 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAG-SQL: Multi-Agent Generative Approach with Soft Schema Linking and Iterative Sub-SQL Refinement for Text-to-SQL
Aug 15, 2024



Recent In-Context Learning based methods have achieved remarkable success in Text-to-SQL task. However, there is still a large gap between the performance of these models and human performance on datasets with complex database schema and difficult questions, such as BIRD. Besides, existing work has neglected to supervise intermediate steps when solving questions iteratively with question decomposition methods, and the schema linking methods used in these works are very rudimentary. To address these issues, we propose MAG-SQL, a multi-agent generative approach with soft schema linking and iterative Sub-SQL refinement. In our framework, an entity-based method with tables' summary is used to select the columns in database, and a novel targets-conditions decomposition method is introduced to decompose those complex questions. Additionally, we build a iterative generating module which includes a Sub-SQL Generator and Sub-SQL Refiner, introducing external oversight for each step of generation. Through a series of ablation studies, the effectiveness of each agent in our framework has been demonstrated. When evaluated on the BIRD benchmark with GPT-4, MAG-SQL achieves an execution accuracy of 61.08\%, compared to the baseline accuracy of 46.35\% for vanilla GPT-4 and the baseline accuracy of 57.56\% for MAC-SQL. Besides, our approach makes similar progress on Spider.
OpenQA: Hybrid QA System Relying on Structured Knowledge Base as well as Non-structured Data
Dec 31, 2021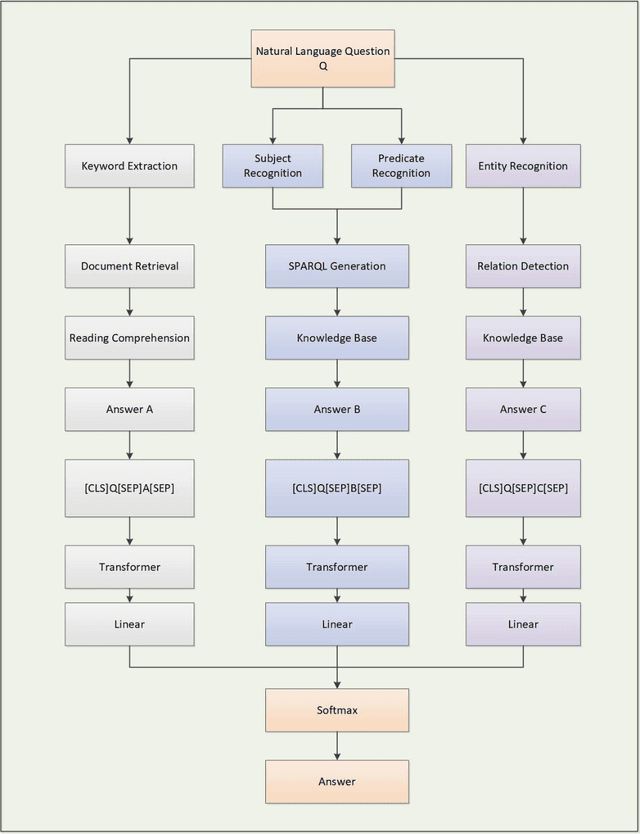
Search engines based on keyword retrieval can no longer adapt to the way of information acquisition in the era of intelligent Internet of Things due to the return of keyword related Internet pages. How to quickly, accurately and effectively obtain the information needed by users from massive Internet data has become one of the key issues urgently needed to be solved. We propose an intelligent question-answering system based on structured KB and unstructured data, called OpenQA, in which users can give query questions and the model can quickly give accurate answers back to users. We integrate KBQA structured question answering based on semantic parsing and deep representation learning, and two-stage unstructured question answering based on retrieval and neural machine reading comprehension into OpenQA, and return the final answer with the highest probability through the Transformer answer selection module in OpenQA. We carry out preliminary experiments on our constructed dataset, and the experimental results prove the effectiveness of the proposed intelligent question answering system. At the same time, the core technology of each module of OpenQA platform is still in the forefront of academic hot spots, and the theoretical essence and enrichment of OpenQA will be further explored based on these academic hot spots.
