 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as Universal Predictors? An Empirical Study on Small Tabular Datasets
Aug 24, 2025Large Language Models (LLMs), originally developed for natural language processing (NLP), have demonstrated the potential to generalize across modalities and domains. With their in-context learning (ICL) capabilities, LLMs can perform predictive tasks over structured inputs without explicit fine-tuning on downstream tasks. In this work, we investigate the empirical function approximation capability of LLMs on small-scale structured datasets for classification, regression and clustering tasks. We evaluate the performance of state-of-the-art LLMs (GPT-5, GPT-4o, GPT-o3, Gemini-2.5-Flash, DeepSeek-R1) under few-shot prompting and compare them against established machine learning (ML) baselines, including linear models, ensemble methods and tabular foundation models (TFMs). Our results show that LLMs achieve strong performance in classification tasks under limited data availability, establishing practical zero-training baselines. In contrast, the performance in regression with continuous-valued outputs is poor compared to ML models, likely because regression demands outputs in a large (often infinite) space, and clustering results are similarly limited, which we attribute to the absence of genuine ICL in this setting. Nonetheless, this approach enables rapid, low-overhead data exploration and offers a viable alternative to traditional ML pipelines in business intelligence and exploratory analytics contexts. We further analyze the influence of context size and prompt structure on approximation quality, identifying trade-offs that affect predictive performance. Our findings suggest that LLMs can serve as general-purpose predictive engines for structured data, with clear strengths in classification and significant limitations in regression and clustering.
Evaluation of Bio-Inspired Models under Different Learning Settings For Energy Efficiency in Network Traffic Prediction
Dec 23, 2024



Cellular traffic forecasting is a critical task that enables network operators to efficiently allocate resources and address anomalies in rapidly evolving environments. The exponential growth of data collected from base stations poses significant challenges to processing and analysis. While machine learning (ML) algorithms have emerged as powerful tools for handling these large datasets and providing accurate predictions, their environmental impact, particularly in terms of energy consumption, is often overlooked in favor of their predictive capabilities. This study investigates the potential of two bio-inspired models: Spiking Neural Networks (SNNs) and Reservoir Computing through Echo State Networks (ESNs) for cellular traffic forecasting. The evaluation focuses on both their predictive performance and energy efficiency. These models are implemented in both centralized and federated settings to analyze their effectiveness and energy consumption in decentralized systems. Additionally, we compare bio-inspired models with traditional architectures, such as Convolutional Neural Networks (CNNs) and Multi-Layer Perceptrons (MLPs), to provide a comprehensive evaluation. Using data collected from three diverse locations in Barcelona, Spain, we examine the trade-offs between predictive accuracy and energy demands across these approaches. The results indicate that bio-inspired models, such as SNNs and ESNs, can achieve significant energy savings while maintaining predictive accuracy comparable to traditional architectures. Furthermore, federated implementations were tested to evaluate their energy efficiency in decentralized settings compared to centralized systems, particularly in combination with bio-inspired models. These findings offer valuable insights into the potential of bio-inspired models for sustainable and privacy-preserving cellular traffic forecasting.
Federated Learning in Mobile Networks: A Comprehensive Case Study on Traffic Forecasting
Dec 05, 2024



