 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Keypoint Detector and Descriptor for Retinal Image Matching
Paper and Code
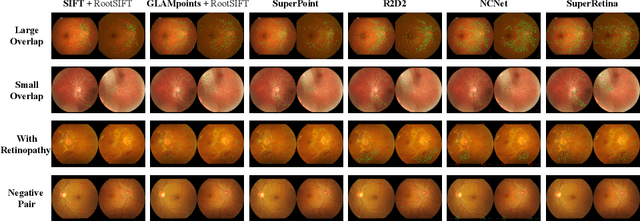
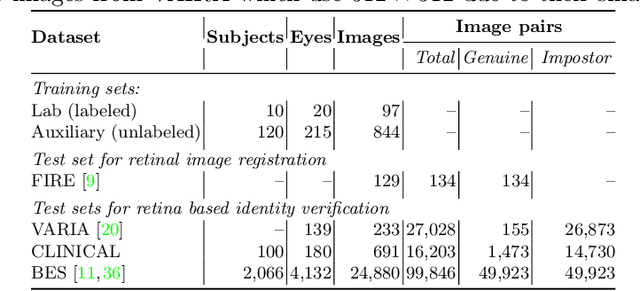

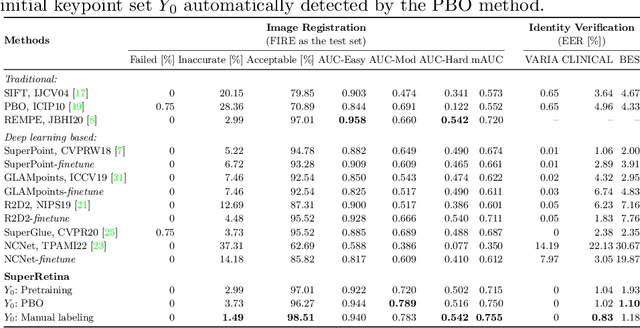
For retinal image matching (RIM), we propose SuperRetina, the first end-to-end method with jointly trainable keypoint detector and descriptor. SuperRetina is trained in a novel semi-supervised manner. A small set of (nearly 100) images are incompletely labeled and used to supervise the network to detect keypoints on the vascular tree. To attack the incompleteness of manual labeling, we propose Progressive Keypoint Expansion to enrich the keypoint labels at each training epoch. By utilizing a keypoint-based improved triplet loss as its description loss, SuperRetina produces highly discriminative descriptors at full input image size. Extensive experiments on multiple real-world datasets justify the viability of SuperRetina. Even with manual labeling replaced by auto labeling and thus making the training process fully manual-annotation free, SuperRetina compares favorably against a number of strong baselines for two RIM tasks, i.e. image registration and identity verification. SuperRetina will be open source.