 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal-Relational CrossTransformers for Few-Shot Action Recognition
Paper and Code
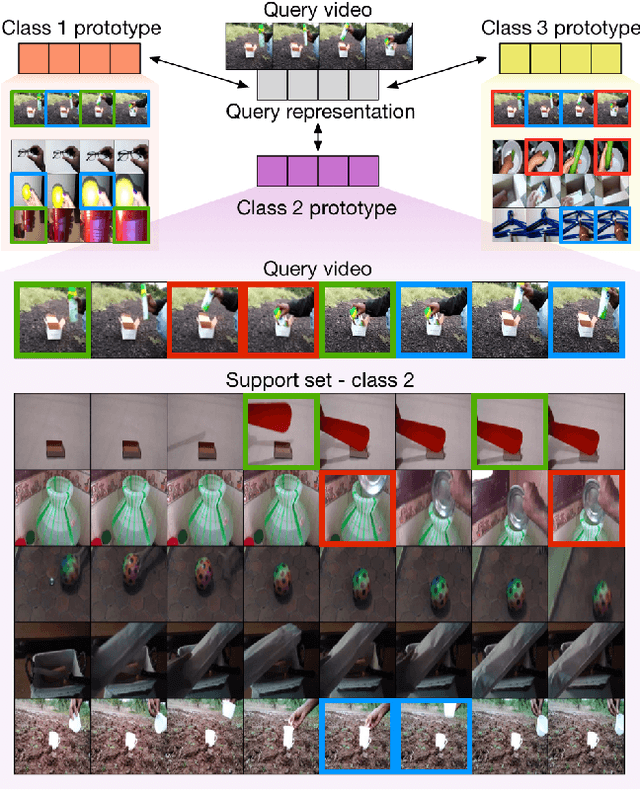
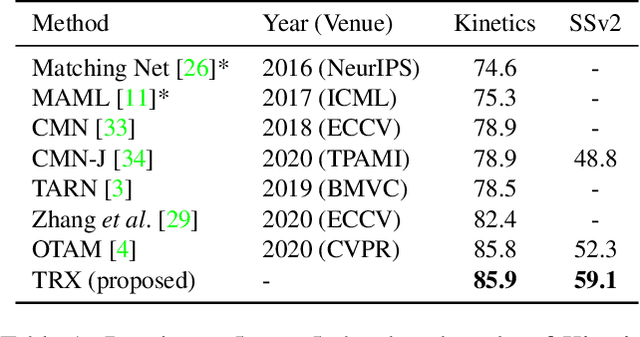
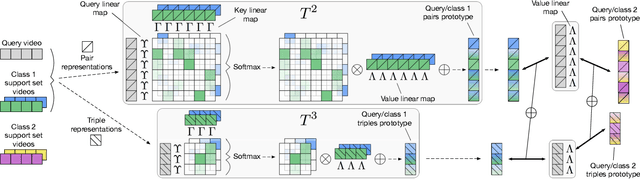
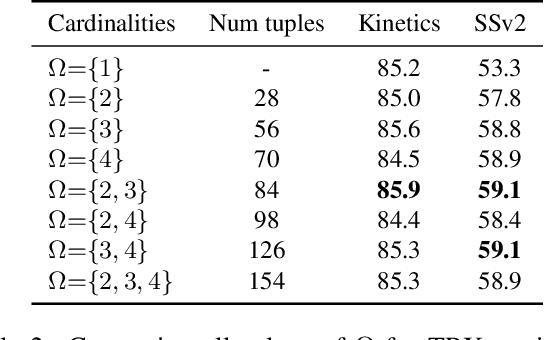
We propose a novel approach to few-shot action recognition, finding temporally-corresponding frame tuples between the query and videos in the support set. Distinct from previous few-shot action recognition works, we construct class prototypes using the CrossTransformer attention mechanism to observe relevant sub-sequences of all support videos, rather than using class averages or single best matches. Video representations are formed from ordered tuples of varying numbers of frames, which allows sub-sequences of actions at different speeds and temporal offsets to be compared. Our proposed Temporal-Relational CrossTransformers achieve state-of-the-art results on both Kinetics and Something-Something V2 (SSv2), outperforming prior work on SSv2 by a wide margin (6.8%) due to the method's ability to model temporal relations. A detailed ablation showcases the importance of matching to multiple support set videos and learning higher-order relational CrossTransformers. Code is available at https://github.com/tobyperrett/trx