 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Commodity WiFi Sensors Fail at Multi-Person Gait Identification: A Systematic Analysis Using ESP32
Jan 05, 2026WiFi Channel State Information (CSI) has shown promise for single-person gait identification, with numerous studies reporting high accuracy. However, multi-person identification remains largely unexplored, with the limited existing work relying on complex, expensive setups requiring modified firmware. A critical question remains unanswered: is poor multi-person performance an algorithmic limitation or a fundamental hardware constraint? We systematically evaluate six diverse signal separation methods (FastICA, SOBI, PCA, NMF, Wavelet, Tensor Decomposition) across seven scenarios with 1-10 people using commodity ESP32 WiFi sensors--a simple, low-cost, off-the-shelf solution. Through novel diagnostic metrics (intra-subject variability, inter-subject distinguishability, performance degradation rate), we reveal that all methods achieve similarly low accuracy (45-56\%, $σ$=3.74\%) with statistically insignificant differences (p $>$ 0.05). Even the best-performing method, NMF, achieves only 56\% accuracy. Our analysis reveals high intra-subject variability, low inter-subject distinguishability, and severe performance degradation as person count increases, indicating that commodity ESP32 sensors cannot provide sufficient signal quality for reliable multi-person separation.
Parameter-Efficient Domain Adaption for CSI Crowd-Counting via Self-Supervised Learning with Adapter Modules
Jan 05, 2026Device-free crowd-counting using WiFi Channel State Information (CSI) is a key enabling technology for a new generation of privacy-preserving Internet of Things (IoT) applications. However, practical deployment is severely hampered by the domain shift problem, where models trained in one environment fail to generalise to another. To overcome this, we propose a novel two-stage framework centred on a CSI-ResNet-A architecture. This model is pre-trained via self-supervised contrastive learning to learn domain-invariant representations and leverages lightweight Adapter modules for highly efficient fine-tuning. The resulting event sequence is then processed by a stateful counting machine to produce a final, stable occupancy estimate. We validate our framework extensively. On our WiFlow dataset, our unsupervised approach excels in a 10-shot learning scenario, achieving a final Mean Absolute Error (MAE) of just 0.44--a task where supervised baselines fail. To formally quantify robustness, we introduce the Generalisation Index (GI), on which our model scores near-perfectly, confirming its ability to generalise. Furthermore, our framework sets a new state-of-the-art public WiAR benchmark with 98.8\% accuracy. Our ablation studies reveal the core strength of our design: adapter-based fine-tuning achieves performance within 1\% of a full fine-tune (98.84\% vs. 99.67\%) while training 97.2\% fewer parameters. Our work provides a practical and scalable solution for developing robust sensing systems ready for real-world IoT deployments.
Whisker-Inspired Tactile Sensing: A Sim2Real Approach for Precise Underwater Contact Tracking
Oct 17, 2024



Aquatic mammals, such as pinnipeds, utilize their whiskers to detect and discriminate objects and analyze water movements, inspiring the development of robotic whiskers for sensing contacts, surfaces, and water flows. We present the design and application of underwater whisker sensors based on Fiber Bragg Grating (FBG) technology. These passive whiskers are mounted along the robot$'$s exterior to sense its surroundings through light, non-intrusive contacts. For contact tracking, we employ a sim-to-real learning framework, which involves extensive data collection in simulation followed by a sim-to-real calibration process to transfer the model trained in simulation to the real world. Experiments with whiskers immersed in water indicate that our approach can track contact points with an accuracy of $<2$ mm, without requiring precise robot proprioception. We demonstrate that the approach also generalizes to unseen objects.
Interactive Generative Adversarial Networks for Facial Expression Generation in Dyadic Interactions
Jan 30, 2018
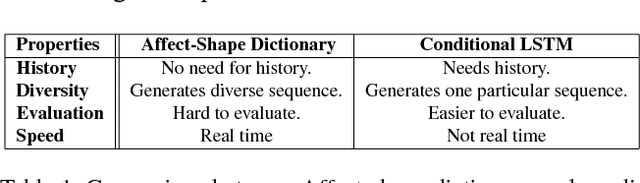


A social interaction is a social exchange between two or more individuals,where individuals modify and adjust their behaviors in response to their interaction partners. Our social interactions are one of most fundamental aspects of our lives and can profoundly affect our mood, both positively and negatively. With growing interest in virtual reality and avatar-mediated interactions,it is desirable to make these interactions natural and human like to promote positive effect in the interactions and applications such as intelligent tutoring systems, automated interview systems and e-learning. In this paper, we propose a method to generate facial behaviors for an agent. These behaviors include facial expressions and head pose and they are generated considering the users affective state. Our models learn semantically meaningful representations of the face and generate appropriate and temporally smooth facial behaviors in dyadic interactions.