 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongVLM: Efficient Long Video Understanding via Large Language Models
Apr 10, 2024
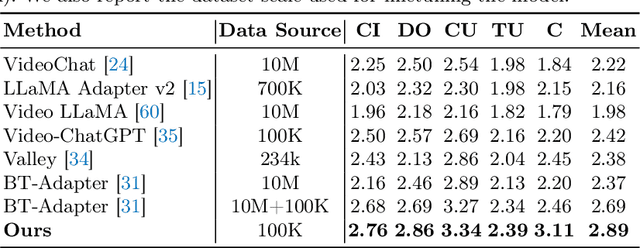

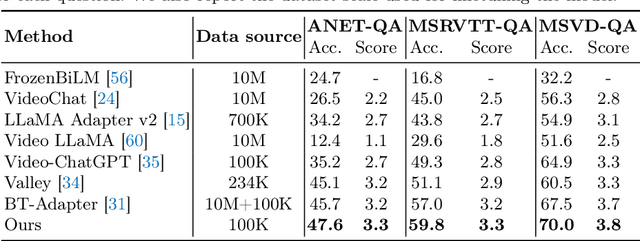
Empowered by Large Language Models (LLMs), recent advancements in VideoLLMs have driven progress in various video understanding tasks. These models encode video representations through pooling or query aggregation over a vast number of visual tokens, making computational and memory costs affordable. Despite successfully providing an overall comprehension of video content, existing VideoLLMs still face challenges in achieving detailed understanding in videos due to overlooking local information in long-term videos. To tackle this challenge, we introduce LongVLM, a straightforward yet powerful VideoLLM for long video understanding, building upon the observation that long videos often consist of sequential key events, complex actions, and camera movements. Our approach proposes to decompose long videos into multiple short-term segments and encode local features for each local segment via a hierarchical token merging module. These features are concatenated in temporal order to maintain the storyline across sequential short-term segments. Additionally, we propose to integrate global semantics into each local feature to enhance context understanding. In this way, we encode video representations that incorporate both local and global information, enabling the LLM to generate comprehensive responses for long-term videos. Experimental results on the VideoChatGPT benchmark and zero-shot video question-answering datasets demonstrate the superior capabilities of our model over the previous state-of-the-art methods. Qualitative examples demonstrate that our model produces more precise responses for long videos understanding. Code will be available at https://github.com/ziplab/LongVLM.
Mask Propagation for Efficient Video Semantic Segmentation
Oct 29, 2023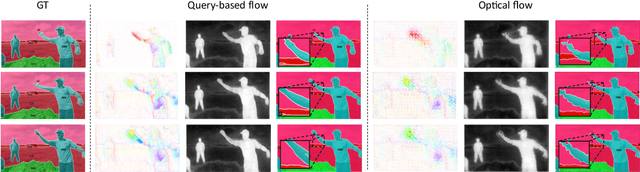
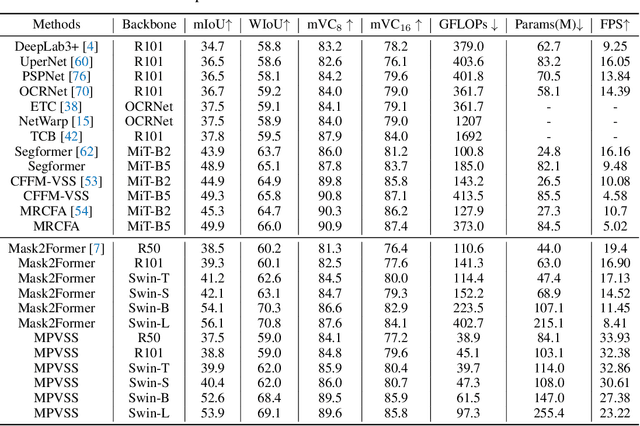


