 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Ensemble Model Compression using Knowledge Distillation
Paper and Code
Nov 15, 2020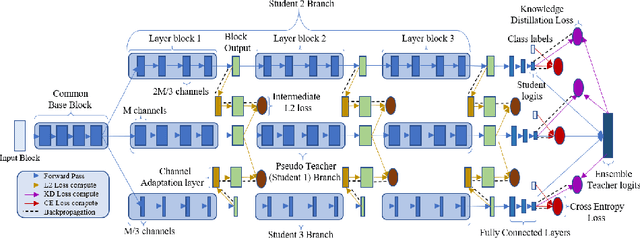
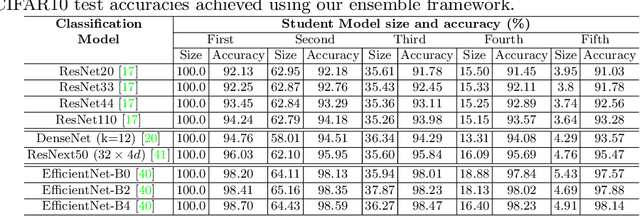
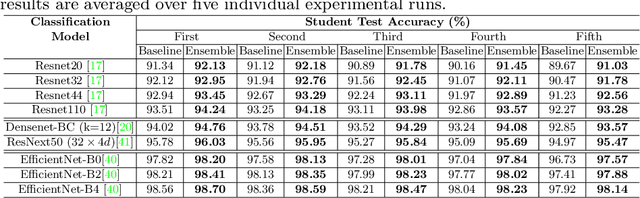

This paper presents a novel knowledge distillation based model compression framework consisting of a student ensemble. It enables distillation of simultaneously learnt ensemble knowledge onto each of the compressed student models. Each model learns unique representations from the data distribution due to its distinct architecture. This helps the ensemble generalize better by combining every model's knowledge. The distilled students and ensemble teacher are trained simultaneously without requiring any pretrained weights. Moreover, our proposed method can deliver multi-compressed students with single training, which is efficient and flexible for different scenarios. We provide comprehensive experiments using state-of-the-art classification models to validate our framework's effectiveness. Notably, using our framework a 97% compressed ResNet110 student model managed to produce a 10.64% relative accuracy gain over its individual baseline training on CIFAR100 dataset. Similarly a 95% compressed DenseNet-BC(k=12) model managed a 8.17% relative accuracy gain.