 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Turn: Real-World Turning Angle Estimation for Parkinson's Disease Severity Assessment
Aug 15, 2024People with Parkinson's Disease (PD) often experience progressively worsening gait, including changes in how they turn around, as the disease progresses. Existing clinical rating tools are not capable of capturing hour-by-hour variations of PD symptoms, as they are confined to brief assessments within clinic settings. Measuring real-world gait turning angles continuously and passively is a component step towards using gait characteristics as sensitive indicators of disease progression in PD. This paper presents a deep learning-based approach to automatically quantify turning angles by extracting 3D skeletons from videos and calculating the rotation of hip and knee joints. We utilise state-of-the-art human pose estimation models, Fastpose and Strided Transformer, on a total of 1386 turning video clips from 24 subjects (12 people with PD and 12 healthy control volunteers), trimmed from a PD dataset of unscripted free-living videos in a home-like setting (Turn-REMAP). We also curate a turning video dataset, Turn-H3.6M, from the public Human3.6M human pose benchmark with 3D ground truth, to further validate our method. Previous gait research has primarily taken place in clinics or laboratories evaluating scripted gait outcomes, but this work focuses on real-world settings where complexities exist, such as baggy clothing and poor lighting. Due to difficulties in obtaining accurate ground truth data in a free-living setting, we quantise the angle into the nearest bin $45^\circ$ based on the manual labelling of expert clinicians. Our method achieves a turning calculation accuracy of 41.6%, a Mean Absolute Error (MAE) of 34.7{\deg}, and a weighted precision WPrec of 68.3% for Turn-REMAP. This is the first work to explore the use of single monocular camera data to quantify turns by PD patients in a home setting.
Inertial Hallucinations -- When Wearable Inertial Devices Start Seeing Things
Jul 14, 2022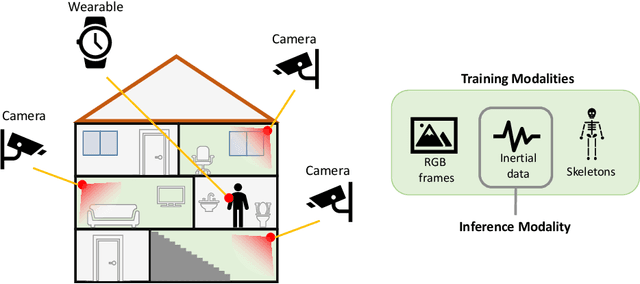

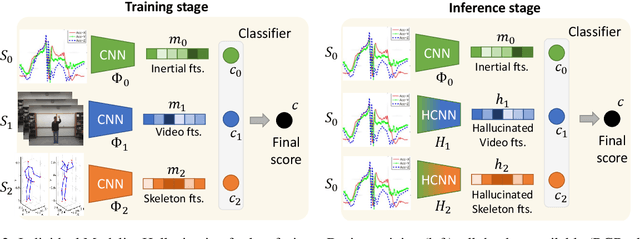
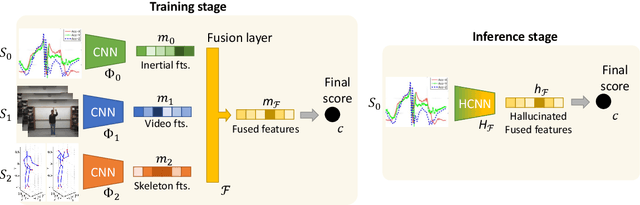
We propose a novel approach to multimodal sensor fusion for Ambient Assisted Living (AAL) which takes advantage of learning using privileged information (LUPI). We address two major shortcomings of standard multimodal approaches, limited area coverage and reduced reliability. Our new framework fuses the concept of modality hallucination with triplet learning to train a model with different modalities to handle missing sensors at inference time. We evaluate the proposed model on inertial data from a wearable accelerometer device, using RGB videos and skeletons as privileged modalities, and show an improvement of accuracy of an average 6.6% on the UTD-MHAD dataset and an average 5.5% on the Berkeley MHAD dataset, reaching a new state-of-the-art for inertial-only classification accuracy on these datasets. We validate our framework through several ablation studies.