The increasing demand for efficient resource allocation in mobile networks has catalyzed the exploration of innovative solutions that could enhance the task of real-time cellular traffic prediction. Under these circumstances, federated learning (FL) stands out as a distributed and privacy-preserving solution to foster collaboration among different sites, thus enabling responsive near-the-edge solutions. In this paper, we comprehensively study the potential benefits of FL in telecommunications through a case study on federated traffic forecasting using real-world data from base stations (BSs) in Barcelona (Spain). Our study encompasses relevant aspects within the federated experience, including model aggregation techniques, outlier management, the impact of individual clients, personalized learning, and the integration of exogenous sources of data. The performed evaluation is based on both prediction accuracy and sustainability, thus showcasing the environmental impact of employed FL algorithms in various settings. The findings from our study highlight FL as a promising and robust solution for mobile traffic prediction, emphasizing its twin merits as a privacy-conscious and environmentally sustainable approach, while also demonstrating its capability to overcome data heterogeneity and ensure high-quality predictions, marking a significant stride towards its integration in mobile traffic management systems.
INDIANA: Personalized Travel Recommendations Using Wearables and AI
Nov 08, 2024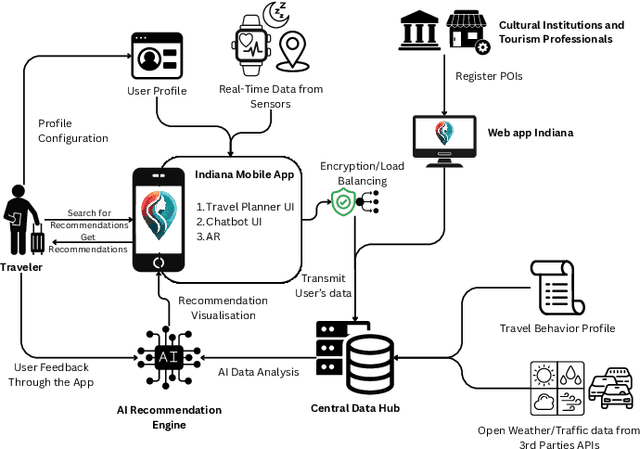
This work presents a personalized travel recommendation system developed as part of the INDIANA platform, designed to enhance the tourist experience through tailored activity suggestions, by leveraging data from wearable devices, user preferences, current location, weather forecasts, and activity history to provide real-time, context-aware recommendations. The platform not only supports individual tourists in maximizing their travel experience but also offers insights to tourism professionals to enhance service delivery, and by integrating modern technologies such as AI, IoT, and wearable analytics, it provides a seamless, personalized, and engaging experience for travelers.
Intelligent Client Selection for Federated Learning using Cellular Automata
Oct 18, 2023Federated Learning (FL) has emerged as a promising solution for privacy-enhancement and latency minimization in various real-world applications, such as transportation, communications, and healthcare. FL endeavors to bring Machine Learning (ML) down to the edge by harnessing data from million of devices and IoT sensors, thus enabling rapid responses to dynamic environments and yielding highly personalized results. However, the increased amount of sensors across diverse applications poses challenges in terms of communication and resource allocation, hindering the participation of all devices in the federated process and prompting the need for effective FL client selection. To address this issue, we propose Cellular Automaton-based Client Selection (CA-CS), a novel client selection algorithm, which leverages Cellular Automata (CA) as models to effectively capture spatio-temporal changes in a fast-evolving environment. CA-CS considers the computational resources and communication capacity of each participating client, while also accounting for inter-client interactions between neighbors during the client selection process, enabling intelligent client selection for online FL processes on data streams that closely resemble real-world scenarios. In this paper, we present a thorough evaluation of the proposed CA-CS algorithm using MNIST and CIFAR-10 datasets, while making a direct comparison against a uniformly random client selection scheme. Our results demonstrate that CA-CS achieves comparable accuracy to the random selection approach, while effectively avoiding high-latency clients.
Towards Energy-Aware Federated Traffic Prediction for Cellular Networks
Sep 19, 2023Cellular traffic prediction is a crucial activity for optimizing networks in fifth-generation (5G) networks and beyond, as accurate forecasting is essential for intelligent network design, resource allocation and anomaly mitigation. Although machine learning (ML) is a promising approach to effectively predict network traffic, the centralization of massive data in a single data center raises issues regarding confidentiality, privacy and data transfer demands. To address these challenges, federated learning (FL) emerges as an appealing ML training framework which offers high accurate predictions through parallel distributed computations. However, the environmental impact of these methods is often overlooked, which calls into question their sustainability. In this paper, we address the trade-off between accuracy and energy consumption in FL by proposing a novel sustainability indicator that allows assessing the feasibility of ML models. Then, we comprehensively evaluate state-of-the-art deep learning (DL) architectures in a federated scenario using real-world measurements from base station (BS) sites in the area of Barcelona, Spain. Our findings indicate that larger ML models achieve marginally improved performance but have a significant environmental impact in terms of carbon footprint, which make them impractical for real-world applications.
Federated Learning for Early Dropout Prediction on Healthy Ageing Applications
Sep 08, 2023The provision of social care applications is crucial for elderly people to improve their quality of life and enables operators to provide early interventions. Accurate predictions of user dropouts in healthy ageing applications are essential since they are directly related to individual health statuses. Machine Learning (ML) algorithms have enabled highly accurate predictions, outperforming traditional statistical methods that struggle to cope with individual patterns. However, ML requires a substantial amount of data for training, which is challenging due to the presence of personal identifiable information (PII) and the fragmentation posed by regulations. In this paper, we present a federated machine learning (FML) approach that minimizes privacy concerns and enables distributed training, without transferring individual data. We employ collaborative training by considering individuals and organizations under FML, which models both cross-device and cross-silo learning scenarios. Our approach is evaluated on a real-world dataset with non-independent and identically distributed (non-iid) data among clients, class imbalance and label ambiguity. Our results show that data selection and class imbalance handling techniques significantly improve the predictive accuracy of models trained under FML, demonstrating comparable or superior predictive performance than traditional ML models.
Federated Learning for 5G Base Station Traffic Forecasting
Nov 28, 2022



Mobile traffic prediction is of great importance on the path of enabling 5G mobile networks to perform smart and efficient infrastructure planning and management. However, available data are limited to base station logging information. Hence, training methods for generating high-quality predictions that can generalize to new observations on different parties are in demand. Traditional approaches require collecting measurements from different base stations and sending them to a central entity, followed by performing machine learning operations using the received data. The dissemination of local observations raises privacy, confidentiality, and performance concerns, hindering the applicability of machine learning techniques. Various distributed learning methods have been proposed to address this issue, but their application to traffic prediction has yet to be explored. In this work, we study the effectiveness of federated learning applied to raw base station aggregated LTE data for time-series forecasting. We evaluate one-step predictions using 5 different neural network architectures trained with a federated setting on non-iid data. The presented algorithms have been submitted to the Global Federated Traffic Prediction for 5G and Beyond Challenge. Our results show that the learning architectures adapted to the federated setting achieve equivalent prediction error to the centralized setting, pre-processing techniques on base stations lead to higher forecasting accuracy, while state-of-the-art aggregators do not outperform simple approaches.