 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimRAG: Self-Improving Retrieval-Augmented Generation for Adapting Large Language Models to Specialized Domains
Paper and Code
Oct 23, 2024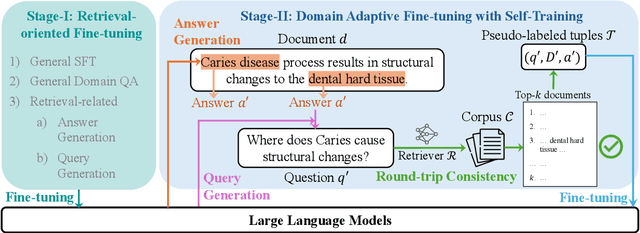
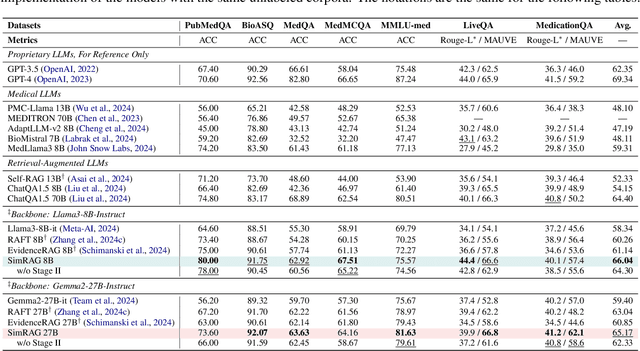
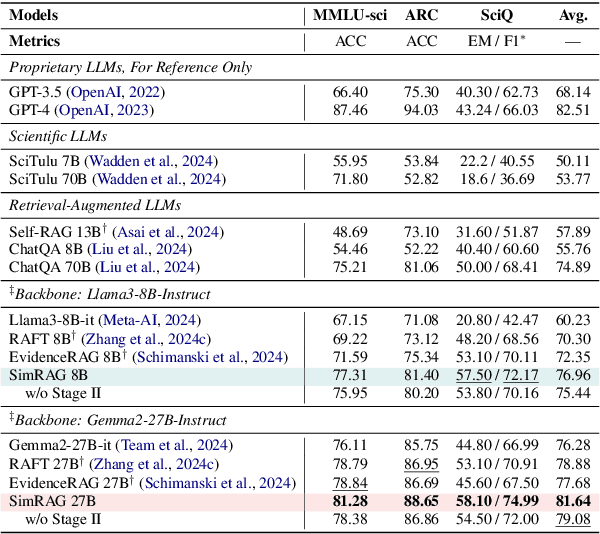
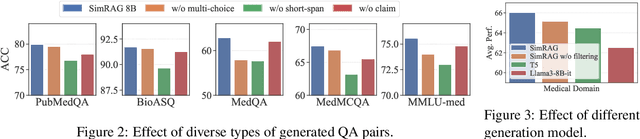
Retrieval-augmented generation (RAG) enhances the question-answering (QA) abilities of large language models (LLMs) by integrating external knowledge. However, adapting general-purpose RAG systems to specialized fields such as science and medicine poses unique challenges due to distribution shifts and limited access to domain-specific data. To tackle this, we propose SimRAG, a self-training approach that equips the LLM with joint capabilities of question answering and question generation for domain adaptation. Our method first fine-tunes the LLM on instruction-following, question-answering, and search-related data. Then, it prompts the same LLM to generate diverse domain-relevant questions from unlabeled corpora, with an additional filtering strategy to retain high-quality synthetic examples. By leveraging these synthetic examples, the LLM can improve their performance on domain-specific RAG tasks. Experiments on 11 datasets, spanning two backbone sizes and three domains, demonstrate that SimRAG outperforms baselines by 1.2\%--8.6\%.