 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-Chain: Structured Visual Chain-of-Thought For Medicine
Oct 26, 2025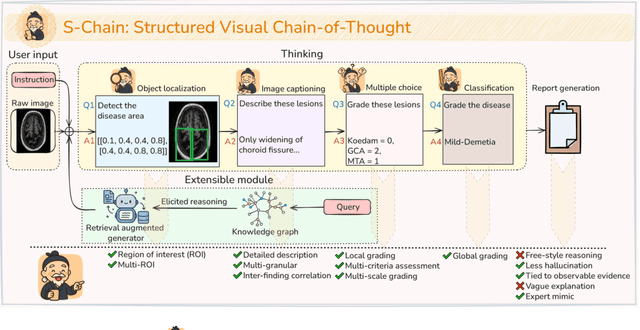
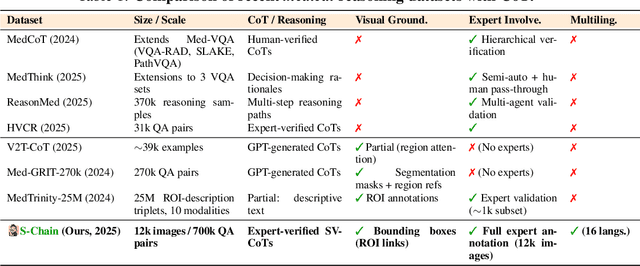
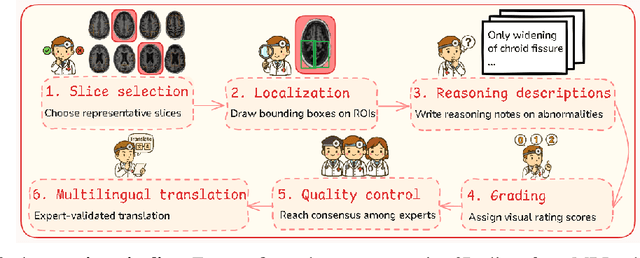
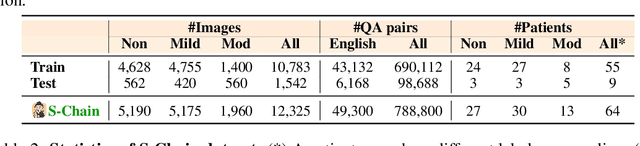
Faithful reasoning in medical vision-language models (VLMs) requires not only accurate predictions but also transparent alignment between textual rationales and visual evidence. While Chain-of-Thought (CoT) prompting has shown promise in medical visual question answering (VQA), no large-scale expert-level dataset has captured stepwise reasoning with precise visual grounding. We introduce S-Chain, the first large-scale dataset of 12,000 expert-annotated medical images with bounding boxes and structured visual CoT (SV-CoT), explicitly linking visual regions to reasoning steps. The dataset further supports 16 languages, totaling over 700k VQA pairs for broad multilingual applicability. Using S-Chain, we benchmark state-of-the-art medical VLMs (ExGra-Med, LLaVA-Med) and general-purpose VLMs (Qwen2.5-VL, InternVL2.5), showing that SV-CoT supervision significantly improves interpretability, grounding fidelity, and robustness. Beyond benchmarking, we study its synergy with retrieval-augmented generation, revealing how domain knowledge and visual grounding interact during autoregressive reasoning. Finally, we propose a new mechanism that strengthens the alignment between visual evidence and reasoning, improving both reliability and efficiency. S-Chain establishes a new benchmark for grounded medical reasoning and paves the way toward more trustworthy and explainable medical VLMs.
