 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Low-resource Reading Comprehension via Cross-lingual Transposition Rethinking
Jul 11, 2021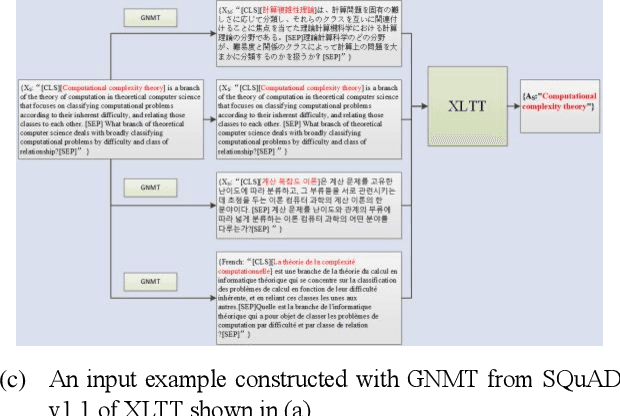
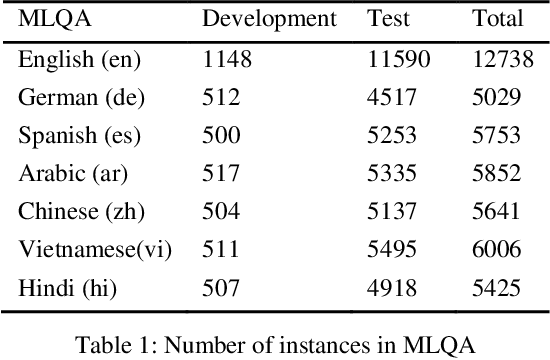
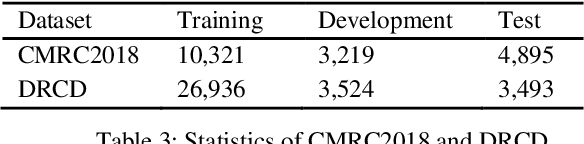
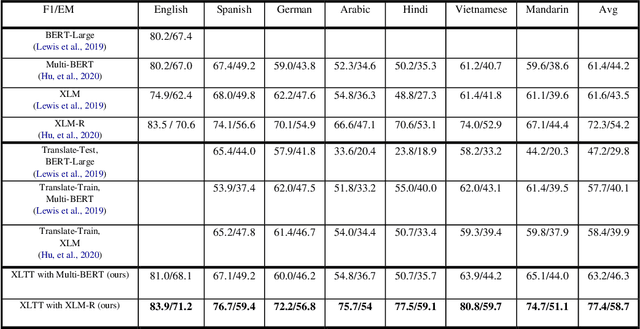
Extractive Reading Comprehension (ERC) has made tremendous advances enabled by the availability of large-scale high-quality ERC training data. Despite of such rapid progress and widespread application, the datasets in languages other than high-resource languages such as English remain scarce. To address this issue, we propose a Cross-Lingual Transposition ReThinking (XLTT) model by modelling existing high-quality extractive reading comprehension datasets in a multilingual environment. To be specific, we present multilingual adaptive attention (MAA) to combine intra-attention and inter-attention to learn more general generalizable semantic and lexical knowledge from each pair of language families. Furthermore, to make full use of existing datasets, we adopt a new training framework to train our model by calculating task-level similarities between each existing dataset and target dataset. The experimental results show that our XLTT model surpasses six baselines on two multilingual ERC benchmarks, especially more effective for low-resource languages with 3.9 and 4.1 average improvement in F1 and EM, respectively.
