 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProsody Transfer in Neural Text to Speech Using Global Pitch and Loudness Features
Paper and Code
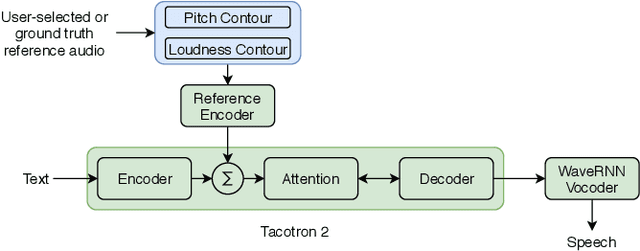
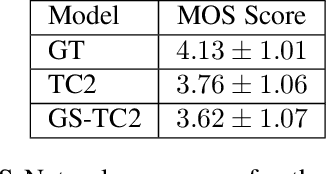

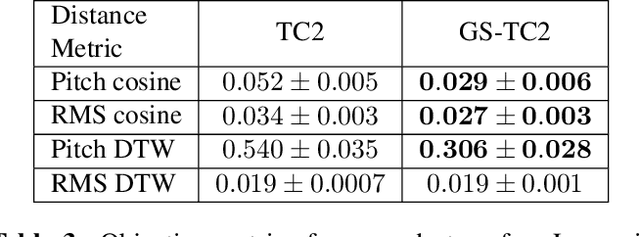
This paper presents a simple yet effective method to achieve prosody transfer from a reference speech signal to synthesized speech. The main idea is to incorporate well-known acoustic correlates of prosody such as pitch and loudness contours of the reference speech into a modern neural text-to-speech (TTS) synthesizer such as Tacotron2 (TC2). More specifically, a small set of acoustic features are extracted from the reference audio and then used to condition a TC2 synthesizer. The trained model is evaluated using subjective listening tests and novel objective evaluations of prosody transfer are proposed. Listening tests show that the synthesized speech is rated as highly natural and that prosody is successfully transferred from the reference speech signal to the synthesized signal.