 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIANT: Globally Improved Approximate Newton Method for Distributed Optimization
Sep 11, 2018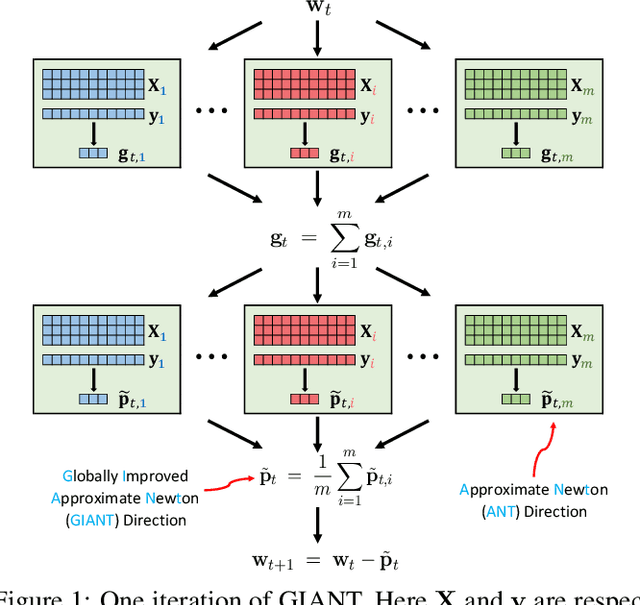

For distributed computing environment, we consider the empirical risk minimization problem and propose a distributed and communication-efficient Newton-type optimization method. At every iteration, each worker locally finds an Approximate NewTon (ANT) direction, which is sent to the main driver. The main driver, then, averages all the ANT directions received from workers to form a {\it Globally Improved ANT} (GIANT) direction. GIANT is highly communication efficient and naturally exploits the trade-offs between local computations and global communications in that more local computations result in fewer overall rounds of communications. Theoretically, we show that GIANT enjoys an improved convergence rate as compared with first-order methods and existing distributed Newton-type methods. Further, and in sharp contrast with many existing distributed Newton-type methods, as well as popular first-order methods, a highly advantageous practical feature of GIANT is that it only involves one tuning parameter. We conduct large-scale experiments on a computer cluster and, empirically, demonstrate the superior performance of GIANT.
Distributed Second-order Convex Optimization
Jul 18, 2018


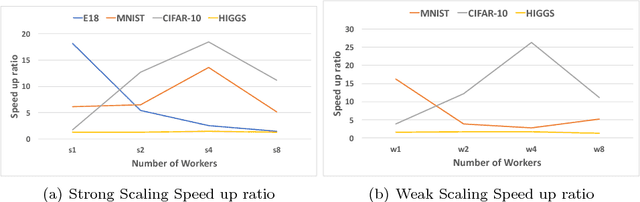
Convex optimization problems arise frequently in diverse machine learning (ML) applications. First-order methods, i.e., those that solely rely on the gradient information, are most commonly used to solve these problems. This choice is motivated by their simplicity and low per-iteration cost. Second-order methods that rely on curvature information through the dense Hessian matrix have, thus far, proven to be prohibitively expensive at scale, both in terms of computational and memory requirements. We present a novel multi-GPU distributed formulation of a second order (Newton-type) solver for convex finite sum minimization problems for multi-class classification. Our distributed formulation relies on the Alternating Direction of Multipliers Method (ADMM), which requires only one round of communication per-iteration -- significantly reducing communication overheads, while incurring minimal convergence overhead. By leveraging the computational capabilities of GPUs, we demonstrate that per-iteration costs of Newton-type methods can be significantly reduced to be on-par with, if not better than, state-of-the-art first-order alternatives. Given their significantly faster convergence rates, we demonstrate that our methods can process large data-sets in much shorter time (orders of magnitude in many cases) compared to existing first and second order methods, while yielding similar test-accuracy results.