Improving Low-resource Reading Comprehension via Cross-lingual Transposition Rethinking
Jul 11, 2021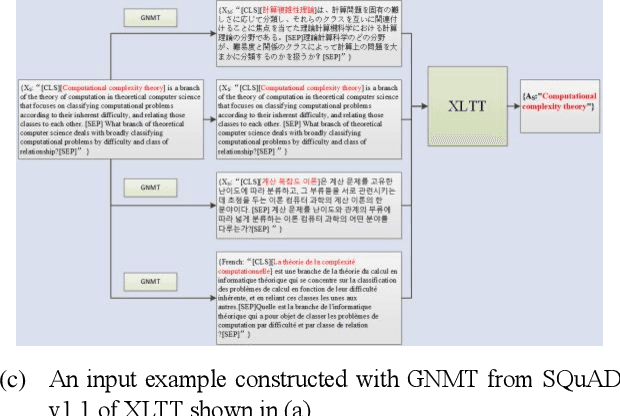
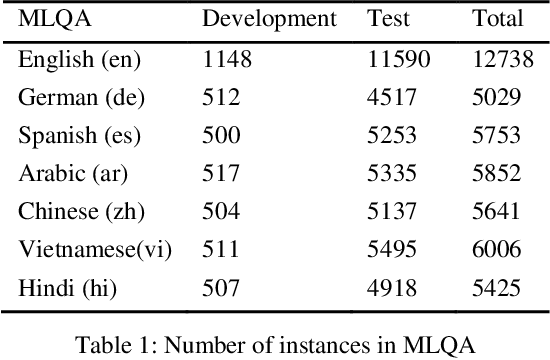
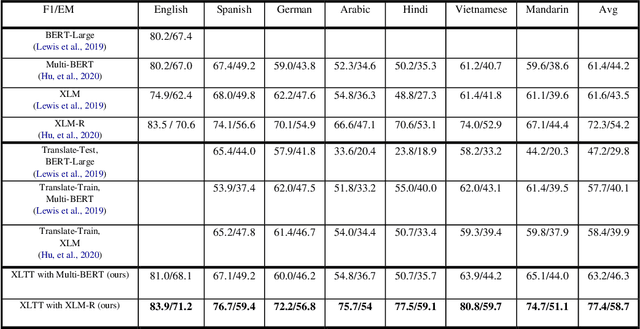
Extractive Reading Comprehension (ERC) has made tremendous advances enabled by the availability of large-scale high-quality ERC training data. Despite of such rapid progress and widespread application, the datasets in languages other than high-resource languages such as English remain scarce. To address this issue, we propose a Cross-Lingual Transposition ReThinking (XLTT) model by modelling existing high-quality extractive reading comprehension datasets in a multilingual environment. To be specific, we present multilingual adaptive attention (MAA) to combine intra-attention and inter-attention to learn more general generalizable semantic and lexical knowledge from each pair of language families. Furthermore, to make full use of existing datasets, we adopt a new training framework to train our model by calculating task-level similarities between each existing dataset and target dataset. The experimental results show that our XLTT model surpasses six baselines on two multilingual ERC benchmarks, especially more effective for low-resource languages with 3.9 and 4.1 average improvement in F1 and EM, respectively.
PatentMiner: Patent Vacancy Mining via Context-enhanced and Knowledge-guided Graph Attention
Jul 10, 2021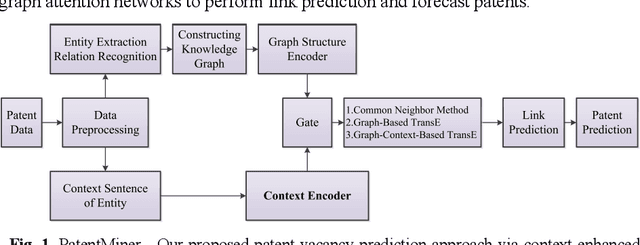
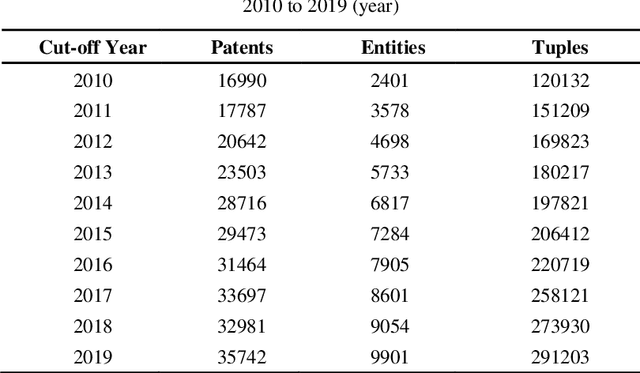
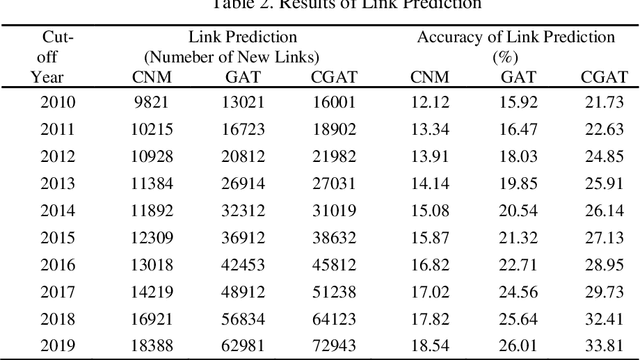
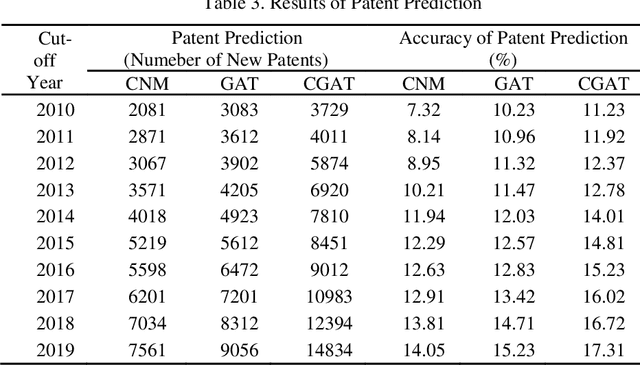
