 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Not to Propagate: Understanding Edge Uncertainty and Over-smoothing in Signed Graph Neural Networks
Aug 09, 2024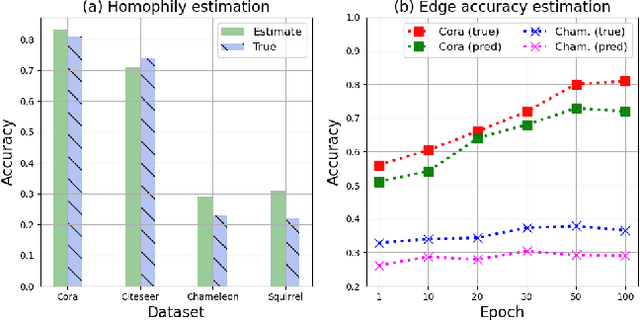
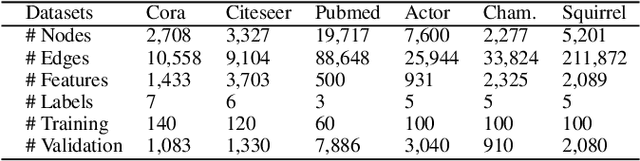
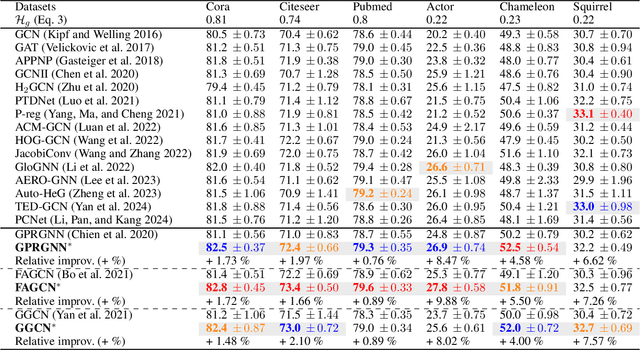
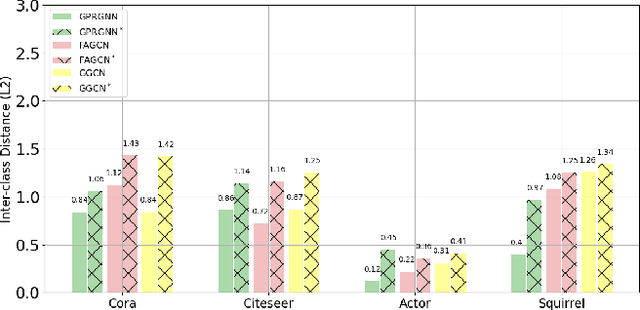
Traditional Graph Neural Networks (GNNs) rely on network homophily, which can lead to performance degradation due to over-smoothing in many real-world heterophily scenarios. Recent studies analyze the smoothing effect (separability) after message-passing (MP), depending on the expectation of node features. Regarding separability gain, they provided theoretical backgrounds on over-smoothing caused by various propagation schemes, including positive, signed, and blocked MPs. More recently, by extending these theorems, some works have suggested improvements in signed propagation under multiple classes. However, prior works assume that the error ratio of all propagation schemes is fixed, failing to investigate this phenomenon correctly. To solve this problem, we propose a novel method for estimating homophily and edge error ratio, integrated with dynamic selection between blocked and signed propagation during training. Our theoretical analysis, supported by extensive experiments, demonstrates that blocking MP can be more effective than signed propagation under high edge error ratios, improving the performance in both homophilic and heterophilic graphs.
Finding Heterophilic Neighbors via Confidence-based Subgraph Matching for Semi-supervised Node Classification
Feb 20, 2023Graph Neural Networks (GNNs) have proven to be powerful in many graph-based applications. However, they fail to generalize well under heterophilic setups, where neighbor nodes have different labels. To address this challenge, we employ a confidence ratio as a hyper-parameter, assuming that some of the edges are disassortative (heterophilic). Here, we propose a two-phased algorithm. Firstly, we determine edge coefficients through subgraph matching using a supplementary module. Then, we apply GNNs with a modified label propagation mechanism to utilize the edge coefficients effectively. Specifically, our supplementary module identifies a certain proportion of task-irrelevant edges based on a given confidence ratio. Using the remaining edges, we employ the widely used optimal transport to measure the similarity between two nodes with their subgraphs. Finally, using the coefficients as supplementary information on GNNs, we improve the label propagation mechanism which can prevent two nodes with smaller weights from being closer. The experiments on benchmark datasets show that our model alleviates over-smoothing and improves performance.