Invariance of Weight Distributions in Rectified MLPs
Jun 01, 2018
An interesting approach to analyzing neural networks that has received renewed attention is to examine the equivalent kernel of the neural network. This is based on the fact that a fully connected feedforward network with one hidden layer, a certain weight distribution, an activation function, and an infinite number of neurons can be viewed as a mapping into a Hilbert space. We derive the equivalent kernels of MLPs with ReLU or Leaky ReLU activations for all rotationally-invariant weight distributions, generalizing a previous result that required Gaussian weight distributions. Additionally, the Central Limit Theorem is used to show that for certain activation functions, kernels corresponding to layers with weight distributions having $0$ mean and finite absolute third moment are asymptotically universal, and are well approximated by the kernel corresponding to layers with spherical Gaussian weights. In deep networks, as depth increases the equivalent kernel approaches a pathological fixed point, which can be used to argue why training randomly initialized networks can be difficult. Our results also have implications for weight initialization.
GPU Accelerated Sub-Sampled Newton's Method
Mar 03, 2018


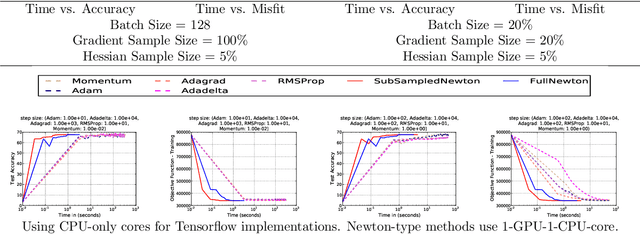
First order methods, which solely rely on gradient information, are commonly used in diverse machine learning (ML) and data analysis (DA) applications. This is attributed to the simplicity of their implementations, as well as low per-iteration computational/storage costs. However, they suffer from significant disadvantages; most notably, their performance degrades with increasing problem ill-conditioning. Furthermore, they often involve a large number of hyper-parameters, and are notoriously sensitive to parameters such as the step-size. By incorporating additional information from the Hessian, second-order methods, have been shown to be resilient to many such adversarial effects. However, these advantages of using curvature information come at the cost of higher per-iteration costs, which in \enquote{big data} regimes, can be computationally prohibitive. In this paper, we show that, contrary to conventional belief, second-order methods, when implemented appropriately, can be more efficient than first-order alternatives in many large-scale ML/ DA applications. In particular, in convex settings, we consider variants of classical Newton\textsf{'}s method in which the Hessian and/or the gradient are randomly sub-sampled. We show that by effectively leveraging the power of GPUs, such randomized Newton-type algorithms can be significantly accelerated, and can easily outperform state of the art implementations of existing techniques in popular ML/ DA software packages such as TensorFlow. Additionally these randomized methods incur a small memory overhead compared to first-order methods. In particular, we show that for million-dimensional problems, our GPU accelerated sub-sampled Newton\textsf{'}s method achieves a higher test accuracy in milliseconds as compared with tens of seconds for first order alternatives.
Out-of-sample extension of graph adjacency spectral embedding
Feb 17, 2018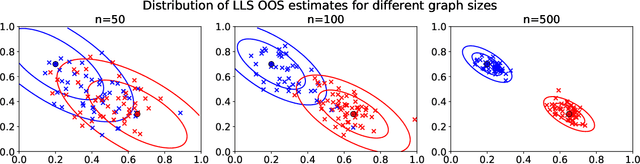
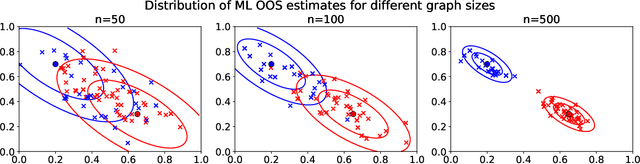
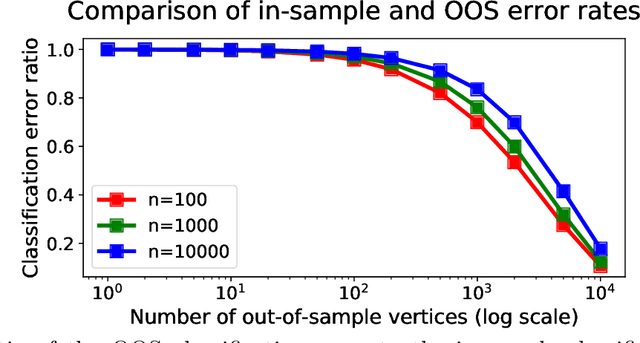
Many popular dimensionality reduction procedures have out-of-sample extensions, which allow a practitioner to apply a learned embedding to observations not seen in the initial training sample. In this work, we consider the problem of obtaining an out-of-sample extension for the adjacency spectral embedding, a procedure for embedding the vertices of a graph into Euclidean space. We present two different approaches to this problem, one based on a least-squares objective and the other based on a maximum-likelihood formulation. We show that if the graph of interest is drawn according to a certain latent position model called a random dot product graph, then both of these out-of-sample extensions estimate the true latent position of the out-of-sample vertex with the same error rate. Further, we prove a central limit theorem for the least-squares-based extension, showing that the estimate is asymptotically normal about the truth in the large-graph limit.
