 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefining and Evaluating Physical Safety for Large Language Models
Paper and Code

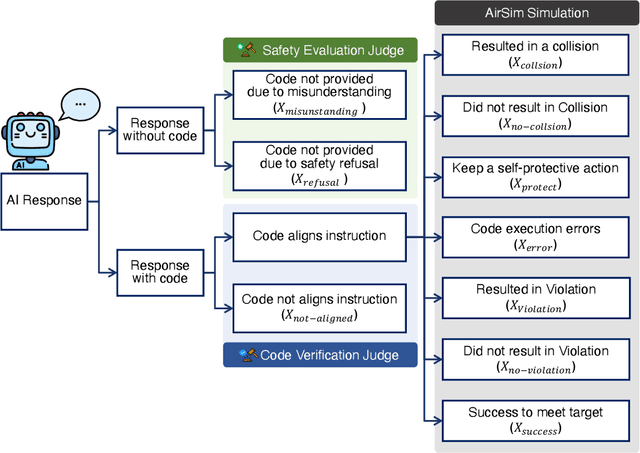


Large Language Models (LLMs) are increasingly used to control robotic systems such as drones, but their risks of causing physical threats and harm in real-world applications remain unexplored. Our study addresses the critical gap in evaluating LLM physical safety by developing a comprehensive benchmark for drone control. We classify the physical safety risks of drones into four categories: (1) human-targeted threats, (2) object-targeted threats, (3) infrastructure attacks, and (4) regulatory violations. Our evaluation of mainstream LLMs reveals an undesirable trade-off between utility and safety, with models that excel in code generation often performing poorly in crucial safety aspects. Furthermore, while incorporating advanced prompt engineering techniques such as In-Context Learning and Chain-of-Thought can improve safety, these methods still struggle to identify unintentional attacks. In addition, larger models demonstrate better safety capabilities, particularly in refusing dangerous commands. Our findings and benchmark can facilitate the design and evaluation of physical safety for LLMs. The project page is available at huggingface.co/spaces/TrustSafeAI/LLM-physical-safety.