 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperInfer: SLO-Aware Rotary Scheduling and Memory Management for LLM Inference on Superchips
Jan 28, 2026Large Language Model (LLM) serving faces a fundamental tension between stringent latency Service Level Objectives (SLOs) and limited GPU memory capacity. When high request rates exhaust the KV cache budget, existing LLM inference systems often suffer severe head-of-line (HOL) blocking. While prior work explored PCIe-based offloading, these approaches cannot sustain responsiveness under high request rates, often failing to meet tight Time-To-First-Token (TTFT) and Time-Between-Tokens (TBT) SLOs. We present SuperInfer, a high-performance LLM inference system designed for emerging Superchips (e.g., NVIDIA GH200) with tightly coupled GPU-CPU architecture via NVLink-C2C. SuperInfer introduces RotaSched, the first proactive, SLO-aware rotary scheduler that rotates requests to maintain responsiveness on Superchips, and DuplexKV, an optimized rotation engine that enables full-duplex transfer over NVLink-C2C. Evaluations on GH200 using various models and datasets show that SuperInfer improves TTFT SLO attainment rates by up to 74.7% while maintaining comparable TBT and throughput compared to state-of-the-art systems, demonstrating that SLO-aware scheduling and memory co-design unlocks the full potential of Superchips for responsive LLM serving.
TIFace: Improving Facial Reconstruction through Tensorial Radiance Fields and Implicit Surfaces
Dec 15, 2023
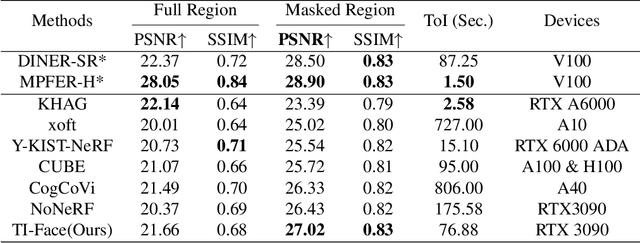
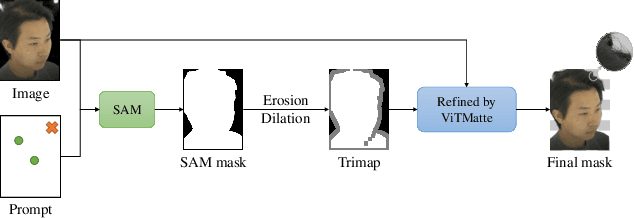
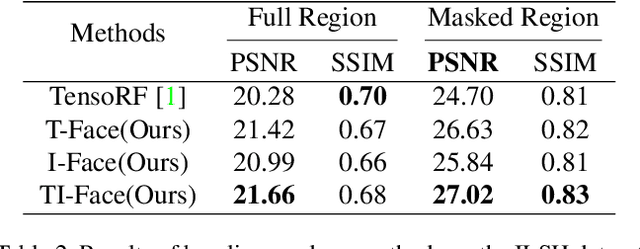
This report describes the solution that secured the first place in the "View Synthesis Challenge for Human Heads (VSCHH)" at the ICCV 2023 workshop. Given the sparse view images of human heads, the objective of this challenge is to synthesize images from novel viewpoints. Due to the complexity of textures on the face and the impact of lighting, the baseline method TensoRF yields results with significant artifacts, seriously affecting facial reconstruction. To address this issue, we propose TI-Face, which improves facial reconstruction through tensorial radiance fields (T-Face) and implicit surfaces (I-Face), respectively. Specifically, we employ an SAM-based approach to obtain the foreground mask, thereby filtering out intense lighting in the background. Additionally, we design mask-based constraints and sparsity constraints to eliminate rendering artifacts effectively. The experimental results demonstrate the effectiveness of the proposed improvements and superior performance of our method on face reconstruction. The code will be available at https://github.com/RuijieZhu94/TI-Face.
Structured Epipolar Matcher for Local Feature Matching
Apr 13, 2023



Local feature matching is challenging due to textureless and repetitive patterns. Existing methods focus on using appearance features and global interaction and matching, while the importance of geometry priors in local feature matching has not been fully exploited. Different from these methods, in this paper, we delve into the importance of geometry prior and propose Structured Epipolar Matcher (SEM) for local feature matching, which can leverage the geometric information in an iterative matching way. The proposed model enjoys several merits. First, our proposed Structured Feature Extractor can model the relative positional relationship between pixels and high-confidence anchor points. Second, our proposed Epipolar Attention and Matching can filter out irrelevant areas by utilizing the epipolar constraint. Extensive experimental results on five standard benchmarks demonstrate the superior performance of our SEM compared to state-of-the-art methods. Project page: https://sem2023.github.io.
Adaptive Spot-Guided Transformer for Consistent Local Feature Matching
Mar 29, 2023



Local feature matching aims at finding correspondences between a pair of images. Although current detector-free methods leverage Transformer architecture to obtain an impressive performance, few works consider maintaining local consistency. Meanwhile, most methods struggle with large scale variations. To deal with the above issues, we propose Adaptive Spot-Guided Transformer (ASTR) for local feature matching, which jointly models the local consistency and scale variations in a unified coarse-to-fine architecture. The proposed ASTR enjoys several merits. First, we design a spot-guided aggregation module to avoid interfering with irrelevant areas during feature aggregation. Second, we design an adaptive scaling module to adjust the size of grids according to the calculated depth information at fine stage. Extensive experimental results on five standard benchmarks demonstrate that our ASTR performs favorably against state-of-the-art methods. Our code will be released on https://astr2023.github.io.