Temporal-Relational CrossTransformers for Few-Shot Action Recognition
Jan 15, 2021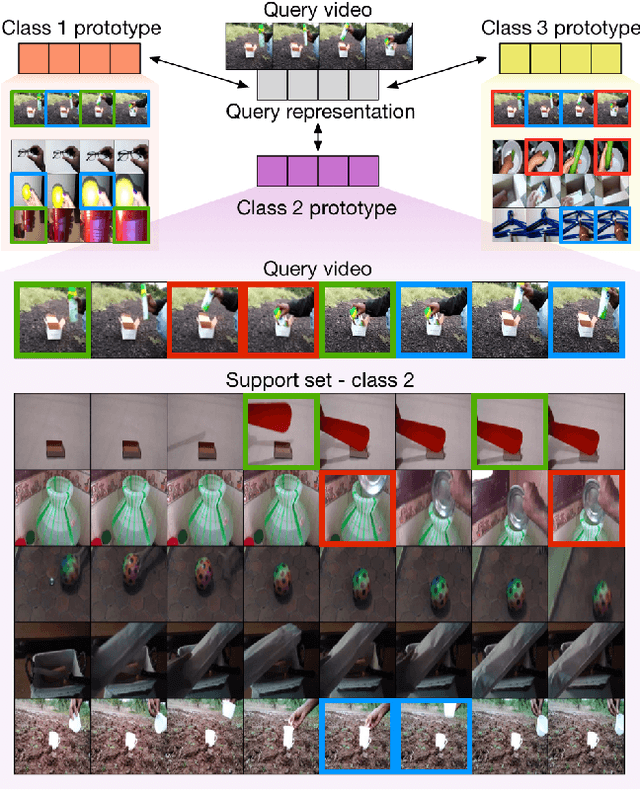
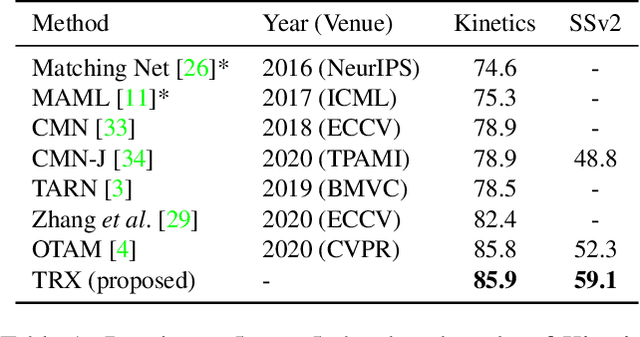
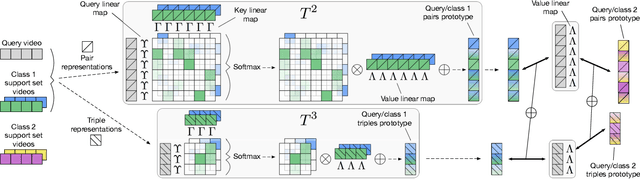
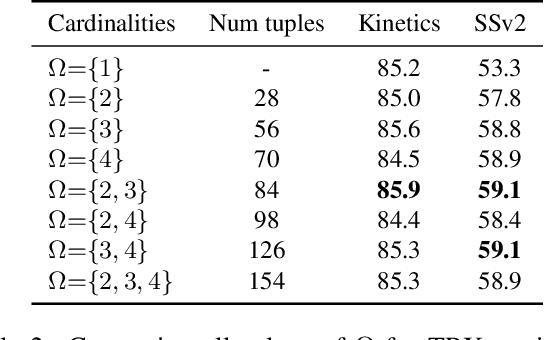
We propose a novel approach to few-shot action recognition, finding temporally-corresponding frame tuples between the query and videos in the support set. Distinct from previous few-shot action recognition works, we construct class prototypes using the CrossTransformer attention mechanism to observe relevant sub-sequences of all support videos, rather than using class averages or single best matches. Video representations are formed from ordered tuples of varying numbers of frames, which allows sub-sequences of actions at different speeds and temporal offsets to be compared. Our proposed Temporal-Relational CrossTransformers achieve state-of-the-art results on both Kinetics and Something-Something V2 (SSv2), outperforming prior work on SSv2 by a wide margin (6.8%) due to the method's ability to model temporal relations. A detailed ablation showcases the importance of matching to multiple support set videos and learning higher-order relational CrossTransformers. Code is available at https://github.com/tobyperrett/trx
Meta-Learning with Context-Agnostic Initialisations
Jul 29, 2020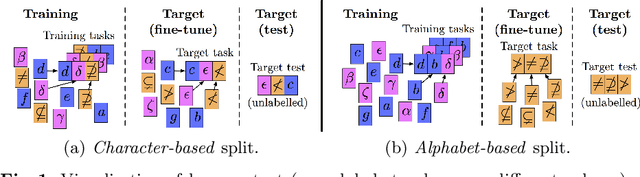
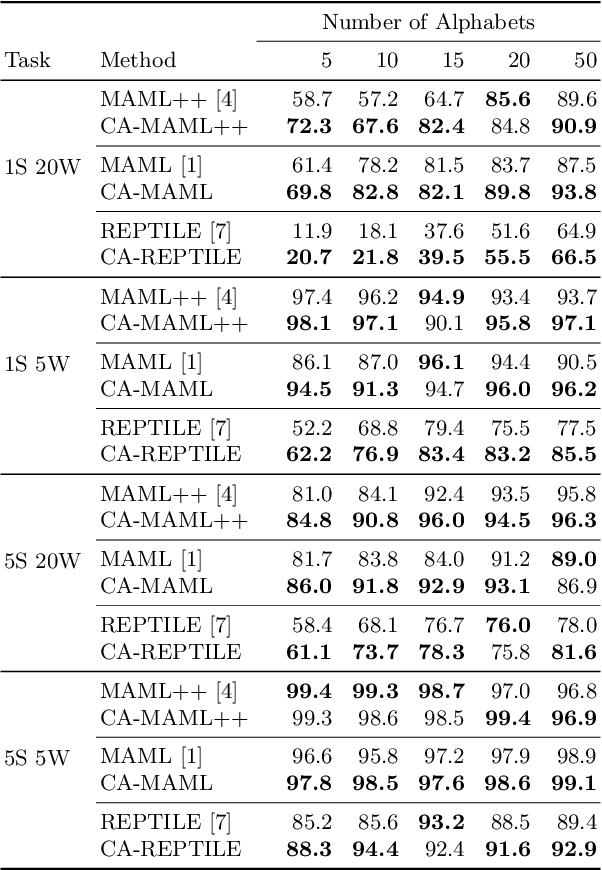
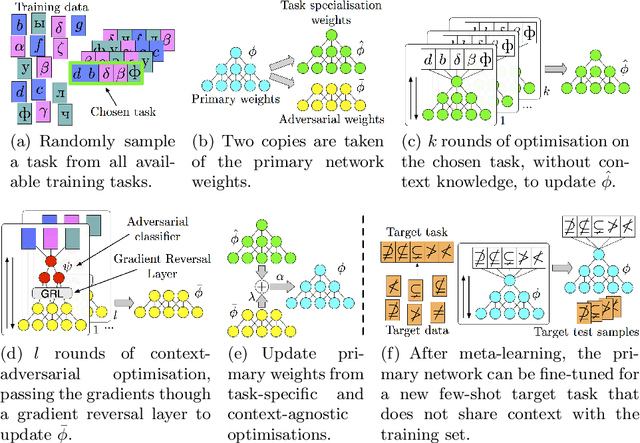
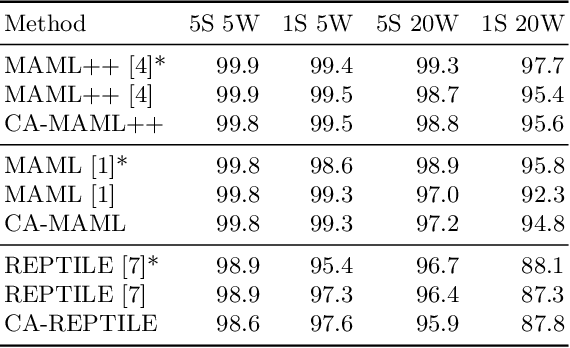
Meta-learning approaches have addressed few-shot problems by finding initialisations suited for fine-tuning to target tasks. Often there are additional properties within training data (which we refer to as context), not relevant to the target task, which act as a distractor to meta-learning, particularly when the target task