 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceLift: Semi-supervised 3D Facial Landmark Localization
May 30, 2024



3D facial landmark localization has proven to be of particular use for applications, such as face tracking, 3D face modeling, and image-based 3D face reconstruction. In the supervised learning case, such methods usually rely on 3D landmark datasets derived from 3DMM-based registration that often lack spatial definition alignment, as compared with that chosen by hand-labeled human consensus, e.g., how are eyebrow landmarks defined? This creates a gap between landmark datasets generated via high-quality 2D human labels and 3DMMs, and it ultimately limits their effectiveness. To address this issue, we introduce a novel semi-supervised learning approach that learns 3D landmarks by directly lifting (visible) hand-labeled 2D landmarks and ensures better definition alignment, without the need for 3D landmark datasets. To lift 2D landmarks to 3D, we leverage 3D-aware GANs for better multi-view consistency learning and in-the-wild multi-frame videos for robust cross-generalization. Empirical experiments demonstrate that our method not only achieves better definition alignment between 2D-3D landmarks but also outperforms other supervised learning 3D landmark localization methods on both 3DMM labeled and photogrammetric ground truth evaluation datasets. Project Page: https://davidcferman.github.io/FaceLift
Few-shot Geometry-Aware Keypoint Localization
Mar 30, 2023



Supervised keypoint localization methods rely on large manually labeled image datasets, where objects can deform, articulate, or occlude. However, creating such large keypoint labels is time-consuming and costly, and is often error-prone due to inconsistent labeling. Thus, we desire an approach that can learn keypoint localization with fewer yet consistently annotated images. To this end, we present a novel formulation that learns to localize semantically consistent keypoint definitions, even for occluded regions, for varying object categories. We use a few user-labeled 2D images as input examples, which are extended via self-supervision using a larger unlabeled dataset. Unlike unsupervised methods, the few-shot images act as semantic shape constraints for object localization. Furthermore, we introduce 3D geometry-aware constraints to uplift keypoints, achieving more accurate 2D localization. Our general-purpose formulation paves the way for semantically conditioned generative modeling and attains competitive or state-of-the-art accuracy on several datasets, including human faces, eyes, animals, cars, and never-before-seen mouth interior (teeth) localization tasks, not attempted by the previous few-shot methods. Project page: https://xingzhehe.github.io/FewShot3DKP/}{https://xingzhehe.github.io/FewShot3DKP/
* CVPR 2023
Multi-Domain Multi-Definition Landmark Localization for Small Datasets
Mar 19, 2022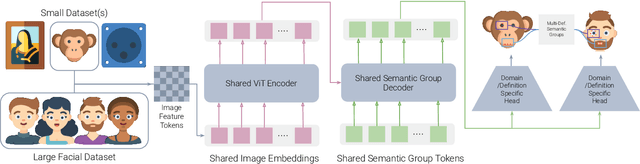


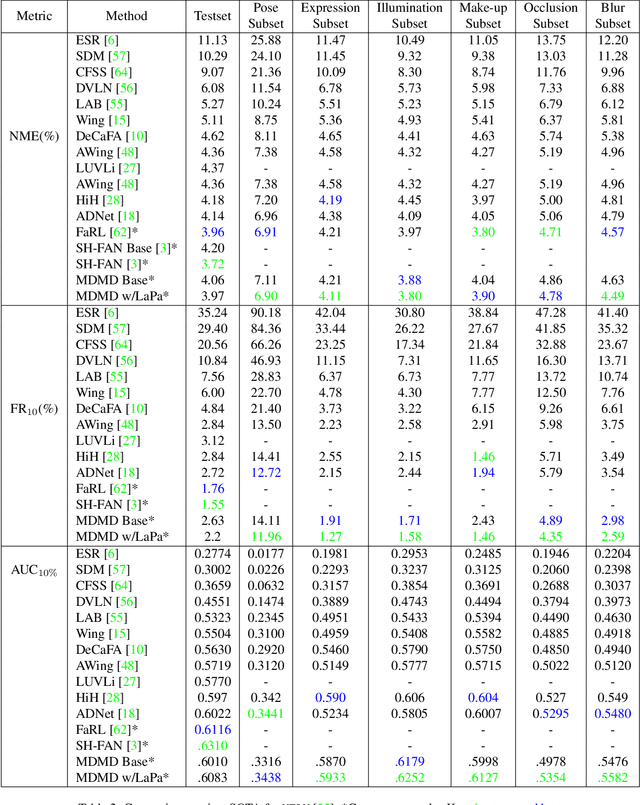
We present a novel method for multi image domain and multi-landmark definition learning for small dataset facial localization. Training a small dataset alongside a large(r) dataset helps with robust learning for the former, and provides a universal mechanism for facial landmark localization for new and/or smaller standard datasets. To this end, we propose a Vision Transformer encoder with a novel decoder with a definition agnostic shared landmark semantic group structured prior, that is learnt, as we train on more than one dataset concurrently. Due to our novel definition agnostic group prior the datasets may vary in landmark definitions and domains. During the decoder stage we use cross- and self-attention, whose output is later fed into domain/definition specific heads that minimize a Laplacian-log-likelihood loss. We achieve state-of-the-art performance on standard landmark localization datasets such as COFW and WFLW, when trained with a bigger dataset. We also show state-of-the-art performance on several varied image domain small datasets for animals, caricatures, and facial portrait paintings. Further, we contribute a small dataset (150 images) of pareidolias to show efficacy of our method. Finally, we provide several analysis and ablation studies to justify our claims.
Generative Landmarks
Apr 08, 2021
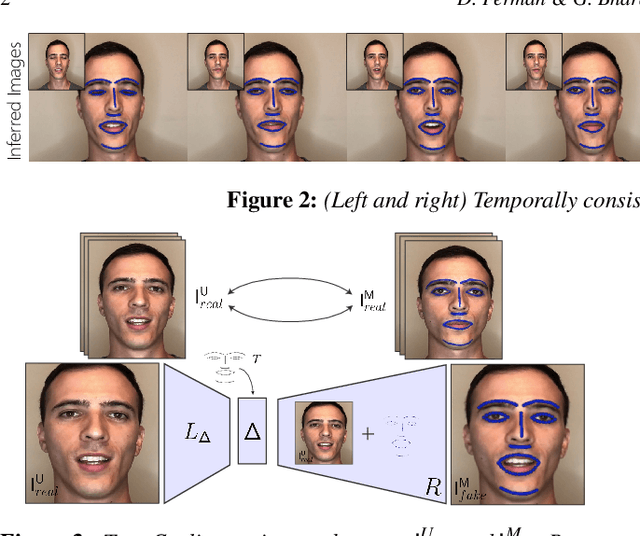
We propose a general purpose approach to detect landmarks with improved temporal consistency, and personalization. Most sparse landmark detection methods rely on laborious, manually labelled landmarks, where inconsistency in annotations over a temporal volume leads to sub-optimal landmark learning. Further, high-quality landmarks with personalization is often hard to achieve. We pose landmark detection as an image translation problem. We capture two sets of unpaired marked (with paint) and unmarked videos. We then use a generative adversarial network and cyclic consistency to predict deformations of landmark templates that simulate markers on unmarked images until these images are indistinguishable from ground-truth marked images. Our novel method does not rely on manually labelled priors, is temporally consistent, and image class agnostic -- face, and hand landmarks detection examples are shown.