Is Signed Message Essential for Graph Neural Networks?
Jan 21, 2023



Message-passing Graph Neural Networks (GNNs), which collect information from adjacent nodes, achieve satisfying results on homophilic graphs. However, their performances are dismal in heterophilous graphs, and many researchers have proposed a plethora of schemes to solve this problem. Especially, flipping the sign of edges is rooted in a strong theoretical foundation, and attains significant performance enhancements. Nonetheless, previous analyses assume a binary class scenario and they may suffer from confined applicability. This paper extends the prior understandings to multi-class scenarios and points out two drawbacks: (1) the sign of multi-hop neighbors depends on the message propagation paths and may incur inconsistency, (2) it also increases the prediction uncertainty (e.g., conflict evidence) which can impede the stability of the algorithm. Based on the theoretical understanding, we introduce a novel strategy that is applicable to multi-class graphs. The proposed scheme combines confidence calibration to secure robustness while reducing uncertainty. We show the efficacy of our theorem through extensive experiments on six benchmark graph datasets.
Signed Directed Graph Contrastive Learning with Laplacian Augmentation
Jan 12, 2023



Graph contrastive learning has become a powerful technique for several graph mining tasks. It learns discriminative representation from different perspectives of augmented graphs. Ubiquitous in our daily life, singed-directed graphs are the most complex and tricky to analyze among various graph types. That is why singed-directed graph contrastive learning has not been studied much yet, while there are many contrastive studies for unsigned and undirected. Thus, this paper proposes a novel signed-directed graph contrastive learning, SDGCL. It makes two different structurally perturbed graph views and gets node representations via magnetic Laplacian perturbation. We use a node-level contrastive loss to maximize the mutual information between the two graph views. The model is jointly learned with contrastive and supervised objectives. The graph encoder of SDGCL does not depend on social theories or predefined assumptions. Therefore it does not require finding triads or selecting neighbors to aggregate. It leverages only the edge signs and directions via magnetic Laplacian. To the best of our knowledge, it is the first to introduce magnetic Laplacian perturbation and signed spectral graph contrastive learning. The superiority of the proposed model is demonstrated through exhaustive experiments on four real-world datasets. SDGCL shows better performance than other state-of-the-art on four evaluation metrics.
Flip Initial Features: Generalization of Neural Networks for Semi-supervised Node Classification
Dec 17, 2022Graph neural networks (GNNs) have been widely used under semi-supervised settings. Prior studies have mainly focused on finding appropriate graph filters (e.g., aggregation schemes) to generalize well for both homophilic and heterophilic graphs. Even though these approaches are essential and effective, they still suffer from the sparsity in initial node features inherent in the bag-of-words representation. Common in semi-supervised learning where the training samples often fail to cover the entire dimensions of graph filters (hyperplanes), this can precipitate over-fitting of specific dimensions in the first projection matrix. To deal with this problem, we suggest a simple and novel strategy; create additional space by flipping the initial features and hyperplane simultaneously. Training in both the original and in the flip space can provide precise updates of learnable parameters. To the best of our knowledge, this is the first attempt that effectively moderates the overfitting problem in GNN. Extensive experiments on real-world datasets demonstrate that the proposed technique improves the node classification accuracy up to 40.2 %
A Graph Convolution for Signed Directed Graphs
Aug 23, 2022
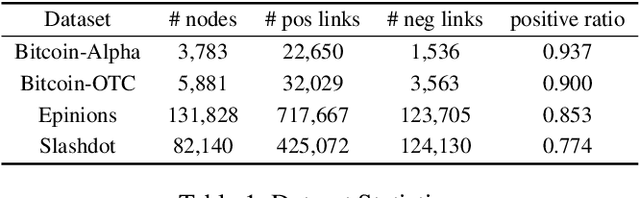

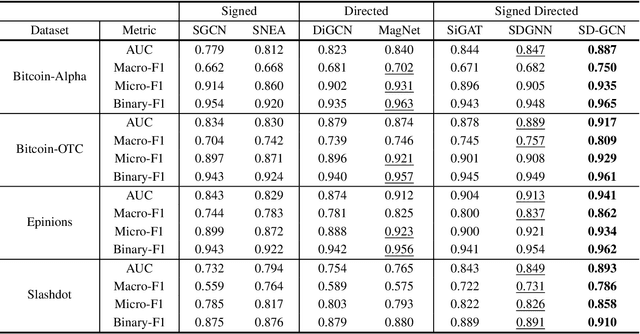
There are several types of graphs according to the nature of the data. Directed graphs have directions of links, and signed graphs have link types such as positive and negative. Signed directed graphs are the most complex and informative that have both. Graph convolutions for signed directed graphs have not been delivered much yet. Though many graph convolution studies have been provided, most are designed for undirected or unsigned. In this paper, we investigate a spectral graph convolution network for signed directed graphs. We propose a novel complex Hermitian adjacency matrix that encodes graph information via complex numbers. The complex numbers represent link direction, sign, and connectivity via the phases and magnitudes. Then, we define a magnetic Laplacian with the Hermitian matrix and prove its positive semidefinite property. Finally, we introduce Signed Directed Graph Convolution Network(SD-GCN). To the best of our knowledge, it is the first spectral convolution for graphs with signs. Moreover, unlike the existing convolutions designed for a specific graph type, the proposed model has generality that can be applied to any graphs, including undirected, directed, or signed. The performance of the proposed model was evaluated with four real-world graphs. It outperforms all the other state-of-the-art graph convolutions in the task of link sign prediction.