Although there are a small number of work to conduct patent research by building knowledge graph, but without constructing patent knowledge graph using patent documents and combining latest natural language processing methods to mine hidden rich semantic relationships in existing patents and predict new possible patents. In this paper, we propose a new patent vacancy prediction approach named PatentMiner to mine rich semantic knowledge and predict new potential patents based on knowledge graph (KG) and graph attention mechanism. Firstly, patent knowledge graph over time (e.g. year) is constructed by carrying out named entity recognition and relation extrac-tion from patent documents. Secondly, Common Neighbor Method (CNM), Graph Attention Networks (GAT) and Context-enhanced Graph Attention Networks (CGAT) are proposed to perform link prediction in the constructed knowledge graph to dig out the potential triples. Finally, patents are defined on the knowledge graph by means of co-occurrence relationship, that is, each patent is represented as a fully connected subgraph containing all its entities and co-occurrence relationships of the patent in the knowledge graph; Furthermore, we propose a new patent prediction task which predicts a fully connected subgraph with newly added prediction links as a new pa-tent. The experimental results demonstrate that our proposed patent predic-tion approach can correctly predict new patents and Context-enhanced Graph Attention Networks is much better than the baseline. Meanwhile, our proposed patent vacancy prediction task still has significant room to im-prove.
A Multilingual Modeling Method for Span-Extraction Reading Comprehension
May 31, 2021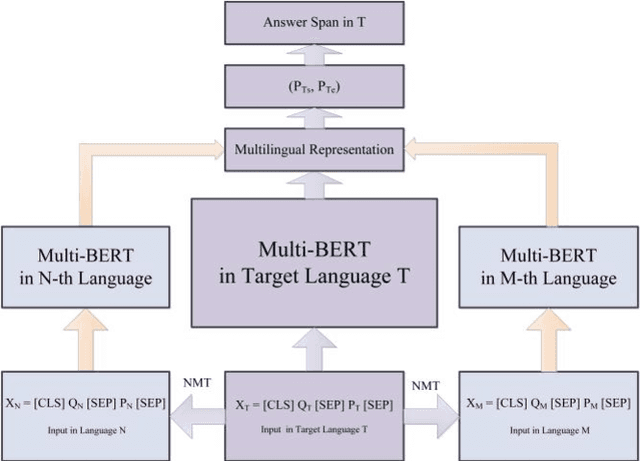
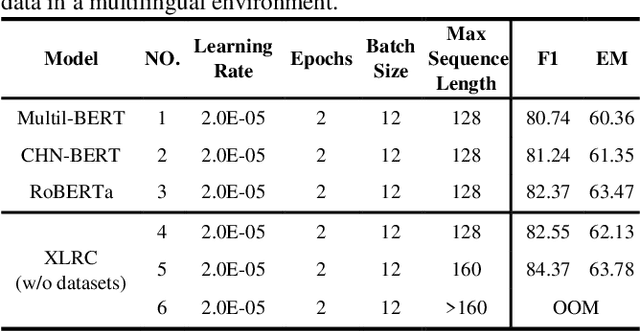
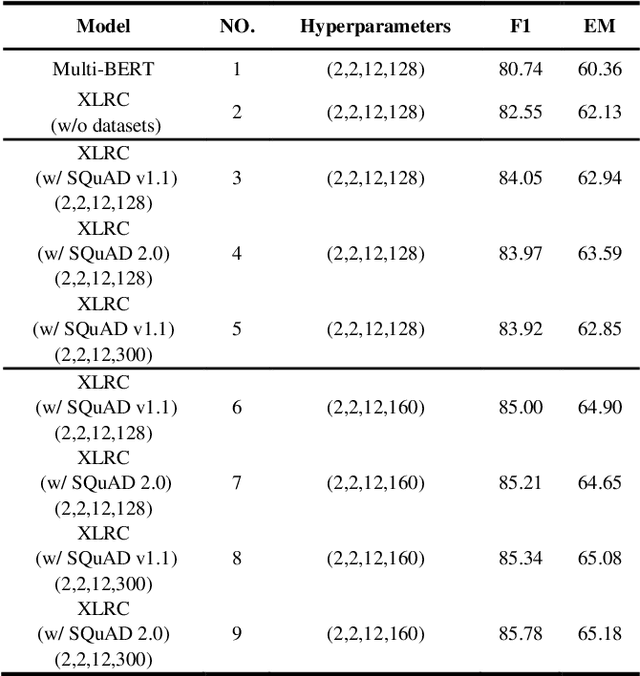
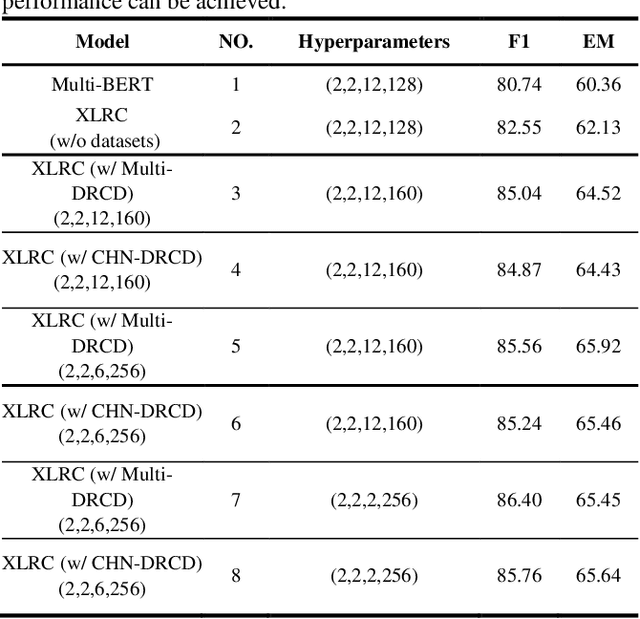
