 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning with Context-Agnostic Initialisations
Paper and Code
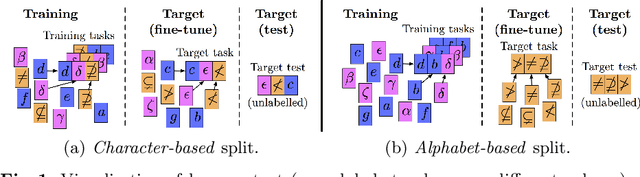
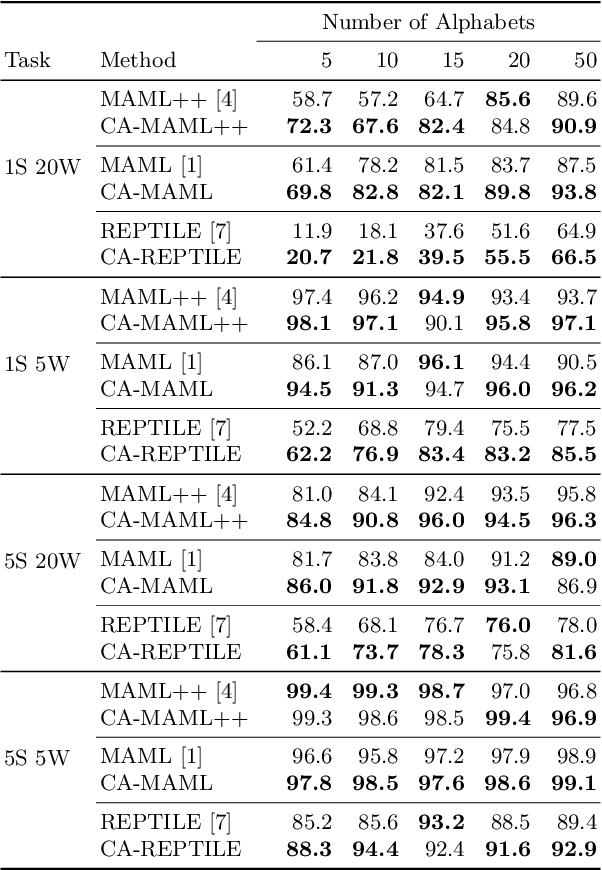
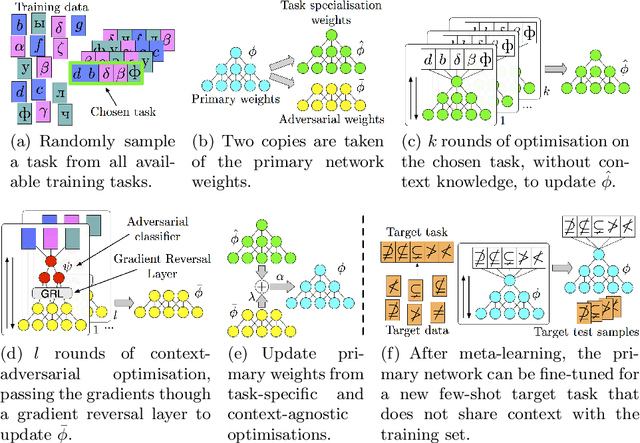
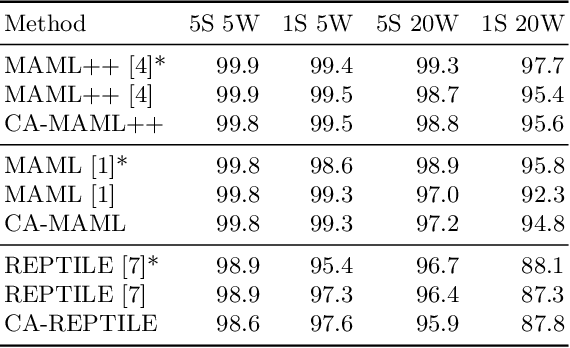
Meta-learning approaches have addressed few-shot problems by finding initialisations suited for fine-tuning to target tasks. Often there are additional properties within training data (which we refer to as context), not relevant to the target task, which act as a distractor to meta-learning, particularly when the target task contains examples from a novel context not seen during training. We address this oversight by incorporating a context-adversarial component into the meta-learning process. This produces an initialisation for fine-tuning to target which is both context-agnostic and task-generalised. We evaluate our approach on three commonly used meta-learning algorithms and two problems. We demonstrate our context-agnostic meta-learning improves results in each case. First, we report on Omniglot few-shot character classification, using alphabets as context. An average improvement of 4.3% is observed across methods and tasks when classifying characters from an unseen alphabet. Second, we evaluate on a dataset for personalised energy expenditure predictions from video, using participant knowledge as context. We demonstrate that context-agnostic meta-learning decreases the average mean square error by 30%.