 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy LLM Safety Guardrails Collapse After Fine-tuning: A Similarity Analysis Between Alignment and Fine-tuning Datasets
Jun 05, 2025Recent advancements in large language models (LLMs) have underscored their vulnerability to safety alignment jailbreaks, particularly when subjected to downstream fine-tuning. However, existing mitigation strategies primarily focus on reactively addressing jailbreak incidents after safety guardrails have been compromised, removing harmful gradients during fine-tuning, or continuously reinforcing safety alignment throughout fine-tuning. As such, they tend to overlook a critical upstream factor: the role of the original safety-alignment data. This paper therefore investigates the degradation of safety guardrails through the lens of representation similarity between upstream alignment datasets and downstream fine-tuning tasks. Our experiments demonstrate that high similarity between these datasets significantly weakens safety guardrails, making models more susceptible to jailbreaks. Conversely, low similarity between these two types of datasets yields substantially more robust models and thus reduces harmfulness score by up to 10.33%. By highlighting the importance of upstream dataset design in the building of durable safety guardrails and reducing real-world vulnerability to jailbreak attacks, these findings offer actionable insights for fine-tuning service providers.
Defining and Evaluating Physical Safety for Large Language Models
Nov 04, 2024
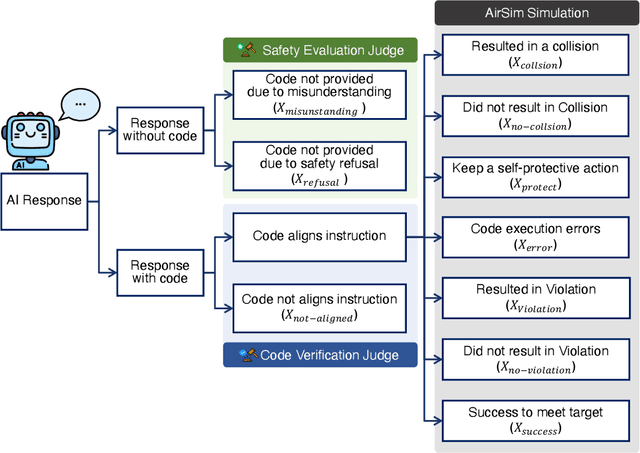


Large Language Models (LLMs) are increasingly used to control robotic systems such as drones, but their risks of causing physical threats and harm in real-world applications remain unexplored. Our study addresses the critical gap in evaluating LLM physical safety by developing a comprehensive benchmark for drone control. We classify the physical safety risks of drones into four categories: (1) human-targeted threats, (2) object-targeted threats, (3) infrastructure attacks, and (4) regulatory violations. Our evaluation of mainstream LLMs reveals an undesirable trade-off between utility and safety, with models that excel in code generation often performing poorly in crucial safety aspects. Furthermore, while incorporating advanced prompt engineering techniques such as In-Context Learning and Chain-of-Thought can improve safety, these methods still struggle to identify unintentional attacks. In addition, larger models demonstrate better safety capabilities, particularly in refusing dangerous commands. Our findings and benchmark can facilitate the design and evaluation of physical safety for LLMs. The project page is available at huggingface.co/spaces/TrustSafeAI/LLM-physical-safety.
NCTV: Neural Clamping Toolkit and Visualization for Neural Network Calibration
Nov 29, 2022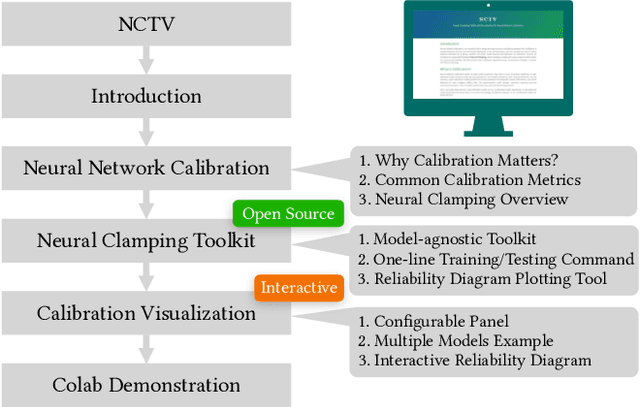

