 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Data Selection via Discrete Speech Representation for ASR
Paper and Code
Apr 05, 2022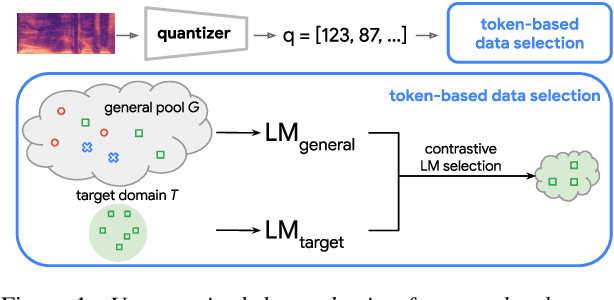


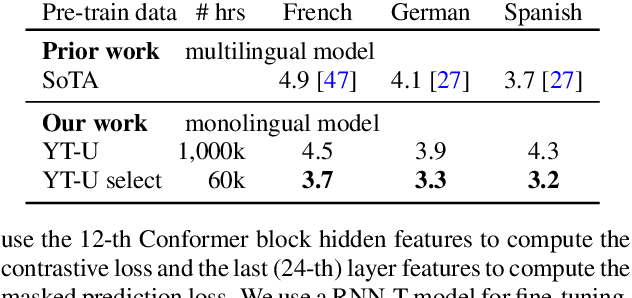
Self-supervised learning of speech representations has achieved impressive results in improving automatic speech recognition (ASR). In this paper, we show that data selection is important for self-supervised learning. We propose a simple and effective unsupervised data selection method which selects acoustically similar speech to a target domain. It takes the discrete speech representation available in common self-supervised learning frameworks as input, and applies a contrastive data selection method on the discrete tokens. Through extensive empirical studies we show that our proposed method reduces the amount of required pre-training data and improves the downstream ASR performance. Pre-training on a selected subset of 6% of the general data pool results in 11.8% relative improvements in LibriSpeech test-other compared to pre-training on the full set. On Multilingual LibriSpeech French, German, and Spanish test sets, selecting 6% data for pre-training reduces word error rate by more than 15% relatively compared to the full set, and achieves competitive results compared to current state-of-the-art performances.