 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccult: Optimizing Collaborative Communication across Experts for Accelerated Parallel MoE Training and Inference
May 19, 2025Mixture-of-experts (MoE) architectures could achieve impressive computational efficiency with expert parallelism, which relies heavily on all-to-all communication across devices. Unfortunately, such communication overhead typically constitutes a significant portion of the total runtime, hampering the scalability of distributed training and inference for modern MoE models (consuming over $40\%$ runtime in large-scale training). In this paper, we first define collaborative communication to illustrate this intrinsic limitation, and then propose system- and algorithm-level innovations to reduce communication costs. Specifically, given a pair of experts co-activated by one token, we call them "collaborated", which comprises $2$ cases as intra- and inter-collaboration, depending on whether they are kept on the same device. Our pilot investigations reveal that augmenting the proportion of intra-collaboration can accelerate expert parallelism at scale. It motivates us to strategically optimize collaborative communication for accelerated MoE training and inference, dubbed Occult. Our designs are capable of either delivering exact results with reduced communication cost or controllably minimizing the cost with collaboration pruning, materialized by modified fine-tuning. Comprehensive experiments on various MoE-LLMs demonstrate that Occult can be faster than popular state-of-the-art inference or training frameworks (more than $1.5\times$ speed up across multiple tasks and models) with comparable or superior quality compared to the standard fine-tuning. Code is available at $\href{https://github.com/UNITES-Lab/Occult}{https://github.com/UNITES-Lab/Occult}$.
Learning Robust 3D Representation from CLIP via Dual Denoising
Jul 01, 2024In this paper, we explore a critical yet under-investigated issue: how to learn robust and well-generalized 3D representation from pre-trained vision language models such as CLIP. Previous works have demonstrated that cross-modal distillation can provide rich and useful knowledge for 3D data. However, like most deep learning models, the resultant 3D learning network is still vulnerable to adversarial attacks especially the iterative attack. In this work, we propose Dual Denoising, a novel framework for learning robust and well-generalized 3D representations from CLIP. It combines a denoising-based proxy task with a novel feature denoising network for 3D pre-training. Additionally, we propose utilizing parallel noise inference to enhance the generalization of point cloud features under cross domain settings. Experiments show that our model can effectively improve the representation learning performance and adversarial robustness of the 3D learning network under zero-shot settings without adversarial training. Our code is available at https://github.com/luoshuqing2001/Dual_Denoising.
A general framework for rotation invariant point cloud analysis
Feb 02, 2024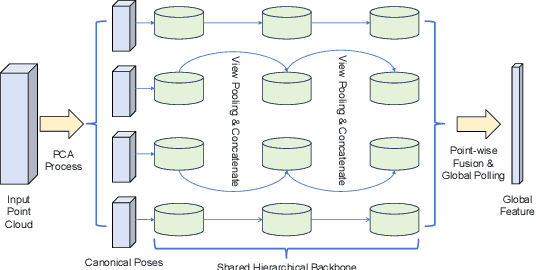



We propose a general method for deep learning based point cloud analysis, which is invariant to rotation on the inputs. Classical methods are vulnerable to rotation, as they usually take aligned point clouds as input. Principle Component Analysis (PCA) is a practical approach to achieve rotation invariance. However, there are still some gaps between theory and practical algorithms. In this work, we present a thorough study on designing rotation invariant algorithms for point cloud analysis. We first formulate it as a permutation invariant problem, then propose a general framework which can be combined with any backbones. Our method is beneficial for further research such as 3D pre-training and multi-modal learning. Experiments show that our method has considerable or better performance compared to state-of-the-art approaches on common benchmarks. Code is available at https://github.com/luoshuqing2001/RI_framework.
LLM-Mini-CEX: Automatic Evaluation of Large Language Model for Diagnostic Conversation
Aug 15, 2023There is an increasing interest in developing LLMs for medical diagnosis to improve diagnosis efficiency. Despite their alluring technological potential, there is no unified and comprehensive evaluation criterion, leading to the inability to evaluate the quality and potential risks of medical LLMs, further hindering the application of LLMs in medical treatment scenarios. Besides, current evaluations heavily rely on labor-intensive interactions with LLMs to obtain diagnostic dialogues and human evaluation on the quality of diagnosis dialogue. To tackle the lack of unified and comprehensive evaluation criterion, we first initially establish an evaluation criterion, termed LLM-specific Mini-CEX to assess the diagnostic capabilities of LLMs effectively, based on original Mini-CEX. To address the labor-intensive interaction problem, we develop a patient simulator to engage in automatic conversations with LLMs, and utilize ChatGPT for evaluating diagnosis dialogues automatically. Experimental results show that the LLM-specific Mini-CEX is adequate and necessary to evaluate medical diagnosis dialogue. Besides, ChatGPT can replace manual evaluation on the metrics of humanistic qualities and provides reproducible and automated comparisons between different LLMs.