Span-extraction reading comprehension models have made tremendous advances enabled by the availability of large-scale, high-quality training datasets. Despite such rapid progress and widespread application, extractive reading comprehension datasets in languages other than English remain scarce, and creating such a sufficient amount of training data for each language is costly and even impossible. An alternative to creating large-scale high-quality monolingual span-extraction training datasets is to develop multilingual modeling approaches and systems which can transfer to the target language without requiring training data in that language. In this paper, in order to solve the scarce availability of extractive reading comprehension training data in the target language, we propose a multilingual extractive reading comprehension approach called XLRC by simultaneously modeling the existing extractive reading comprehension training data in a multilingual environment using self-adaptive attention and multilingual attention. Specifically, we firstly construct multilingual parallel corpora by translating the existing extractive reading comprehension datasets (i.e., CMRC 2018) from the target language (i.e., Chinese) into different language families (i.e., English). Secondly, to enhance the final target representation, we adopt self-adaptive attention (SAA) to combine self-attention and inter-attention to extract the semantic relations from each pair of the target and source languages. Furthermore, we propose multilingual attention (MLA) to learn the rich knowledge from various language families. Experimental results show that our model outperforms the state-of-the-art baseline (i.e., RoBERTa_Large) on the CMRC 2018 task, which demonstrate the effectiveness of our proposed multi-lingual modeling approach and show the potentials in multilingual NLP tasks.