 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperInfer: SLO-Aware Rotary Scheduling and Memory Management for LLM Inference on Superchips
Jan 28, 2026Large Language Model (LLM) serving faces a fundamental tension between stringent latency Service Level Objectives (SLOs) and limited GPU memory capacity. When high request rates exhaust the KV cache budget, existing LLM inference systems often suffer severe head-of-line (HOL) blocking. While prior work explored PCIe-based offloading, these approaches cannot sustain responsiveness under high request rates, often failing to meet tight Time-To-First-Token (TTFT) and Time-Between-Tokens (TBT) SLOs. We present SuperInfer, a high-performance LLM inference system designed for emerging Superchips (e.g., NVIDIA GH200) with tightly coupled GPU-CPU architecture via NVLink-C2C. SuperInfer introduces RotaSched, the first proactive, SLO-aware rotary scheduler that rotates requests to maintain responsiveness on Superchips, and DuplexKV, an optimized rotation engine that enables full-duplex transfer over NVLink-C2C. Evaluations on GH200 using various models and datasets show that SuperInfer improves TTFT SLO attainment rates by up to 74.7% while maintaining comparable TBT and throughput compared to state-of-the-art systems, demonstrating that SLO-aware scheduling and memory co-design unlocks the full potential of Superchips for responsive LLM serving.
Compute-in-Memory Implementation of State Space Models for Event Sequence Processing
Nov 17, 2025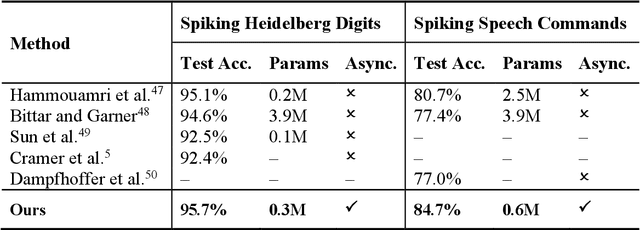
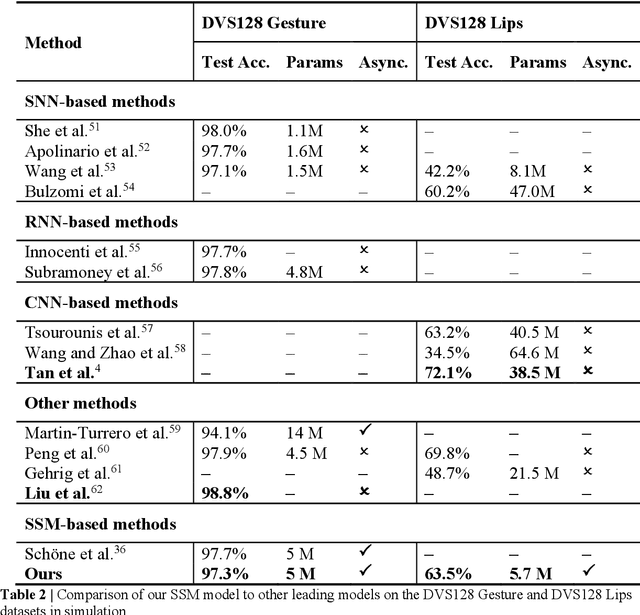
State space models (SSMs) have recently emerged as a powerful framework for long sequence processing, outperforming traditional methods on diverse benchmarks. Fundamentally, SSMs can generalize both recurrent and convolutional networks and have been shown to even capture key functions of biological systems. Here we report an approach to implement SSMs in energy-efficient compute-in-memory (CIM) hardware to achieve real-time, event-driven processing. Our work re-parameterizes the model to function with real-valued coefficients and shared decay constants, reducing the complexity of model mapping onto practical hardware systems. By leveraging device dynamics and diagonalized state transition parameters, the state evolution can be natively implemented in crossbar-based CIM systems combined with memristors exhibiting short-term memory effects. Through this algorithm and hardware co-design, we show the proposed system offers both high accuracy and high energy efficiency while supporting fully asynchronous processing for event-based vision and audio tasks.
LLM-Mini-CEX: Automatic Evaluation of Large Language Model for Diagnostic Conversation
Aug 15, 2023There is an increasing interest in developing LLMs for medical diagnosis to improve diagnosis efficiency. Despite their alluring technological potential, there is no unified and comprehensive evaluation criterion, leading to the inability to evaluate the quality and potential risks of medical LLMs, further hindering the application of LLMs in medical treatment scenarios. Besides, current evaluations heavily rely on labor-intensive interactions with LLMs to obtain diagnostic dialogues and human evaluation on the quality of diagnosis dialogue. To tackle the lack of unified and comprehensive evaluation criterion, we first initially establish an evaluation criterion, termed LLM-specific Mini-CEX to assess the diagnostic capabilities of LLMs effectively, based on original Mini-CEX. To address the labor-intensive interaction problem, we develop a patient simulator to engage in automatic conversations with LLMs, and utilize ChatGPT for evaluating diagnosis dialogues automatically. Experimental results show that the LLM-specific Mini-CEX is adequate and necessary to evaluate medical diagnosis dialogue. Besides, ChatGPT can replace manual evaluation on the metrics of humanistic qualities and provides reproducible and automated comparisons between different LLMs.