 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment of LLM Responses to End-user Security Questions
Nov 21, 2024
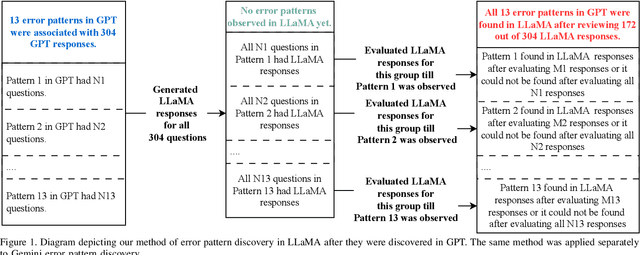


Answering end user security questions is challenging. While large language models (LLMs) like GPT, LLAMA, and Gemini are far from error-free, they have shown promise in answering a variety of questions outside of security. We studied LLM performance in the area of end user security by qualitatively evaluating 3 popular LLMs on 900 systematically collected end user security questions. While LLMs demonstrate broad generalist ``knowledge'' of end user security information, there are patterns of errors and limitations across LLMs consisting of stale and inaccurate answers, and indirect or unresponsive communication styles, all of which impacts the quality of information received. Based on these patterns, we suggest directions for model improvement and recommend user strategies for interacting with LLMs when seeking assistance with security.