 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHTMuon: Improving Muon via Heavy-Tailed Spectral Correction
Mar 10, 2026Muon has recently shown promising results in LLM training. In this work, we study how to further improve Muon. We argue that Muon's orthogonalized update rule suppresses the emergence of heavy-tailed weight spectra and over-emphasizes the training along noise-dominated directions. Motivated by the Heavy-Tailed Self-Regularization (HT-SR) theory, we propose HTMuon. HTMuon preserves Muon's ability to capture parameter interdependencies while producing heavier-tailed updates and inducing heavier-tailed weight spectra. Experiments on LLM pretraining and image classification show that HTMuon consistently improves performance over state-of-the-art baselines and can also serve as a plug-in on top of existing Muon variants. For example, on LLaMA pretraining on the C4 dataset, HTMuon reduces perplexity by up to $0.98$ compared to Muon. We further theoretically show that HTMuon corresponds to steepest descent under the Schatten-$q$ norm constraint and provide convergence analysis in smooth non-convex settings. The implementation of HTMuon is available at https://github.com/TDCSZ327/HTmuon.
Why LLM Safety Guardrails Collapse After Fine-tuning: A Similarity Analysis Between Alignment and Fine-tuning Datasets
Jun 05, 2025Recent advancements in large language models (LLMs) have underscored their vulnerability to safety alignment jailbreaks, particularly when subjected to downstream fine-tuning. However, existing mitigation strategies primarily focus on reactively addressing jailbreak incidents after safety guardrails have been compromised, removing harmful gradients during fine-tuning, or continuously reinforcing safety alignment throughout fine-tuning. As such, they tend to overlook a critical upstream factor: the role of the original safety-alignment data. This paper therefore investigates the degradation of safety guardrails through the lens of representation similarity between upstream alignment datasets and downstream fine-tuning tasks. Our experiments demonstrate that high similarity between these datasets significantly weakens safety guardrails, making models more susceptible to jailbreaks. Conversely, low similarity between these two types of datasets yields substantially more robust models and thus reduces harmfulness score by up to 10.33%. By highlighting the importance of upstream dataset design in the building of durable safety guardrails and reducing real-world vulnerability to jailbreak attacks, these findings offer actionable insights for fine-tuning service providers.
When Does Visual Prompting Outperform Linear Probing for Vision-Language Models? A Likelihood Perspective
Sep 04, 2024



Adapting pre-trained models to new tasks can exhibit varying effectiveness across datasets. Visual prompting, a state-of-the-art parameter-efficient transfer learning method, can significantly improve the performance of out-of-distribution tasks. On the other hand, linear probing, a standard transfer learning method, can sometimes become the best approach. We propose a log-likelihood ratio (LLR) approach to analyze the comparative benefits of visual prompting and linear probing. By employing the LLR score alongside resource-efficient visual prompts approximations, our cost-effective measure attains up to a 100-fold reduction in run time compared to full training, while achieving prediction accuracies up to 91%. The source code is available at https://github.com/IBM/VP-LLR.
AutoVP: An Automated Visual Prompting Framework and Benchmark
Oct 12, 2023