PatentMiner: Patent Vacancy Mining via Context-enhanced and Knowledge-guided Graph Attention
Jul 10, 2021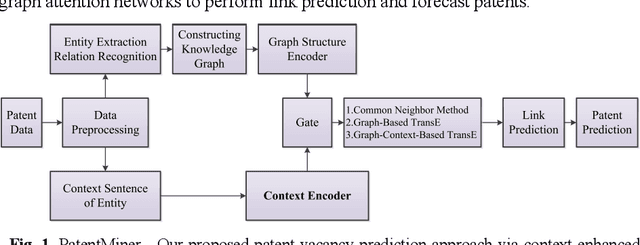
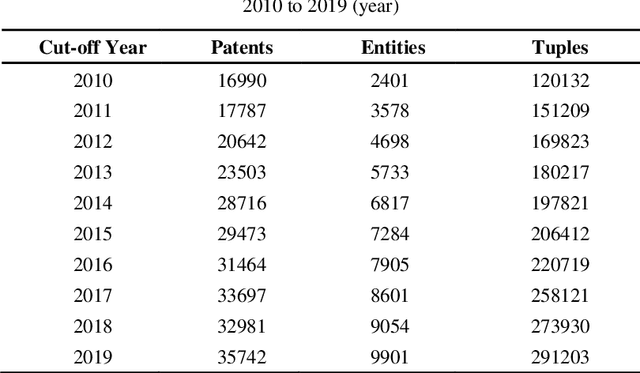
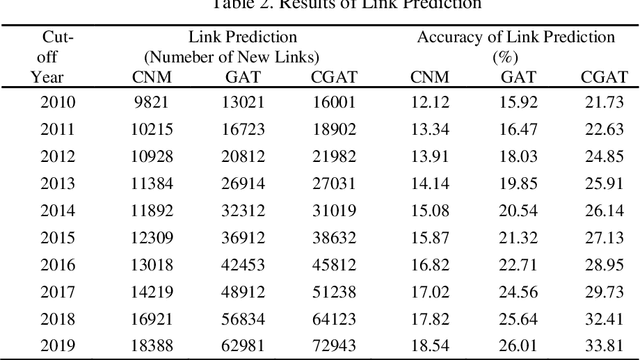
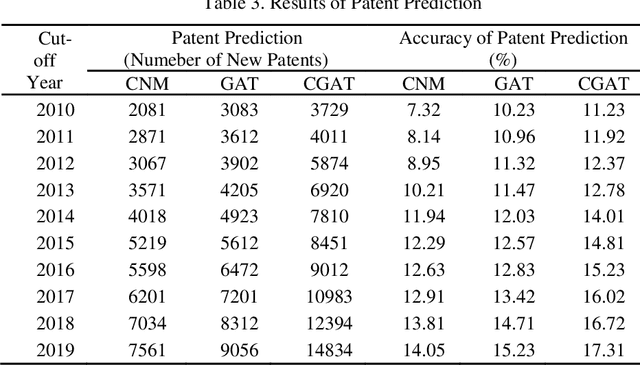
Although there are a small number of work to conduct patent research by building knowledge graph, but without constructing patent knowledge graph using patent documents and combining latest natural language processing methods to mine hidden rich semantic relationships in existing patents and predict new possible patents. In this paper, we propose a new patent vacancy prediction approach named PatentMiner to mine rich semantic knowledge and predict new potential patents based on knowledge graph (KG) and graph attention mechanism. Firstly, patent knowledge graph over time (e.g. year) is constructed by carrying out named entity recognition and relation extrac-tion from patent documents. Secondly, Common Neighbor Method (CNM), Graph Attention Networks (GAT) and Context-enhanced Graph Attention Networks (CGAT) are proposed to perform link prediction in the constructed knowledge graph to dig out the potential triples. Finally, patents are defined on the knowledge graph by means of co-occurrence relationship, that is, each patent is represented as a fully connected subgraph containing all its entities and co-occurrence relationships of the patent in the knowledge graph; Furthermore, we propose a new patent prediction task which predicts a fully connected subgraph with newly added prediction links as a new pa-tent. The experimental results demonstrate that our proposed patent predic-tion approach can correctly predict new patents and Context-enhanced Graph Attention Networks is much better than the baseline. Meanwhile, our proposed patent vacancy prediction task still has significant room to im-prove.