 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Graph Neural Network for Privacy-Preserving Recommendation
Aug 15, 2023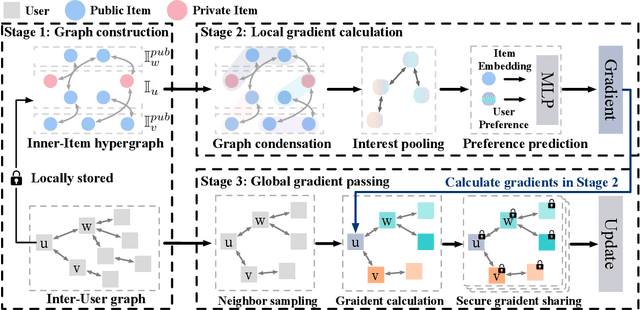
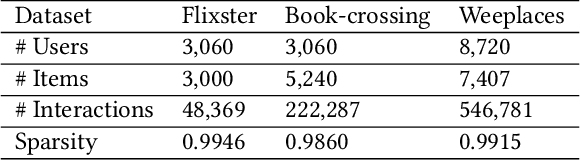
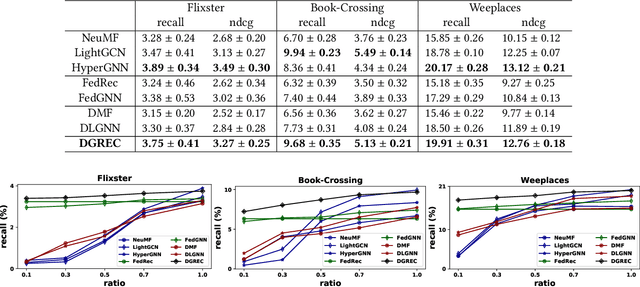
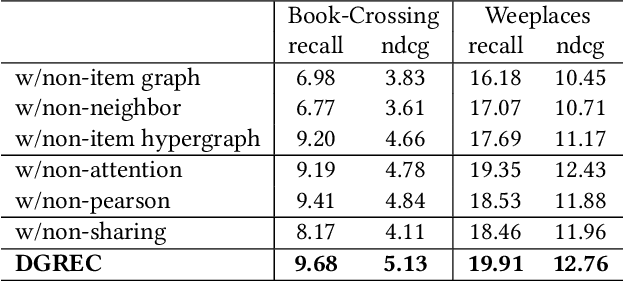
Building a graph neural network (GNN)-based recommender system without violating user privacy proves challenging. Existing methods can be divided into federated GNNs and decentralized GNNs. But both methods have undesirable effects, i.e., low communication efficiency and privacy leakage. This paper proposes DGREC, a novel decentralized GNN for privacy-preserving recommendations, where users can choose to publicize their interactions. It includes three stages, i.e., graph construction, local gradient calculation, and global gradient passing. The first stage builds a local inner-item hypergraph for each user and a global inter-user graph. The second stage models user preference and calculates gradients on each local device. The third stage designs a local differential privacy mechanism named secure gradient-sharing, which proves strong privacy-preserving of users' private data. We conduct extensive experiments on three public datasets to validate the consistent superiority of our framework.
Freshness or Accuracy, Why Not Both? Addressing Delayed Feedback via Dynamic Graph Neural Networks
Aug 15, 2023The delayed feedback problem is one of the most pressing challenges in predicting the conversion rate since users' conversions are always delayed in online commercial systems. Although new data are beneficial for continuous training, without complete feedback information, i.e., conversion labels, training algorithms may suffer from overwhelming fake negatives. Existing methods tend to use multitask learning or design data pipelines to solve the delayed feedback problem. However, these methods have a trade-off between data freshness and label accuracy. In this paper, we propose Delayed Feedback Modeling by Dynamic Graph Neural Network (DGDFEM). It includes three stages, i.e., preparing a data pipeline, building a dynamic graph, and training a CVR prediction model. In the model training, we propose a novel graph convolutional method named HLGCN, which leverages both high-pass and low-pass filters to deal with conversion and non-conversion relationships. The proposed method achieves both data freshness and label accuracy. We conduct extensive experiments on three industry datasets, which validate the consistent superiority of our method.