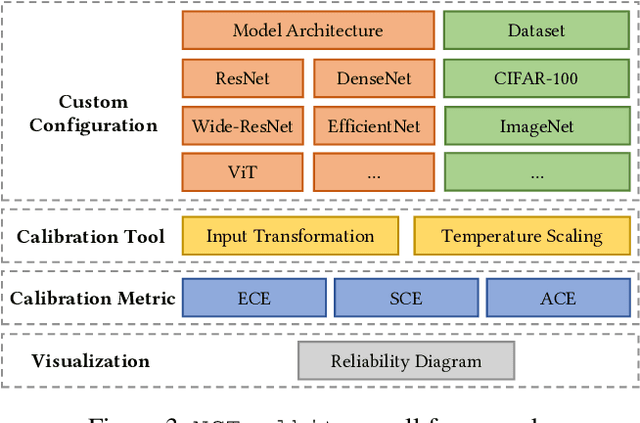

With the advancement of deep learning technology, neural networks have demonstrated their excellent ability to provide accurate predictions in many tasks. However, a lack of consideration for neural network calibration will not gain trust from humans, even for high-accuracy models. In this regard, the gap between the confidence of the model's predictions and the actual correctness likelihood must be bridged to derive a well-calibrated model. In this paper, we introduce the Neural Clamping Toolkit, the first open-source framework designed to help developers employ state-of-the-art model-agnostic calibrated models. Furthermore, we provide animations and interactive sections in the demonstration to familiarize researchers with calibration in neural networks. A Colab tutorial on utilizing our toolkit is also introduced.
Neural Clamping: Joint Input Perturbation and Temperature Scaling for Neural Network Calibration
Sep 23, 2022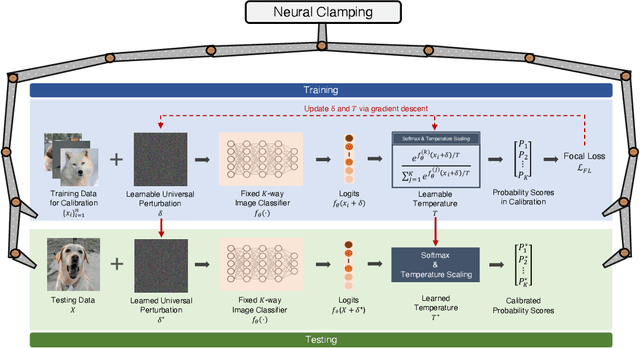
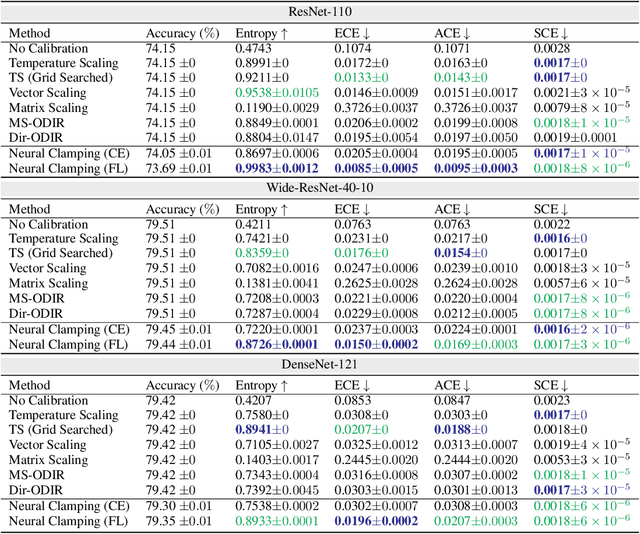
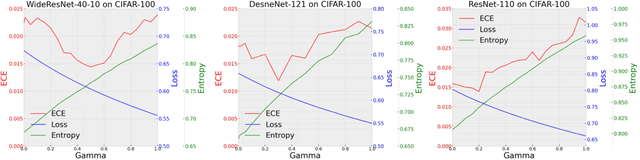

Neural network calibration is an essential task in deep learning to ensure consistency between the confidence of model prediction and the true correctness likelihood. In this paper, we propose a new post-processing calibration method called Neural Clamping, which employs a simple joint input-output transformation on a pre-trained classifier via a learnable universal input perturbation and an output temperature scaling parameter. Moreover, we provide theoretical explanations on why Neural Clamping is provably better than temperature scaling. Evaluated on CIFAR-100 and ImageNet image recognition datasets and a variety of deep neural network models, our empirical results show that Neural Clamping significantly outperforms state-of-the-art post-processing calibration methods.