Video Semantic Segmentation (VSS) involves assigning a semantic label to each pixel in a video sequence. Prior work in this field has demonstrated promising results by extending image semantic segmentation models to exploit temporal relationships across video frames; however, these approaches often incur significant computational costs. In this paper, we propose an efficient mask propagation framework for VSS, called MPVSS. Our approach first employs a strong query-based image segmentor on sparse key frames to generate accurate binary masks and class predictions. We then design a flow estimation module utilizing the learned queries to generate a set of segment-aware flow maps, each associated with a mask prediction from the key frame. Finally, the mask-flow pairs are warped to serve as the mask predictions for the non-key frames. By reusing predictions from key frames, we circumvent the need to process a large volume of video frames individually with resource-intensive segmentors, alleviating temporal redundancy and significantly reducing computational costs. Extensive experiments on VSPW and Cityscapes demonstrate that our mask propagation framework achieves SOTA accuracy and efficiency trade-offs. For instance, our best model with Swin-L backbone outperforms the SOTA MRCFA using MiT-B5 by 4.0% mIoU, requiring only 26% FLOPs on the VSPW dataset. Moreover, our framework reduces up to 4x FLOPs compared to the per-frame Mask2Former baseline with only up to 2% mIoU degradation on the Cityscapes validation set. Code is available at https://github.com/ziplab/MPVSS.
A Survey on Efficient Training of Transformers
Feb 02, 2023

Recent advances in Transformers have come with a huge requirement on computing resources, highlighting the importance of developing efficient training techniques to make Transformer training faster, at lower cost, and to higher accuracy by the efficient use of computation and memory resources. This survey provides the first systematic overview of the efficient training of Transformers, covering the recent progress in acceleration arithmetic and hardware, with a focus on the former. We analyze and compare methods that save computation and memory costs for intermediate tensors during training, together with techniques on hardware/algorithm co-design. We finally discuss challenges and promising areas for future research.
An Efficient Spatio-Temporal Pyramid Transformer for Action Detection
Jul 21, 2022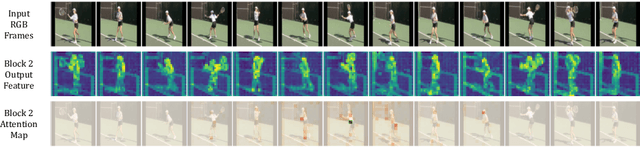

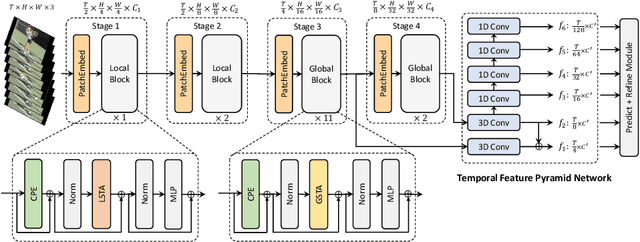
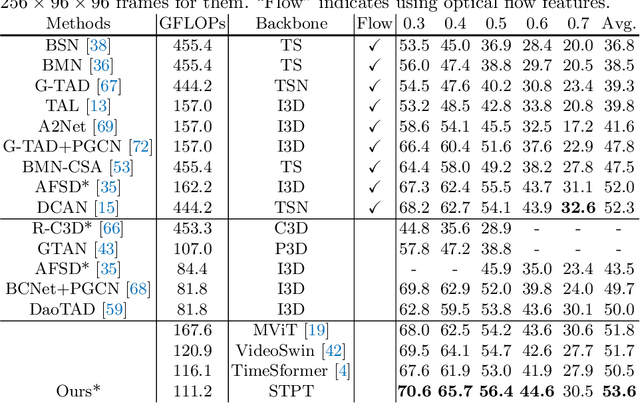
The task of action detection aims at deducing both the action category and localization of the start and end moment for each action instance in a long, untrimmed video. While vision Transformers have driven the recent advances in video understanding, it is non-trivial to design an efficient architecture for action detection due to the prohibitively expensive self-attentions over a long sequence of video clips. To this end, we present an efficient hierarchical Spatio-Temporal Pyramid Transformer (STPT) for action detection, building upon the fact that the early self-attention layers in Transformers still focus on local patterns. Specifically, we propose to use local window attention to encode rich local spatio-temporal representations in the early stages while applying global attention modules to capture long-term space-time dependencies in the later stages. In this way, our STPT can encode both locality and dependency with largely reduced redundancy, delivering a promising trade-off between accuracy and efficiency. For example, with only RGB input, the proposed STPT achieves 53.6% mAP on THUMOS14, surpassing I3D+AFSD RGB model by over 10% and performing favorably against state-of-the-art AFSD that uses additional flow features with 31% fewer GFLOPs, which serves as an effective and efficient end-to-end Transformer-based framework for action detection.