 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrioritizing Potential Wetland Areas via Region-to-Region Knowledge Transfer and Adaptive Propagation
Jun 08, 2024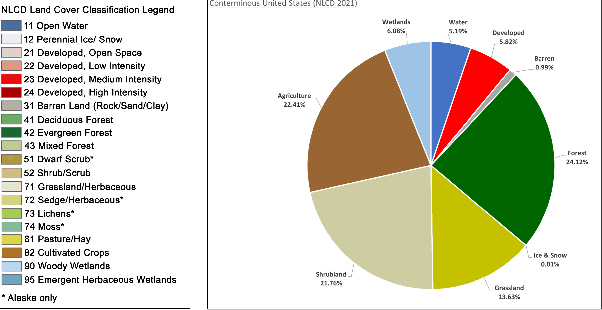
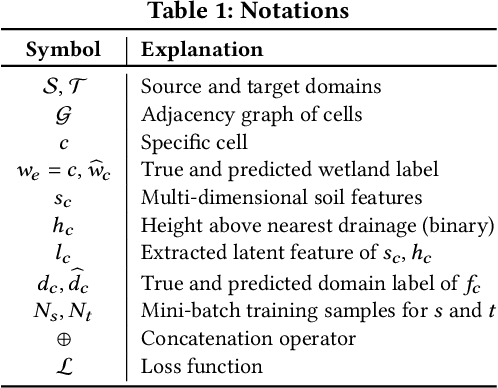
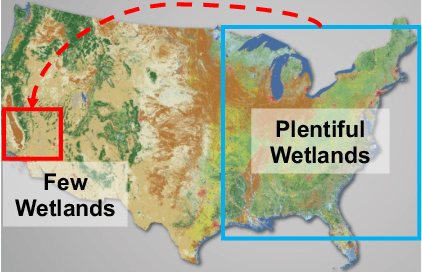
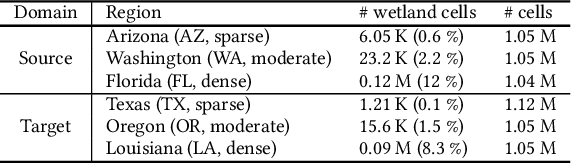
Wetlands are important to communities, offering benefits ranging from water purification, and flood protection to recreation and tourism. Therefore, identifying and prioritizing potential wetland areas is a critical decision problem. While data-driven solutions are feasible, this is complicated by significant data sparsity due to the low proportion of wetlands (3-6\%) in many areas of interest in the southwestern US. This makes it hard to develop data-driven models that can help guide the identification of additional wetland areas. To solve this limitation, we propose two strategies: (1) The first of these is knowledge transfer from regions with rich wetlands (such as the Eastern US) to sparser regions (such as the Southwestern area with few wetlands). Recognizing that these regions are likely to be very different from each other in terms of soil characteristics, population distribution, and land use, we propose a domain disentanglement strategy that identifies and transfers only the applicable aspects of the learned model. (2) We complement this with a spatial data enrichment strategy that relies on an adaptive propagation mechanism. This mechanism differentiates between node pairs that have positive and negative impacts on each other for Graph Neural Networks (GNNs). To summarize, given two spatial cells belonging to different regions, we identify domain-specific and domain-shareable features, and, for each region, we rely on adaptive propagation to enrich features with the features of surrounding cells. We conduct rigorous experiments to substantiate our proposed method's effectiveness, robustness, and scalability compared to state-of-the-art baselines. Additionally, an ablation study demonstrates that each module is essential in prioritizing potential wetlands, which justifies our assumption.
UPREVE: An End-to-End Causal Discovery Benchmarking System
Jul 25, 2023

Discovering causal relationships in complex socio-behavioral systems is challenging but essential for informed decision-making. We present Upload, PREprocess, Visualize, and Evaluate (UPREVE), a user-friendly web-based graphical user interface (GUI) designed to simplify the process of causal discovery. UPREVE allows users to run multiple algorithms simultaneously, visualize causal relationships, and evaluate the accuracy of learned causal graphs. With its accessible interface and customizable features, UPREVE empowers researchers and practitioners in social computing and behavioral-cultural modeling (among others) to explore and understand causal relationships effectively. Our proposed solution aims to make causal discovery more accessible and user-friendly, enabling users to gain valuable insights for better decision-making.