Deep Generative Attacks and Countermeasures for Data-Driven Offline Signature Verification
Dec 02, 2023While previous studies have explored attacks via random, simple, and skilled forgeries, generative attacks have received limited attention in the data-driven signature verification (DASV) process. Thus, this paper explores the impact of generative attacks on DASV and proposes practical and interpretable countermeasures. We investigate the power of two prominent Deep Generative Models (DGMs), Variational Auto-encoders (VAE) and Conditional Generative Adversarial Networks (CGAN), on their ability to generate signatures that would successfully deceive DASV. Additionally, we evaluate the quality of generated images using the Structural Similarity Index measure (SSIM) and use the same to explain the attack's success. Finally, we propose countermeasures that effectively reduce the impact of deep generative attacks on DASV. We first generated six synthetic datasets from three benchmark offline-signature datasets viz. CEDAR, BHSig260- Bengali, and BHSig260-Hindi using VAE and CGAN. Then, we built baseline DASVs using Xception, ResNet152V2, and DenseNet201. These DASVs achieved average (over the three datasets) False Accept Rates (FARs) of 2.55%, 3.17%, and 1.06%, respectively. Then, we attacked these baselines using the synthetic datasets. The VAE-generated signatures increased average FARs to 10.4%, 10.1%, and 7.5%, while CGAN-generated signatures to 32.5%, 30%, and 26.1%. The variation in the effectiveness of attack for VAE and CGAN was investigated further and explained by a strong (rho = -0.86) negative correlation between FARs and SSIMs. We created another set of synthetic datasets and used the same to retrain the DASVs. The retained baseline showed significant robustness to random, skilled, and generative attacks as the FARs shrank to less than 1% on average. The findings underscore the importance of studying generative attacks and potential countermeasures for DASV.
Tag-Based Annotation for Avatar Face Creation
Aug 24, 2023
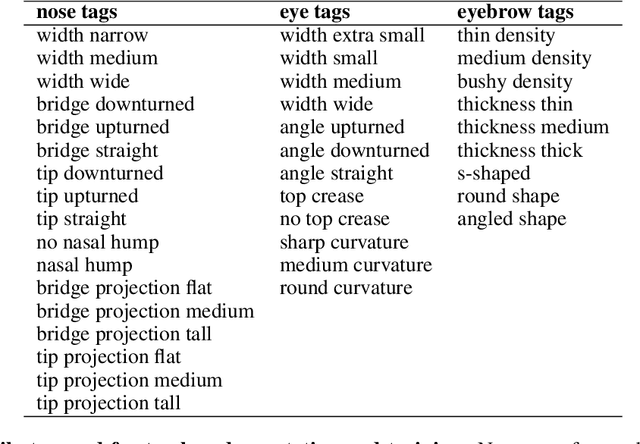


Currently, digital avatars can be created manually using human images as reference. Systems such as Bitmoji are excellent producers of detailed avatar designs, with hundreds of choices for customization. A supervised learning model could be trained to generate avatars automatically, but the hundreds of possible options create difficulty in securing non-noisy data to train a model. As a solution, we train a model to produce avatars from human images using tag-based annotations. This method provides better annotator agreement, leading to less noisy data and higher quality model predictions. Our contribution is an application of tag-based annotation to train a model for avatar face creation. We design tags for 3 different facial facial features offered by Bitmoji, and train a model using tag-based annotation to predict the nose.
Utilizing Segment Anything Model For Assessing Localization of GRAD-CAM in Medical Imaging
Jun 24, 2023The introduction of saliency map algorithms as an approach for assessing the interoperability of images has allowed for a deeper understanding of current black-box models with Artificial Intelligence. Their rise in popularity has led to these algorithms being applied in multiple fields, including medical imaging. With a classification task as important as those in the medical domain, a need for rigorous testing of their capabilities arises. Current works examine capabilities through assessing the localization of saliency maps upon medical abnormalities within an image, through comparisons with human annotations. We propose utilizing Segment Anything Model (SAM) to both further the accuracy of such existing metrics, while also generalizing beyond the need for human annotations. Our results show both high degrees of similarity to existing metrics while also highlighting the capabilities of this methodology to beyond human-annotation. Furthermore, we explore the applications (and challenges) of SAM within the medical domain, including image pre-processing before segmenting, natural language proposals to SAM in the form of CLIP-SAM, and SAM accuracy across multiple medical imaging datasets.