 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent and Style Aware Audio-Driven Facial Animation
Paper and Code
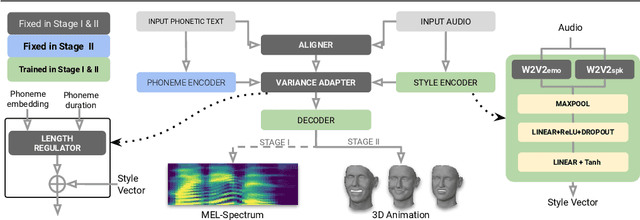
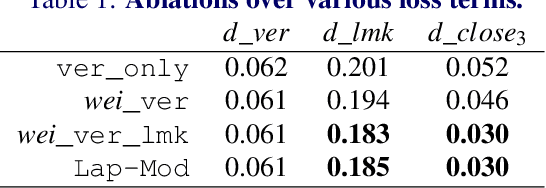
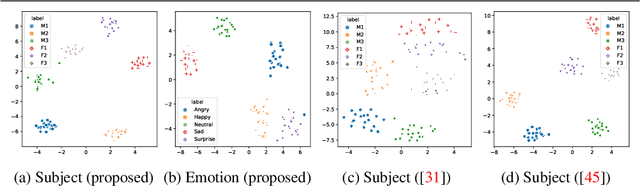
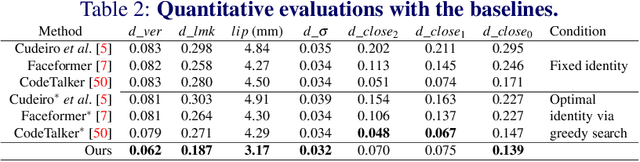
Audio-driven 3D facial animation has several virtual humans applications for content creation and editing. While several existing methods provide solutions for speech-driven animation, precise control over content (what) and style (how) of the final performance is still challenging. We propose a novel approach that takes as input an audio, and the corresponding text to extract temporally-aligned content and disentangled style representations, in order to provide controls over 3D facial animation. Our method is trained in two stages, that evolves from audio prominent styles (how it sounds) to visual prominent styles (how it looks). We leverage a high-resource audio dataset in stage I to learn styles that control speech generation in a self-supervised learning framework, and then fine-tune this model with low-resource audio/3D mesh pairs in stage II to control 3D vertex generation. We employ a non-autoregressive seq2seq formulation to model sentence-level dependencies, and better mouth articulations. Our method provides flexibility that the style of a reference audio and the content of a source audio can be combined to enable audio style transfer. Similarly, the content can be modified, e.g. muting or swapping words, that enables style-preserving content editing.