 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnCBP: A New Benchmark Dataset for Finer-Grained Cultural Background Prediction in English
Paper and Code
Mar 28, 2022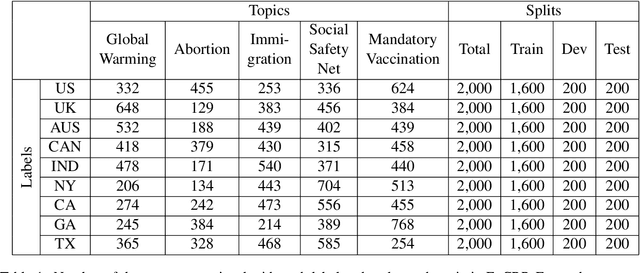


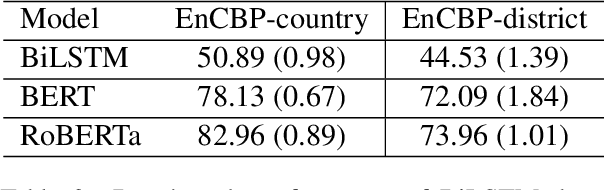
While cultural backgrounds have been shown to affect linguistic expressions, existing natural language processing (NLP) research on culture modeling is overly coarse-grained and does not examine cultural differences among speakers of the same language. To address this problem and augment NLP models with cultural background features, we collect, annotate, manually validate, and benchmark EnCBP, a finer-grained news-based cultural background prediction dataset in English. Through language modeling (LM) evaluations and manual analyses, we confirm that there are noticeable differences in linguistic expressions among five English-speaking countries and across four states in the US. Additionally, our evaluations on nine syntactic (CoNLL-2003), semantic (PAWS-Wiki, QNLI, STS-B, and RTE), and psycholinguistic tasks (SST-5, SST-2, Emotion, and Go-Emotions) show that, while introducing cultural background information does not benefit the Go-Emotions task due to text domain conflicts, it noticeably improves deep learning (DL) model performance on other tasks. Our findings strongly support the importance of cultural background modeling to a wide variety of NLP tasks and demonstrate the applicability of EnCBP in culture-related research.