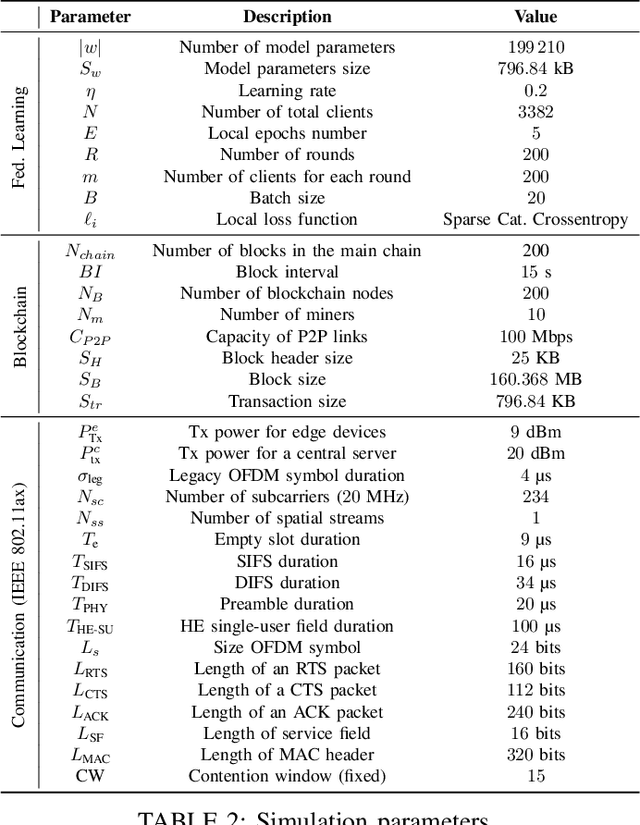
Federated learning (FL) is one of the most appealing alternatives to the standard centralized learning paradigm, allowing heterogeneous set of devices to train a machine learning model without sharing their raw data. However, FL requires a central server to coordinate the learning process, thus introducing potential scalability and security issues. In the literature, server-less FL approaches like gossip federated learning (GFL) and blockchain-enabled federated learning (BFL) have been proposed to mitigate these issues. In this work, we propose a complete overview of these three techniques proposing a comparison according to an integral set of performance indicators, including model accuracy, time complexity, communication overhead, convergence time and energy consumption. An extensive simulation campaign permits to draw a quantitative analysis. In particular, GFL is able to save the 18% of training time, the 68% of energy and the 51% of data to be shared with respect to the CFL solution, but it is not able to reach the level of accuracy of CFL. On the other hand, BFL represents a viable solution for implementing decentralized learning with a higher level of security, at the cost of an extra energy usage and data sharing. Finally, we identify open issues on the two decentralized federated learning implementations and provide insights on potential extensions and possible research directions on this new research field.
Distributed Deep Reinforcement Learning for Functional Split Control in Energy Harvesting Virtualized Small Cells
Aug 07, 2020
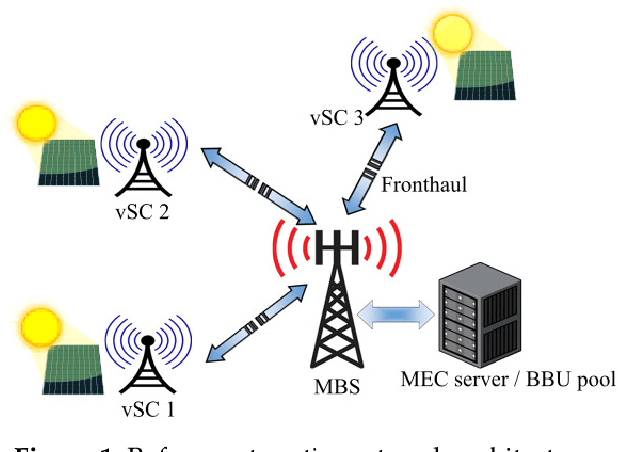
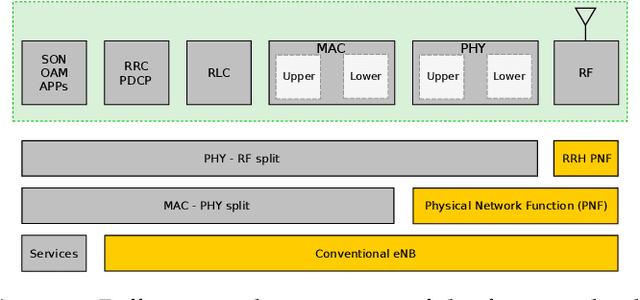
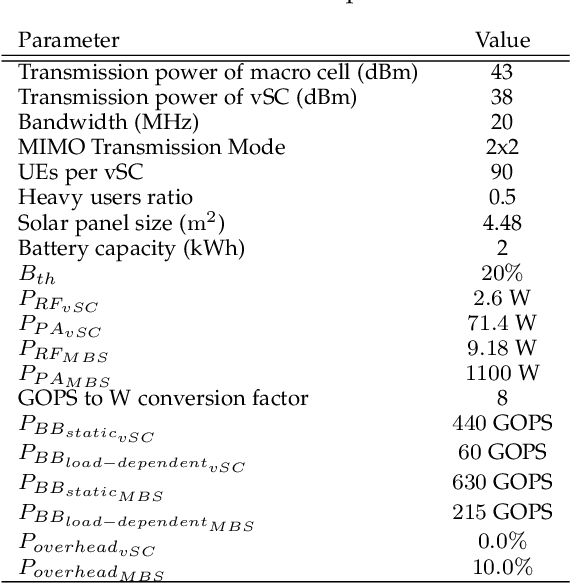
To meet the growing quest for enhanced network capacity, mobile network operators (MNOs) are deploying dense infrastructures of small cells. This, in turn, increases the power consumption of mobile networks, thus impacting the environment. As a result, we have seen a recent trend of powering mobile networks with harvested ambient energy to achieve both environmental and cost benefits. In this paper, we consider a network of virtualized small cells (vSCs) powered by energy harvesters and equipped with rechargeable batteries, which can opportunistically offload baseband (BB) functions to a grid-connected edge server depending on their energy availability. We formulate the corresponding grid energy and traffic drop rate minimization problem, and propose a distributed deep reinforcement learning (DDRL) solution. Coordination among vSCs is enabled via the exchange of battery state information. The evaluation of the network performance in terms of grid energy consumption and traffic drop rate confirms that enabling coordination among the vSCs via knowledge exchange achieves a performance close to the optimal. Numerical results also confirm that the proposed DDRL solution provides higher network performance, better adaptation to the changing environment, and higher cost savings with respect to a tabular multi-agent reinforcement learning (MRL) solution used as a benchmark.