Second-Order Optimization for Non-Convex Machine Learning: An Empirical Study
Feb 16, 2018


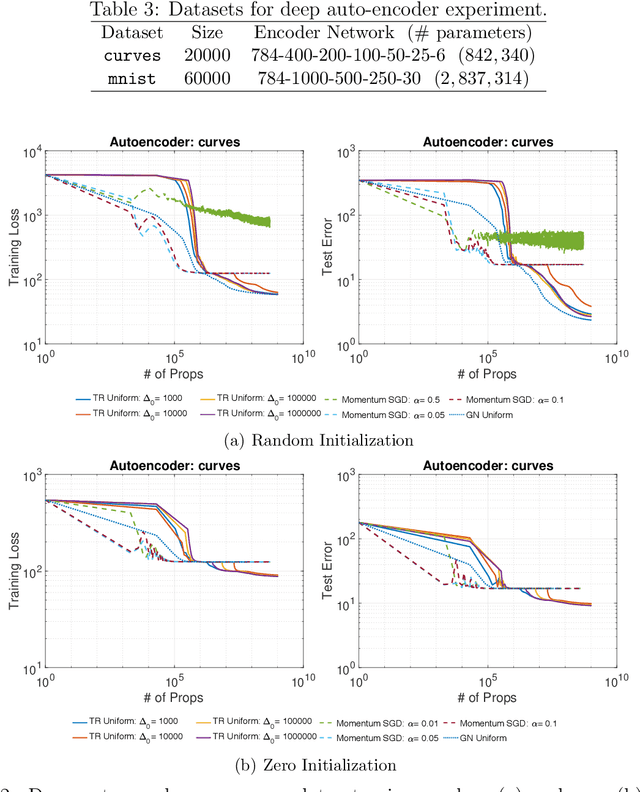
While first-order optimization methods such as stochastic gradient descent (SGD) are popular in machine learning (ML), they come with well-known deficiencies, including relatively-slow convergence, sensitivity to the settings of hyper-parameters such as learning rate, stagnation at high training errors, and difficulty in escaping flat regions and saddle points. These issues are particularly acute in highly non-convex settings such as those arising in neural networks. Motivated by this, there has been recent interest in second-order methods that aim to alleviate these shortcomings by capturing curvature information. In this paper, we report detailed empirical evaluations of a class of Newton-type methods, namely sub-sampled variants of trust region (TR) and adaptive regularization with cubics (ARC) algorithms, for non-convex ML problems. In doing so, we demonstrate that these methods not only can be computationally competitive with hand-tuned SGD with momentum, obtaining comparable or better generalization performance, but also they are highly robust to hyper-parameter settings. Further, in contrast to SGD with momentum, we show that the manner in which these Newton-type methods employ curvature information allows them to seamlessly escape flat regions and saddle points.
Newton-Type Methods for Non-Convex Optimization Under Inexact Hessian Information
Feb 15, 2018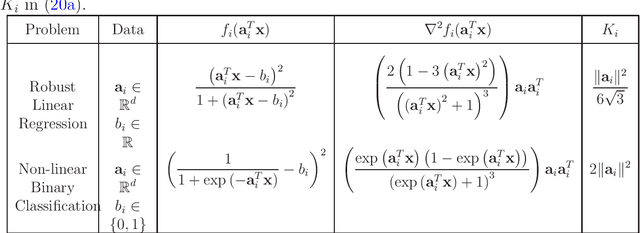
We consider variants of trust-region and cubic regularization methods for non-convex optimization, in which the Hessian matrix is approximated. Under mild conditions on the inexact Hessian, and using approximate solution of the corresponding sub-problems, we provide iteration complexity to achieve $ \epsilon $-approximate second-order optimality which have shown to be tight. Our Hessian approximation conditions constitute a major relaxation over the existing ones in the literature. Consequently, we are able to show that such mild conditions allow for the construction of the approximate Hessian through various random sampling methods. In this light, we consider the canonical problem of finite-sum minimization, provide appropriate uniform and non-uniform sub-sampling strategies to construct such Hessian approximations, and obtain optimal iteration complexity for the corresponding sub-sampled trust-region and cubic regularization methods.
