 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Platform Hate Speech Detection with Weakly Supervised Causal Disentanglement
Paper and Code
Apr 17, 2024
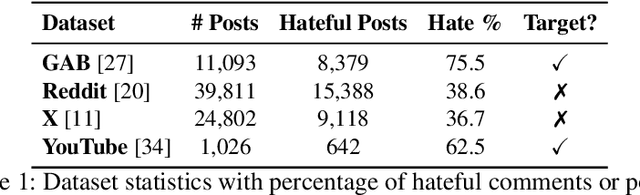
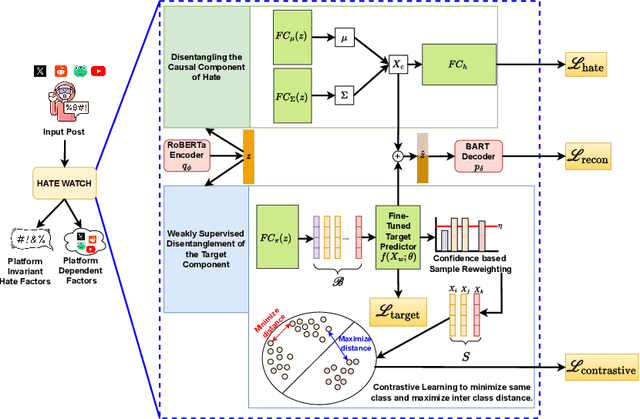
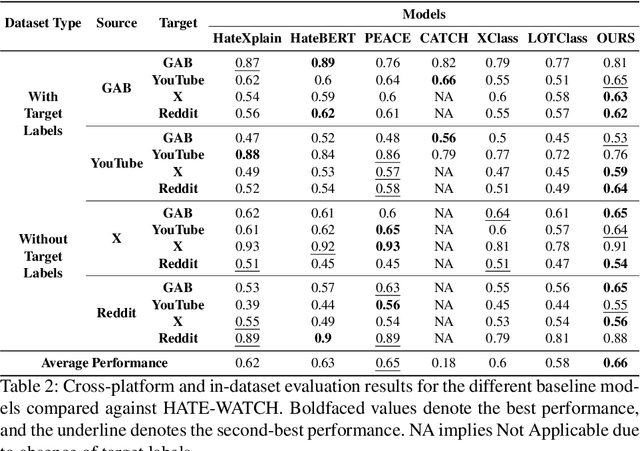
Content moderation faces a challenging task as social media's ability to spread hate speech contrasts with its role in promoting global connectivity. With rapidly evolving slang and hate speech, the adaptability of conventional deep learning to the fluid landscape of online dialogue remains limited. In response, causality inspired disentanglement has shown promise by segregating platform specific peculiarities from universal hate indicators. However, its dependency on available ground truth target labels for discerning these nuances faces practical hurdles with the incessant evolution of platforms and the mutable nature of hate speech. Using confidence based reweighting and contrastive regularization, this study presents HATE WATCH, a novel framework of weakly supervised causal disentanglement that circumvents the need for explicit target labeling and effectively disentangles input features into invariant representations of hate. Empirical validation across platforms two with target labels and two without positions HATE WATCH as a novel method in cross platform hate speech detection with superior performance. HATE WATCH advances scalable content moderation techniques towards developing safer online communities.