DaRE: A Cross-Domain Recommender System with Domain-aware Feature Extraction and Review Encoder
Oct 25, 2021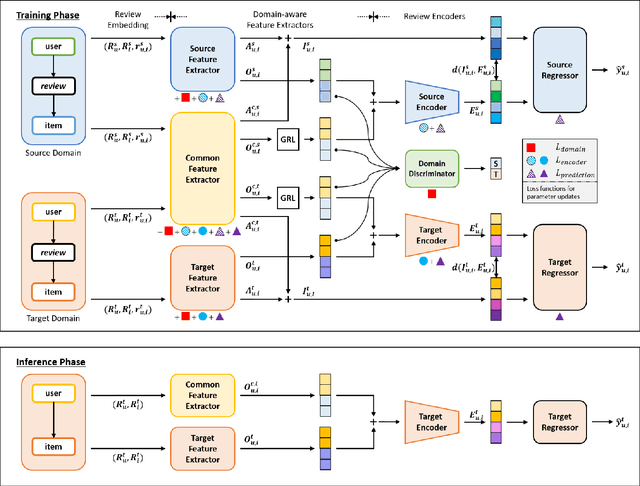

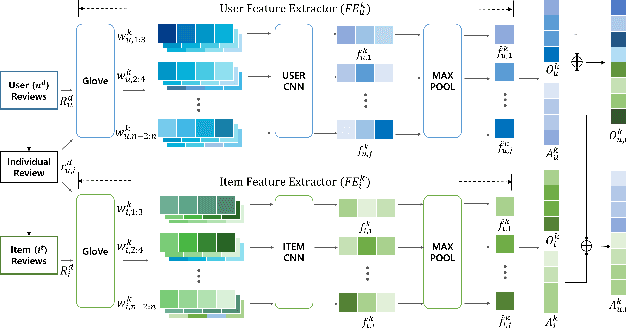
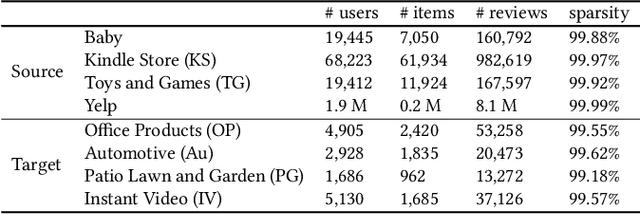
Recent advent in recommender systems, especially text-aided methods and CDR (Cross-Domain Recommendation) leads to promising results in solving data-sparsity and cold-start problems. Despite such progress, prior algorithms either require user overlapping or ignore domain-aware feature extraction. In addition, text-aided methods exceedingly emphasize aggregated documents and fail to capture the specifics embedded in individual reviews. To overcome such limitations, we propose a novel method, named DaRE (Domainaware Feature Extraction and Review Encoder), a comprehensive solution that consists of three key components; text-based representation learning, domain-aware feature extraction, and a review encoder. DaRE debilitate noises by separating domain-invariant features from domain-specific features through selective adversarial training. DaRE extracts features from aggregated documents, and the review encoder fine-tunes the representations by aligning them with the features extracted from individual reviews. Experiments on four real-world datasets show the superiority of DaRE over state-ofthe-art single-domain and cross-domain methodologies, achieving 9.2 % and 3.6 % improvements, respectively. We upload our implementations (https://anonymous.4open.science/r/DaRE-9CC9/) for a reproducibility