Recurrent Neural Networks for Handover Management in Next-Generation Self-Organized Networks
Jun 11, 2020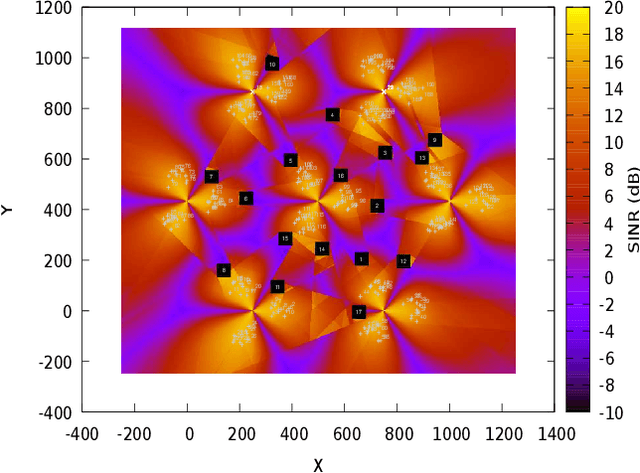
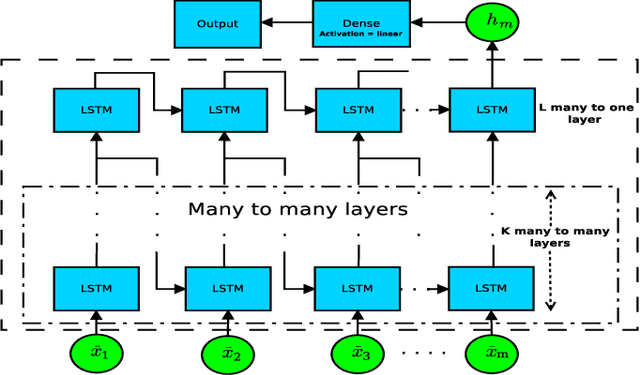
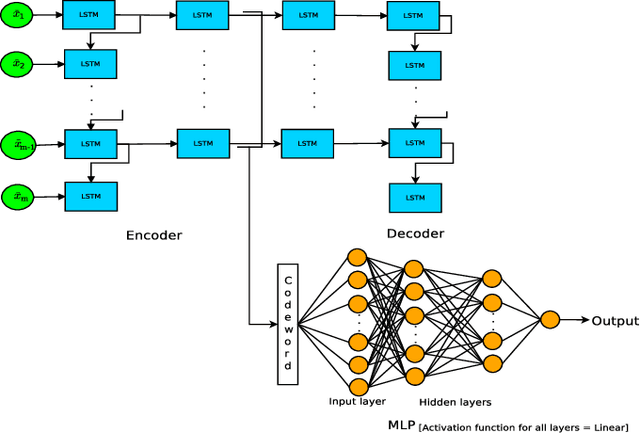
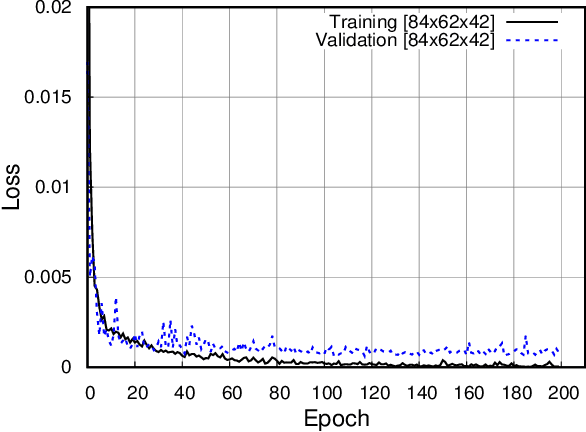
In this paper, we discuss a handover management scheme for Next Generation Self-Organized Networks. We propose to extract experience from full protocol stack data, to make smart handover decisions in a multi-cell scenario, where users move and are challenged by deep zones of an outage. Traditional handover schemes have the drawback of taking into account only the signal strength from the serving, and the target cell, before the handover. However, we believe that the expected Quality of Experience (QoE) resulting from the decision of target cell to handover to, should be the driving principle of the handover decision. In particular, we propose two models based on multi-layer many-to-one LSTM architecture, and a multi-layer LSTM AutoEncoder (AE) in conjunction with a MultiLayer Perceptron (MLP) neural network. We show that using experience extracted from data, we can improve the number of users finalizing the download by 18%, and we can reduce the time to download, with respect to a standard event-based handover benchmark scheme. Moreover, for the sake of generalization, we test the LSTM Autoencoder in a different scenario, where it maintains its performance improvements with a slight degradation, compared to the original scenario.