 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Expressive Encoders Necessary for Discrete Graph Generation?
Mar 09, 2026Discrete graph generation has emerged as a powerful paradigm for modeling graph data, often relying on highly expressive neural backbones such as transformers or higher-order architectures. We revisit this design choice by introducing GenGNN, a modular message-passing framework for graph generation. Diffusion models with GenGNN achieve more than 90% validity on Tree and Planar datasets, within margins of graph transformers, at 2-5x faster inference speed. For molecule generation, DiGress with a GenGNN backbone achieves 99.49% Validity. A systematic ablation study shows the benefit provided by each GenGNN component, indicating the need for residual connections to mitigate oversmoothing on complicated graph-structure. Through scaling analyses, we apply a principled metric-space view to investigate learned diffusion representations and uncover whether GNNs can be expressive neural backbones for discrete diffusion.
Subgraph Generation for Generalizing on Out-of-Distribution Links
Jul 15, 2025Graphs Neural Networks (GNNs) demonstrate high-performance on the link prediction (LP) task. However, these models often rely on all dataset samples being drawn from the same distribution. In addition, graph generative models (GGMs) show a pronounced ability to generate novel output graphs. Despite this, GGM applications remain largely limited to domain-specific tasks. To bridge this gap, we propose FLEX as a GGM framework which leverages two mechanism: (1) structurally-conditioned graph generation, and (2) adversarial co-training between an auto-encoder and GNN. As such, FLEX ensures structural-alignment between sample distributions to enhance link-prediction performance in out-of-distribution (OOD) scenarios. Notably, FLEX does not require expert knowledge to function in different OOD scenarios. Numerous experiments are conducted in synthetic and real-world OOD settings to demonstrate FLEX's performance-enhancing ability, with further analysis for understanding the effects of graph data augmentation on link structures. The source code is available here: https://github.com/revolins/FlexOOD.
Towards Better Benchmark Datasets for Inductive Knowledge Graph Completion
Jun 14, 2024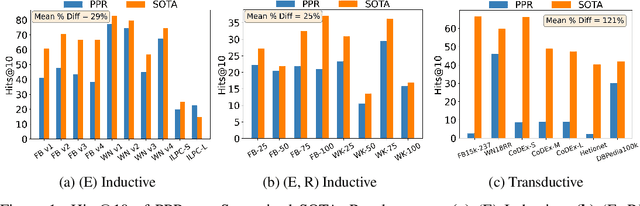

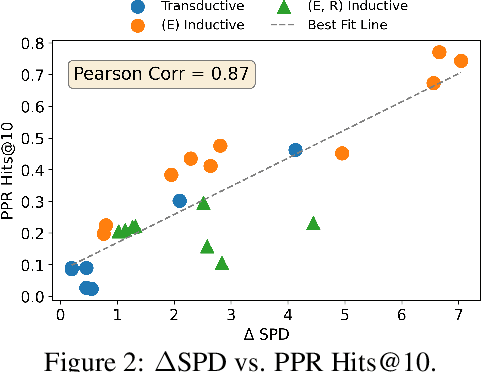
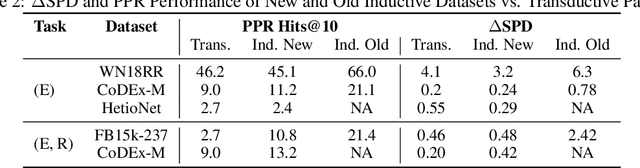
Knowledge Graph Completion (KGC) attempts to predict missing facts in a Knowledge Graph (KG). Recently, there's been an increased focus on designing KGC methods that can excel in the {\it inductive setting}, where a portion or all of the entities and relations seen in inference are unobserved during training. Numerous benchmark datasets have been proposed for inductive KGC, all of which are subsets of existing KGs used for transductive KGC. However, we find that the current procedure for constructing inductive KGC datasets inadvertently creates a shortcut that can be exploited even while disregarding the relational information. Specifically, we observe that the Personalized PageRank (PPR) score can achieve strong or near SOTA performance on most inductive datasets. In this paper, we study the root cause of this problem. Using these insights, we propose an alternative strategy for constructing inductive KGC datasets that helps mitigate the PPR shortcut. We then benchmark multiple popular methods using the newly constructed datasets and analyze their performance. The new benchmark datasets help promote a better understanding of the capabilities and challenges of inductive KGC by removing any shortcuts that obfuscate performance.