Class-Specific Attention (CSA) for Time-Series Classification
Nov 19, 2022Most neural network-based classifiers extract features using several hidden layers and make predictions at the output layer by utilizing these extracted features. We observe that not all features are equally pronounced in all classes; we call such features class-specific features. Existing models do not fully utilize the class-specific differences in features as they feed all extracted features from the hidden layers equally to the output layers. Recent attention mechanisms allow giving different emphasis (or attention) to different features, but these attention models are themselves class-agnostic. In this paper, we propose a novel class-specific attention (CSA) module to capture significant class-specific features and improve the overall classification performance of time series. The CSA module is designed in a way such that it can be adopted in existing neural network (NN) based models to conduct time series classification. In the experiments, this module is plugged into five start-of-the-art neural network models for time series classification to test its effectiveness by using 40 different real datasets. Extensive experiments show that an NN model embedded with the CSA module can improve the base model in most cases and the accuracy improvement can be up to 42%. Our statistical analysis show that the performance of an NN model embedding the CSA module is better than the base NN model on 67% of MTS and 80% of UTS test cases and is significantly better on 11% of MTS and 13% of UTS test cases.
Evaluation Methods and Measures for Causal Learning Algorithms
Feb 07, 2022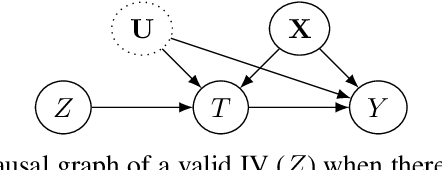
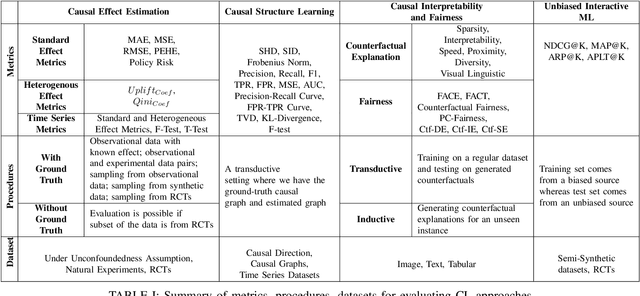
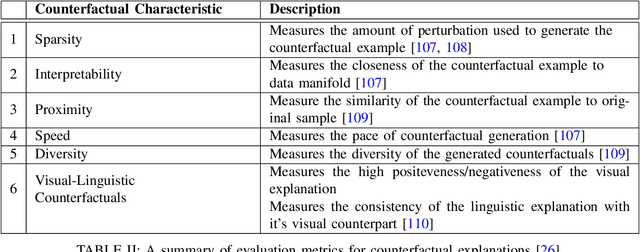
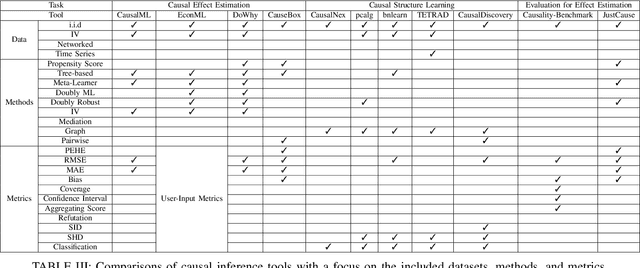
The convenient access to copious multi-faceted data has encouraged machine learning researchers to reconsider correlation-based learning and embrace the opportunity of causality-based learning, i.e., causal machine learning (causal learning). Recent years have therefore witnessed great effort in developing causal learning algorithms aiming to help AI achieve human-level intelligence. Due to the lack-of ground-truth data, one of the biggest challenges in current causal learning research is algorithm evaluations. This largely impedes the cross-pollination of AI and causal inference, and hinders the two fields to benefit from the advances of the other. To bridge from conventional causal inference (i.e., based on statistical methods) to causal learning with big data (i.e., the intersection of causal inference and machine learning), in this survey, we review commonly-used datasets, evaluation methods, and measures for causal learning using an evaluation pipeline similar to conventional machine learning. We focus on the two fundamental causal-inference tasks and causality-aware machine learning tasks. Limitations of current evaluation procedures are also discussed. We then examine popular causal inference tools/packages and conclude with primary challenges and opportunities for benchmarking causal learning algorithms in the era of big data. The survey seeks to bring to the forefront the urgency of developing publicly available benchmarks and consensus-building standards for causal learning evaluation with observational data. In doing so, we hope to broaden the discussions and facilitate collaboration to advance the innovation and application of causal learning.