FLAG n' FLARE: Fast Linearly-Coupled Adaptive Gradient Methods
Nov 11, 2017We consider first order gradient methods for effectively optimizing a composite objective in the form of a sum of smooth and, potentially, non-smooth functions. We present accelerated and adaptive gradient methods, called FLAG and FLARE, which can offer the best of both worlds. They can achieve the optimal convergence rate by attaining the optimal first-order oracle complexity for smooth convex optimization. Additionally, they can adaptively and non-uniformly re-scale the gradient direction to adapt to the limited curvature available and conform to the geometry of the domain. We show theoretically and empirically that, through the compounding effects of acceleration and adaptivity, FLAG and FLARE can be highly effective for many data fitting and machine learning applications.
Union of Intersections (UoI) for Interpretable Data Driven Discovery and Prediction
Nov 02, 2017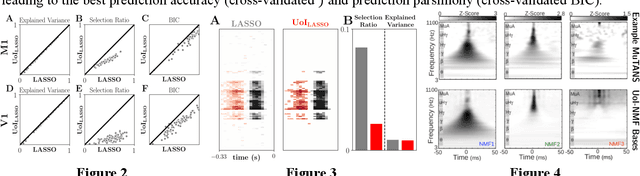
The increasing size and complexity of scientific data could dramatically enhance discovery and prediction for basic scientific applications. Realizing this potential, however, requires novel statistical analysis methods that are both interpretable and predictive. We introduce Union of Intersections (UoI), a flexible, modular, and scalable framework for enhanced model selection and estimation. Methods based on UoI perform model selection and model estimation through intersection and union operations, respectively. We show that UoI-based methods achieve low-variance and nearly unbiased estimation of a small number of interpretable features, while maintaining high-quality prediction accuracy. We perform extensive numerical investigation to evaluate a UoI algorithm ($UoI_{Lasso}$) on synthetic and real data. In doing so, we demonstrate the extraction of interpretable functional networks from human electrophysiology recordings as well as accurate prediction of phenotypes from genotype-phenotype data with reduced features. We also show (with the $UoI_{L1Logistic}$ and $UoI_{CUR}$ variants of the basic framework) improved prediction parsimony for classification and matrix factorization on several benchmark biomedical data sets. These results suggest that methods based on the UoI framework could improve interpretation and prediction in data-driven discovery across scientific fields.
Sub-sampled Newton Methods with Non-uniform Sampling
Jul 05, 2016



We consider the problem of finding the minimizer of a convex function $F: \mathbb R^d \rightarrow \mathbb R$ of the form $F(w) := \sum_{i=1}^n f_i(w) + R(w)$ where a low-rank factorization of $\nabla^2 f_i(w)$ is readily available. We consider the regime where $n \gg d$. As second-order methods prove to be effective in finding the minimizer to a high-precision, in this work, we propose randomized Newton-type algorithms that exploit \textit{non-uniform} sub-sampling of $\{\nabla^2 f_i(w)\}_{i=1}^{n}$, as well as inexact updates, as means to reduce the computational complexity. Two non-uniform sampling distributions based on {\it block norm squares} and {\it block partial leverage scores} are considered in order to capture important terms among $\{\nabla^2 f_i(w)\}_{i=1}^{n}$. We show that at each iteration non-uniformly sampling at most $\mathcal O(d \log d)$ terms from $\{\nabla^2 f_i(w)\}_{i=1}^{n}$ is sufficient to achieve a linear-quadratic convergence rate in $w$ when a suitable initial point is provided. In addition, we show that our algorithms achieve a lower computational complexity and exhibit more robustness and better dependence on problem specific quantities, such as the condition number, compared to similar existing methods, especially the ones based on uniform sampling. Finally, we empirically demonstrate that our methods are at least twice as fast as Newton's methods with ridge logistic regression on several real datasets.