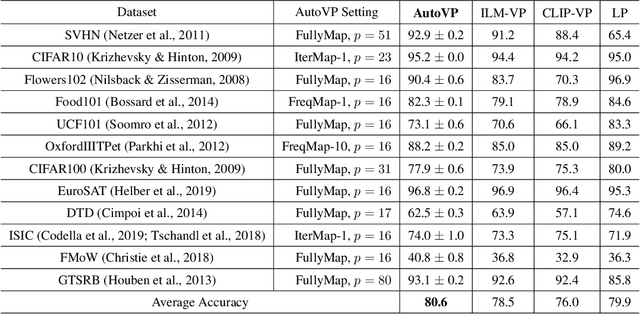

Visual prompting (VP) is an emerging parameter-efficient fine-tuning approach to adapting pre-trained vision models to solve various downstream image-classification tasks. However, there has hitherto been little systematic study of the design space of VP and no clear benchmark for evaluating its performance. To bridge this gap, we propose AutoVP, an end-to-end expandable framework for automating VP design choices, along with 12 downstream image-classification tasks that can serve as a holistic VP-performance benchmark. Our design space covers 1) the joint optimization of the prompts; 2) the selection of pre-trained models, including image classifiers and text-image encoders; and 3) model output mapping strategies, including nonparametric and trainable label mapping. Our extensive experimental results show that AutoVP outperforms the best-known current VP methods by a substantial margin, having up to 6.7% improvement in accuracy; and attains a maximum performance increase of 27.5% compared to linear-probing (LP) baseline. AutoVP thus makes a two-fold contribution: serving both as an efficient tool for hyperparameter tuning on VP design choices, and as a comprehensive benchmark that can reasonably be expected to accelerate VP's development. The source code is available at https://github.com/IBM/AutoVP.
NeuralFuse: Learning to Improve the Accuracy of Access-Limited Neural Network Inference in Low-Voltage Regimes
Jun 29, 2023Deep neural networks (DNNs) have become ubiquitous in machine learning, but their energy consumption remains a notable issue. Lowering the supply voltage is an effective strategy for reducing energy consumption. However, aggressively scaling down the supply voltage can lead to accuracy degradation due to random bit flips in static random access memory (SRAM) where model parameters are stored. To address this challenge, we introduce NeuralFuse, a novel add-on module that addresses the accuracy-energy tradeoff in low-voltage regimes by learning input transformations to generate error-resistant data representations. NeuralFuse protects DNN accuracy in both nominal and low-voltage scenarios. Moreover, NeuralFuse is easy to implement and can be readily applied to DNNs with limited access, such as non-configurable hardware or remote access to cloud-based APIs. Experimental results demonstrate that, at a 1% bit error rate, NeuralFuse can reduce SRAM memory access energy by up to 24% while improving accuracy by up to 57%. To the best of our knowledge, this is the first model-agnostic approach (i.e., no model retraining) to address low-voltage-induced bit errors. The source code is available at https://github.com/IBM/NeuralFuse.
NCTV: Neural Clamping Toolkit and Visualization for Neural Network Calibration
Nov 29, 2022


With the advancement of deep learning technology, neural networks have demonstrated their excellent ability to provide accurate predictions in many tasks. However, a lack of consideration for neural network calibration will not gain trust from humans, even for high-accuracy models. In this regard, the gap between the confidence of the model's predictions and the actual correctness likelihood must be bridged to derive a well-calibrated model. In this paper, we introduce the Neural Clamping Toolkit, the first open-source framework designed to help developers employ state-of-the-art model-agnostic calibrated models. Furthermore, we provide animations and interactive sections in the demonstration to familiarize researchers with calibration in neural networks. A Colab tutorial on utilizing our toolkit is also introduced.
CARBEN: Composite Adversarial Robustness Benchmark
Jul 16, 2022



Prior literature on adversarial attack methods has mainly focused on attacking with and defending against a single threat model, e.g., perturbations bounded in Lp ball. However, multiple threat models can be combined into composite perturbations. One such approach, composite adversarial attack (CAA), not only expands the perturbable space of the image, but also may be overlooked by current modes of robustness evaluation. This paper demonstrates how CAA's attack order affects the resulting image, and provides real-time inferences of different models, which will facilitate users' configuration of the parameters of the attack level and their rapid evaluation of model prediction. A leaderboard to benchmark adversarial robustness against CAA is also introduced.
Towards Compositional Adversarial Robustness: Generalizing Adversarial Training to Composite Semantic Perturbations
Feb 09, 2022Model robustness against adversarial examples of single perturbation type such as the $\ell_{p}$-norm has been widely studied, yet its generalization to more realistic scenarios involving multiple semantic perturbations and their composition remains largely unexplored. In this paper, we firstly propose a novel method for generating composite adversarial examples. By utilizing component-wise projected gradient descent and automatic attack-order scheduling, our method can find the optimal attack composition. We then propose \textbf{generalized adversarial training} (\textbf{GAT}) to extend model robustness from $\ell_{p}$-norm to composite semantic perturbations, such as the combination of Hue, Saturation, Brightness, Contrast, and Rotation. The results on ImageNet and CIFAR-10 datasets show that GAT can be robust not only to any single attack but also to any combination of multiple attacks. GAT also outperforms baseline $\ell_{\infty}$-norm bounded adversarial training approaches by a significant margin.