 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Transformations in Contrastive Self-Supervised Learning: A Review
Paper and Code
Mar 22, 2022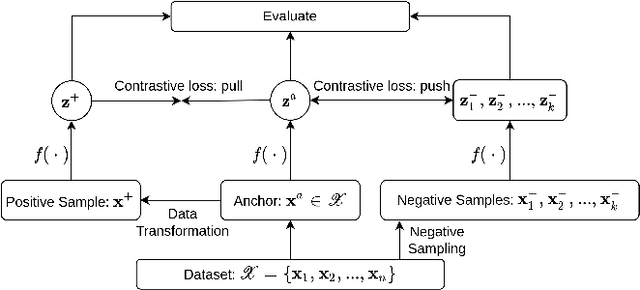
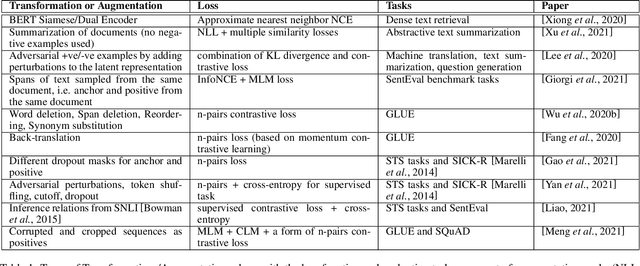


Contrastive self-supervised learning has become a prominent technique in representation learning. The main step in these methods is to contrast semantically similar and dissimilar pairs of samples. However, in the domain of Natural Language, the augmentation methods used in creating similar pairs with regard to contrastive learning assumptions are challenging. This is because, even simply modifying a word in the input might change the semantic meaning of the sentence, and hence, would violate the distributional hypothesis. In this review paper, we formalize the contrastive learning framework in the domain of natural language processing. We emphasize the considerations that need to be addressed in the data transformation step and review the state-of-the-art methods and evaluations for contrastive representation learning in NLP. Finally, we describe some challenges and potential directions for learning better text representations using contrastive methods.