 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObserve Less, Understand More: Cost-aware Cross-scale Observation for Remote Sensing Understanding
Apr 13, 2026Remote sensing understanding inherently requires multi-resolution observation, since different targets and application tasks demand different levels of spatial detail. While low-resolution (LR) imagery enables efficient global observation, high-resolution (HR) imagery provides critical local details at much higher acquisition cost and limited coverage. This motivates a cross-scale sensing strategy that selectively acquires HR imagery from LR-based global perception to improve task performance under constrained cost. Existing methods for HR sampling methods typically make selection decisions from isolated LR patches, which ignore fine-grained intra-patch importance and cross-patch contextual interactions, leading to fragmented feature representation and suboptimal scene reasoning under sparse HR observations. To address this issue, we formulate cross-scale remote sensing understanding as a unified cost-aware problem that couples fine-grained HR sampling with cross-patch representation prediction, enabling more effective task reasoning with fewer HR observations. Furthermore, we present GL-10M, a large-scale benchmark of 10 million spatially aligned multi-resolution images, enabling systematic evaluation of budget-constrained cross-scale reasoning in remote sensing. Extensive experiments on recognition and retrieval tasks show that our method consistently achieves a superior performance-cost trade-off.
Multi-Agents Based on Large Language Models for Knowledge-based Visual Question Answering
Dec 24, 2024

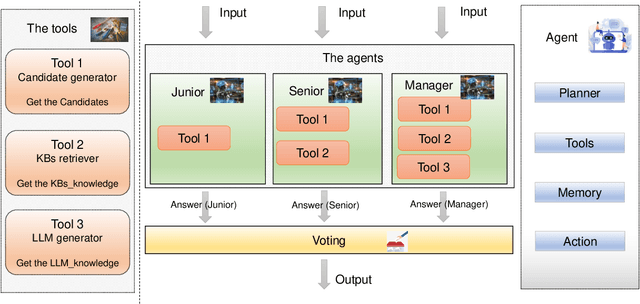

Large Language Models (LLMs) have achieved impressive results in knowledge-based Visual Question Answering (VQA). However existing methods still have challenges: the inability to use external tools autonomously, and the inability to work in teams. Humans tend to know whether they need to use external tools when they encounter a new question, e.g., they tend to be able to give a direct answer to a familiar question, whereas they tend to use tools such as search engines when they encounter an unfamiliar question. In addition, humans also tend to collaborate and discuss with others to get better answers. Inspired by this, we propose the multi-agent voting framework. We design three LLM-based agents that simulate different levels of staff in a team, and assign the available tools according to the levels. Each agent provides the corresponding answer, and finally all the answers provided by the agents are voted to get the final answer. Experiments on OK-VQA and A-OKVQA show that our approach outperforms other baselines by 2.2 and 1.0, respectively.
Robust N-1 secure HV Grid Flexibility Estimation for TSO-DSO coordinated Congestion Management with Deep Reinforcement Learning
Nov 10, 2022Nowadays, the PQ flexibility from the distributed energy resources (DERs) in the high voltage (HV) grids plays a more critical and significant role in grid congestion management in TSO grids. This work proposed a multi-stage deep reinforcement learning approach to estimate the PQ flexibility (PQ area) at the TSO-DSO interfaces and identifies the DER PQ setpoints for each operating point in a way, that DERs in the meshed HV grid can be coordinated to offer flexibility for the transmission grid. In the estimation process, we consider the steady-state grid limits and the robustness in the resulting voltage profile against uncertainties and the N-1 security criterion regarding thermal line loading, essential for real-life grid operational planning applications. Using deep reinforcement learning (DRL) for PQ flexibility estimation is the first of its kind. Furthermore, our approach of considering N-1 security criterion for meshed grids and robustness against uncertainty directly in the optimization tasks offers a new perspective besides the common relaxation schema in finding a solution with mathematical optimal power flow (OPF). Finally, significant improvements in the computational efficiency in estimation PQ area are the highlights of the proposed method.