 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaTrace: Synthesizing Realistic Digital Footprints with LLM Agents
Mar 12, 2026Digital footprints (records of individuals' interactions with digital systems) are essential for studying behavior, developing personalized applications, and training machine learning models. However, research in this area is often hindered by the scarcity of diverse and accessible data. To address this limitation, we propose a novel method for synthesizing realistic digital footprints using large language model (LLM) agents. Starting from a structured user profile, our approach generates diverse and plausible sequences of user events, ultimately producing corresponding digital artifacts such as emails, messages, calendar entries, reminders, etc. Intrinsic evaluation results demonstrate that the generated dataset is more diverse and realistic than existing baselines. Moreover, models fine-tuned on our synthetic data outperform those trained on other synthetic datasets when evaluated on real-world out-of-distribution tasks.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
AudioSetMix: Enhancing Audio-Language Datasets with LLM-Assisted Augmentations
May 17, 2024Multi-modal learning in the audio-language domain has seen significant advancements in recent years. However, audio-language learning faces challenges due to limited and lower-quality data compared to image-language tasks. Existing audio-language datasets are notably smaller, and manual labeling is hindered by the need to listen to entire audio clips for accurate labeling. Our method systematically generates audio-caption pairs by augmenting audio clips with natural language labels and corresponding audio signal processing operations. Leveraging a Large Language Model, we generate descriptions of augmented audio clips with a prompt template. This scalable method produces AudioSetMix, a high-quality training dataset for text-and-audio related models. Integration of our dataset improves models performance on benchmarks by providing diversified and better-aligned examples. Notably, our dataset addresses the absence of modifiers (adjectives and adverbs) in existing datasets. By enabling models to learn these concepts, and generating hard negative examples during training, we achieve state-of-the-art performance on multiple benchmarks.
Neural network accelerator for quantum control
Aug 04, 2022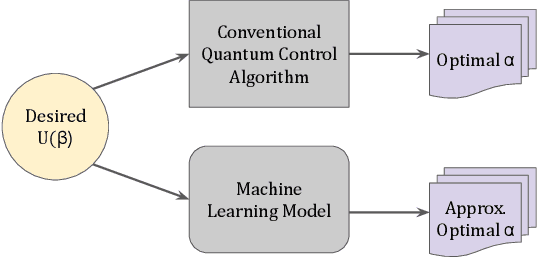
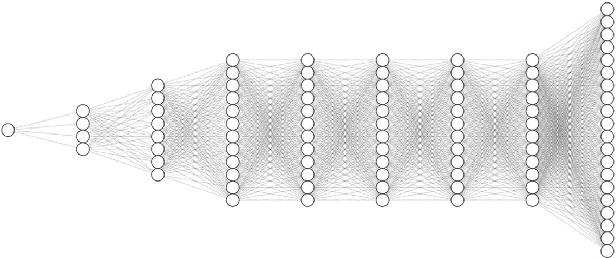
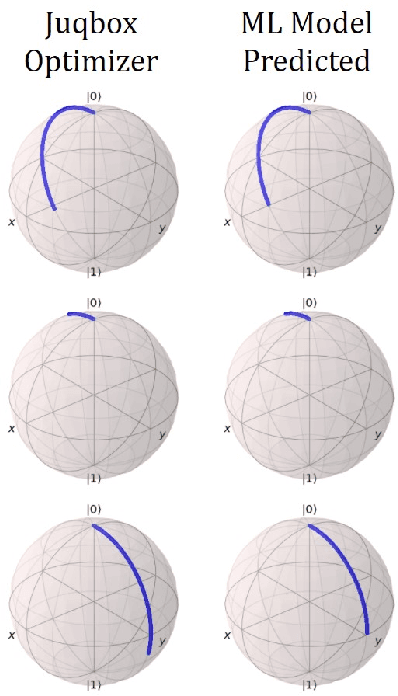
Efficient quantum control is necessary for practical quantum computing implementations with current technologies. Conventional algorithms for determining optimal control parameters are computationally expensive, largely excluding them from use outside of the simulation. Existing hardware solutions structured as lookup tables are imprecise and costly. By designing a machine learning model to approximate the results of traditional tools, a more efficient method can be produced. Such a model can then be synthesized into a hardware accelerator for use in quantum systems. In this study, we demonstrate a machine learning algorithm for predicting optimal pulse parameters. This algorithm is lightweight enough to fit on a low-resource FPGA and perform inference with a latency of 175 ns and pipeline interval of 5 ns with $~>~$0.99 gate fidelity. In the long term, such an accelerator could be used near quantum computing hardware where traditional computers cannot operate, enabling quantum control at a reasonable cost at low latencies without incurring large data bandwidths outside of the cryogenic environment.