 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2J-Transformer: Anchor-to-Joint Transformer Network for 3D Interacting Hand Pose Estimation from a Single RGB Image
Apr 07, 20233D interacting hand pose estimation from a single RGB image is a challenging task, due to serious self-occlusion and inter-occlusion towards hands, confusing similar appearance patterns between 2 hands, ill-posed joint position mapping from 2D to 3D, etc.. To address these, we propose to extend A2J-the state-of-the-art depth-based 3D single hand pose estimation method-to RGB domain under interacting hand condition. Our key idea is to equip A2J with strong local-global aware ability to well capture interacting hands' local fine details and global articulated clues among joints jointly. To this end, A2J is evolved under Transformer's non-local encoding-decoding framework to build A2J-Transformer. It holds 3 main advantages over A2J. First, self-attention across local anchor points is built to make them global spatial context aware to better capture joints' articulation clues for resisting occlusion. Secondly, each anchor point is regarded as learnable query with adaptive feature learning for facilitating pattern fitting capacity, instead of having the same local representation with the others. Last but not least, anchor point locates in 3D space instead of 2D as in A2J, to leverage 3D pose prediction. Experiments on challenging InterHand 2.6M demonstrate that, A2J-Transformer can achieve state-of-the-art model-free performance (3.38mm MPJPE advancement in 2-hand case) and can also be applied to depth domain with strong generalization.
Learning from Noisy Labels with Coarse-to-Fine Sample Credibility Modeling
Aug 23, 2022
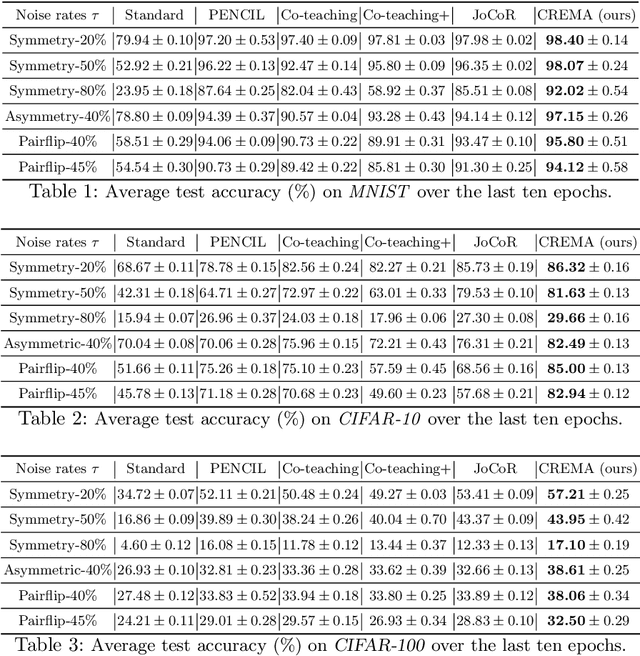

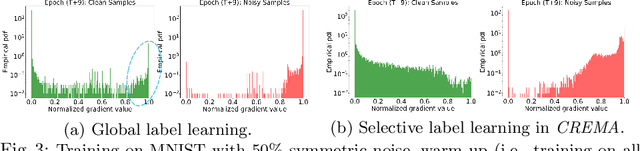
Training deep neural network (DNN) with noisy labels is practically challenging since inaccurate labels severely degrade the generalization ability of DNN. Previous efforts tend to handle part or full data in a unified denoising flow via identifying noisy data with a coarse small-loss criterion to mitigate the interference from noisy labels, ignoring the fact that the difficulties of noisy samples are different, thus a rigid and unified data selection pipeline cannot tackle this problem well. In this paper, we first propose a coarse-to-fine robust learning method called CREMA, to handle noisy data in a divide-and-conquer manner. In coarse-level, clean and noisy sets are firstly separated in terms of credibility in a statistical sense. Since it is practically impossible to categorize all noisy samples correctly, we further process them in a fine-grained manner via modeling the credibility of each sample. Specifically, for the clean set, we deliberately design a memory-based modulation scheme to dynamically adjust the contribution of each sample in terms of its historical credibility sequence during training, thus alleviating the effect from noisy samples incorrectly grouped into the clean set. Meanwhile, for samples categorized into the noisy set, a selective label update strategy is proposed to correct noisy labels while mitigating the problem of correction error. Extensive experiments are conducted on benchmarks of different modalities, including image classification (CIFAR, Clothing1M etc) and text recognition (IMDB), with either synthetic or natural semantic noises, demonstrating the superiority and generality of CREMA.