Understanding the Generalizability of Link Predictors Under Distribution Shifts on Graphs
Jun 13, 2024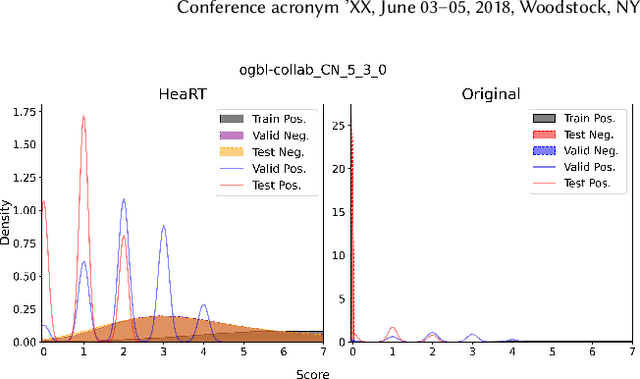
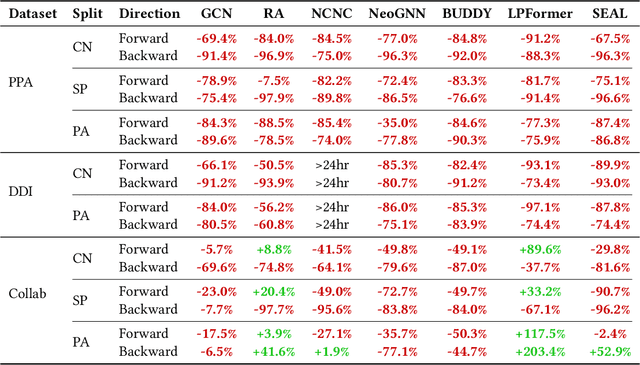
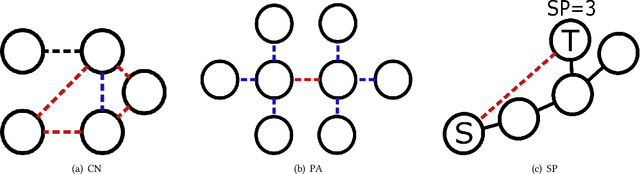
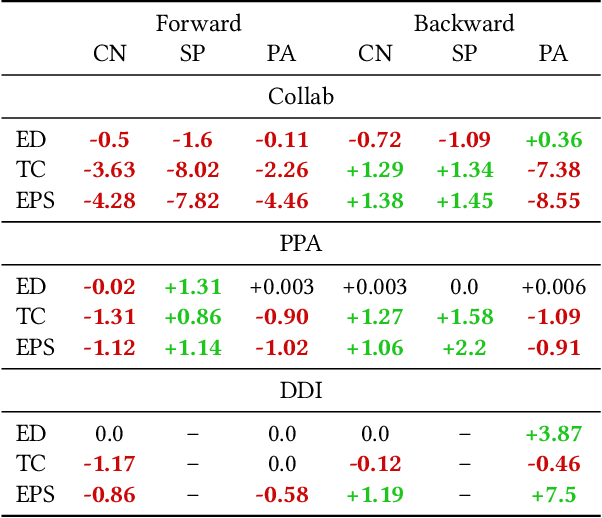
Recently, multiple models proposed for link prediction (LP) demonstrate impressive results on benchmark datasets. However, many popular benchmark datasets often assume that dataset samples are drawn from the same distribution (i.e., IID samples). In real-world situations, this assumption is often incorrect; since uncontrolled factors may lead train and test samples to come from separate distributions. To tackle the distribution shift problem, recent work focuses on creating datasets that feature distribution shifts and designing generalization methods that perform well on the new data. However, those studies only consider distribution shifts that affect {\it node-} and {\it graph-level} tasks, thus ignoring link-level tasks. Furthermore, relatively few LP generalization methods exist. To bridge this gap, we introduce a set of LP-specific data splits which utilizes structural properties to induce a controlled distribution shift. We verify the shift's effect empirically through evaluation of different SOTA LP methods and subsequently couple these methods with generalization techniques. Interestingly, LP-specific methods frequently generalize poorly relative to heuristics or basic GNN methods. Finally, this work provides analysis to uncover insights for enhancing LP generalization. Our code is available at: \href{https://github.com/revolins/LPStructGen}{https://github.com/revolins/LPStructGen}