contains examples from a novel context not seen during training. We address this oversight by incorporating a context-adversarial component into the meta-learning process. This produces an initialisation for fine-tuning to target which is both context-agnostic and task-generalised. We evaluate our approach on three commonly used meta-learning algorithms and two problems. We demonstrate our context-agnostic meta-learning improves results in each case. First, we report on Omniglot few-shot character classification, using alphabets as context. An average improvement of 4.3% is observed across methods and tasks when classifying characters from an unseen alphabet. Second, we evaluate on a dataset for personalised energy expenditure predictions from video, using participant knowledge as context. We demonstrate that context-agnostic meta-learning decreases the average mean square error by 30%.
Sit-to-Stand Analysis in the Wild using Silhouettes for Longitudinal Health Monitoring
Oct 03, 2019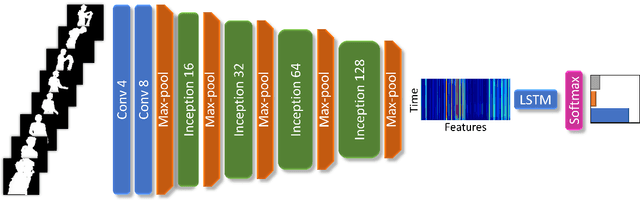

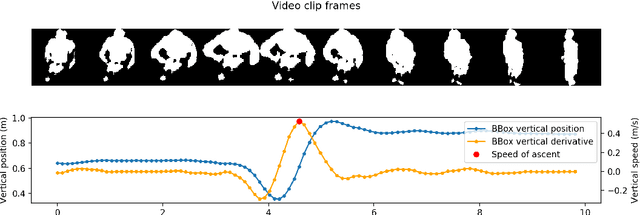

We present the first fully automated Sit-to-Stand or Stand-to-Sit (StS) analysis framework for long-term monitoring of patients in free-living environments using video silhouettes. Our method adopts a coarse-to-fine time localisation approach, where a deep learning classifier identifies possible StS sequences from silhouettes, and a smart peak detection stage provides fine localisation based on 3D bounding boxes. We tested our method on data from real homes of participants and monitored patients undergoing total hip or knee replacement. Our results show 94.4% overall accuracy in the coarse localisation and an error of 0.026 m/s in the speed of ascent measurement, highlighting important trends in the recuperation of patients who underwent surgery.
