 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Low-resource Reading Comprehension via Cross-lingual Transposition Rethinking
Jul 11, 2021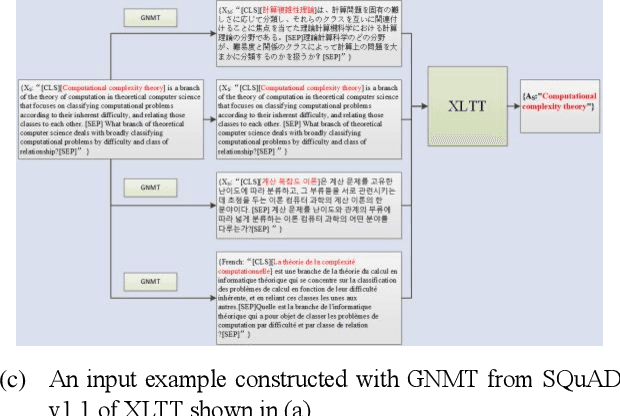
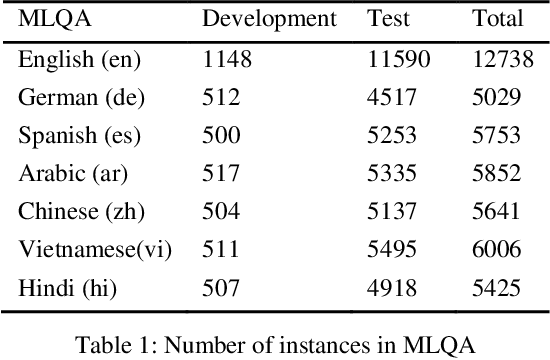
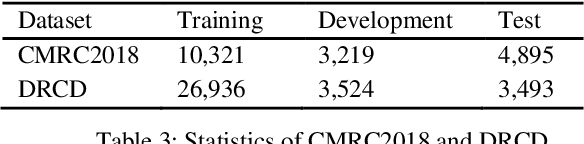
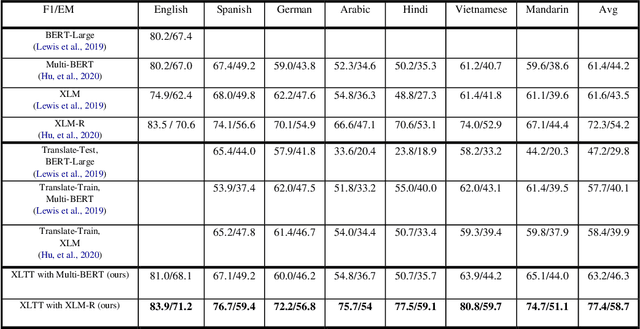
Extractive Reading Comprehension (ERC) has made tremendous advances enabled by the availability of large-scale high-quality ERC training data. Despite of such rapid progress and widespread application, the datasets in languages other than high-resource languages such as English remain scarce. To address this issue, we propose a Cross-Lingual Transposition ReThinking (XLTT) model by modelling existing high-quality extractive reading comprehension datasets in a multilingual environment. To be specific, we present multilingual adaptive attention (MAA) to combine intra-attention and inter-attention to learn more general generalizable semantic and lexical knowledge from each pair of language families. Furthermore, to make full use of existing datasets, we adopt a new training framework to train our model by calculating task-level similarities between each existing dataset and target dataset. The experimental results show that our XLTT model surpasses six baselines on two multilingual ERC benchmarks, especially more effective for low-resource languages with 3.9 and 4.1 average improvement in F1 and EM, respectively.