CaloriNet: From silhouettes to calorie estimation in private environments
Jun 21, 2018
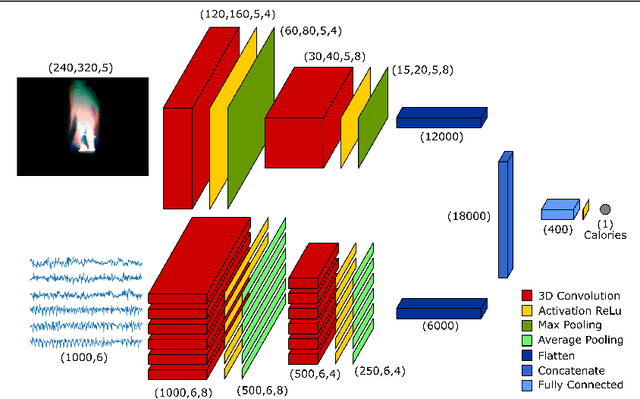

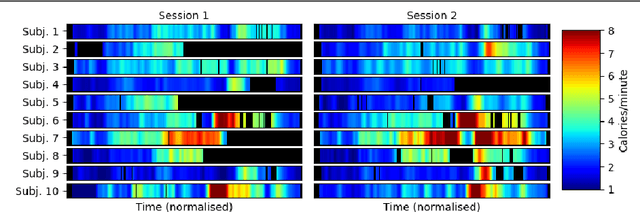
We propose a novel deep fusion architecture, CaloriNet, for the online estimation of energy expenditure for free living monitoring in private environments, where RGB data is discarded and replaced by silhouettes. Our fused convolutional neural network architecture is trainable end-to-end, to estimate calorie expenditure, using temporal foreground silhouettes alongside accelerometer data. The network is trained and cross-validated on a publicly available dataset, SPHERE_RGBD + Inertial_calorie. Results show state-of-the-art minimum error on the estimation of energy expenditure (calories per minute), outperforming alternative, standard and single-modal techniques.
Semantically Selective Augmentation for Deep Compact Person Re-Identification
Jun 18, 2018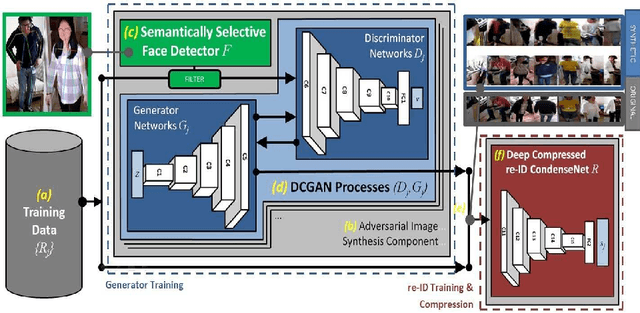
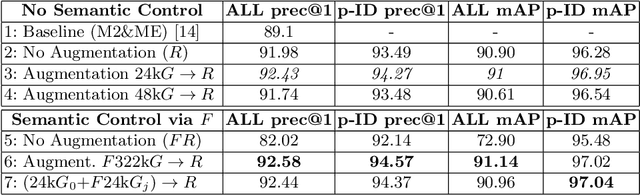

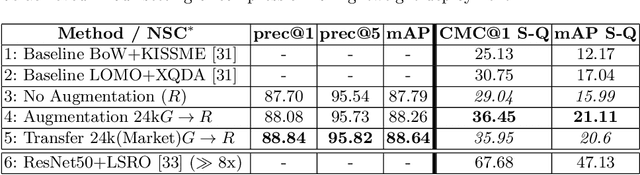
We present a deep person re-identification approach that combines semantically selective, deep data augmentation with clustering-based network compression to generate high performance, light and fast inference networks. In particular, we propose to augment limited training data via sampling from a deep convolutional generative adversarial network (DCGAN), whose discriminator is constrained by a semantic classifier to explicitly control the domain specificity of the generation process. Thereby, we encode information in the classifier network which can be utilized to steer adversarial synthesis, and which fuels our CondenseNet ID-network training. We provide a quantitative and qualitative analysis of the approach and its variants on a number of datasets, obtaining results that outperform the state-of-the-art on the LIMA dataset for long-term monitoring in indoor living spaces.